Nell’Intelligenza Artificiale, uno dei limiti più persistenti e frustranti dell’apprendimento profondo è il fenomeno dell'”oblio catastrofico”: la tendenza di un modello di AI a dimenticare rapidamente le informazioni apprese in precedenza non appena gli viene chiesto di assimilarne di nuove. Questo difetto fondamentale ha rappresentato una barriera significativa alla realizzazione del concetto di apprendimento continuo, essenziale per creare sistemi di AI veramente adattivi e resilienti.
Google, presentando il suo nuovo paradigma di “Nested Learning” (Apprendimento Annidato) alla conferenza NeurIPS 2025, propone una soluzione radicale a questo problema, ispirandosi direttamente alla struttura gerarchica e ai meccanismi di memoria del cervello umano.
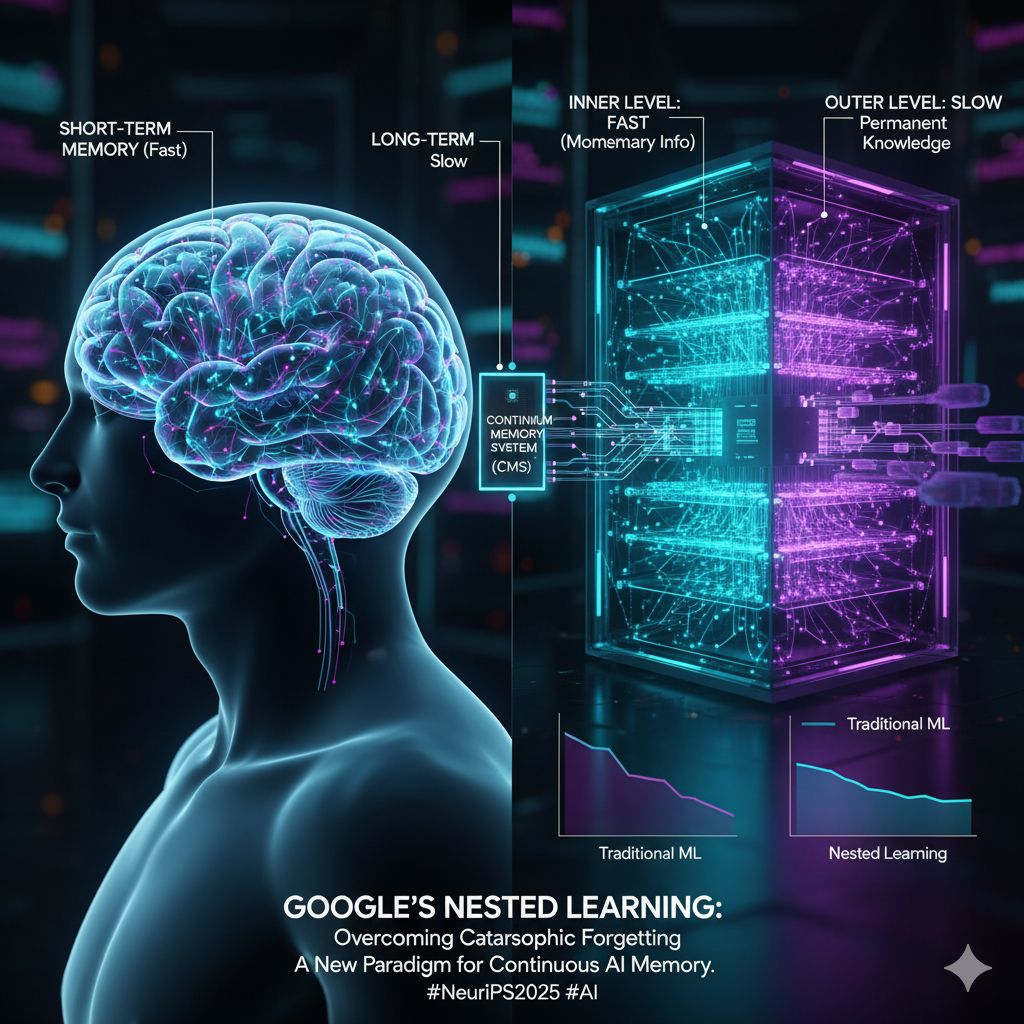
L’approccio convenzionale all’addestramento dei modelli di AI su larga scala li tratta come un’unica grande rete che viene aggiornata simultaneamente. Il Nested Learning di Google abbandona questa visione monolitica e considera invece il modello come una struttura composta da più parti interconnesse, proprio come le diverse aree del cervello che gestiscono memorie a breve e lungo termine.
Il cuore di questa architettura complessa e flessibile è la suddivisione del modello in più livelli, ognuno dei quali è aggiornato a una velocità diversa:
- Livello Interno (Veloce): Contiene i parametri che cambiano rapidamente, essenziali per assimilare informazioni immediate, momentanee o a breve termine.
- Livello Esterno (Lento): Contiene i parametri che cambiano lentamente, cruciali per consolidare conoscenze strutturali, tendenze a lungo termine e memorie permanenti.
Grazie all’apprendimento a queste velocità multiple e separate, il modello è in grado di comprendere simultaneamente una vasta gamma di informazioni su diverse scale temporali, gestendo in modo efficiente sia i cambiamenti transitori sia le conoscenze fondamentali.
A rendere possibile questa architettura è il Continuum Memory System (CMS), un modulo di apprendimento neurale costruito su questa struttura annidata. Il CMS funziona memorizzando gli input, i gradienti e i cambiamenti di stato osservati a ogni livello, compressi in un contesto unico e coerente. Questa memorizzazione stratificata consente al modello di creare ricordi proprio come fa il cervello umano, costruendoli in più fasi e mantenendo l’accesso sia ai dettagli recenti che ai modelli stabili del passato.
L’innovazione si estende anche alla comprensione degli ottimizzatori convenzionali, che Google ridefinisce non più solo come strumenti per calcoli matematici, ma come vere e proprie “memorie associative” – dispositivi che memorizzano e collegano le informazioni. Ad esempio, il comune metodo del momento viene interpretato come una semplice struttura di memoria lineare che registra i valori del gradiente passato.
Estendendo questo concetto, i ricercatori propongono il “Deep Momentum Gradient Descent”. Questo nuovo metodo rappresenta lo stato del momento come una memoria basata su una rete neurale a sé stante. Ciò consente una registrazione più efficace delle variazioni di gradiente all’interno di uno spazio di memoria limitato e un utilizzo più efficiente di queste variazioni durante il processo di apprendimento, contribuendo a un apprendimento più profondo e meno soggetto all’oblio.
Per dimostrare l’efficacia del Nested Learning in un contesto applicativo, Google ha sviluppato un nuovo sistema chiamato HOPE (Self-modifying Sequence Model). HOPE rappresenta un’evoluzione del modello di memoria a lungo termine Titans ed è un modello di sequenza capace di adattarsi ed evolvere attraverso l’autoapprendimento.
Sfruttando il CMS, HOPE funziona memorizzando rapidamente le nuove informazioni in alcune aree (livello interno) e, al contempo, costruendo lentamente modelli a lungo termine in altre (livello esterno). Grazie a questa dinamica, HOPE è diventato un sistema in grado di comprendere il flow delle informazioni a lungo termine e, contemporaneamente, di reagire e adattarsi ai dati a breve termine, permettendo un apprendimento e un adattamento continui.
Nei benchmark di modellazione del linguaggio e di ragionamento basato sul buon senso (utilizzando dataset come LAMBADA, PIQA, HellaSwag e ARC Challenge), HOPE ha dimostrato prestazioni superiori rispetto a sistemi esistenti come Transformer++ e RetNet.
I ricercatori sottolineano che il Nested Learning non è una semplice modifica strutturale, ma un tentativo di ridefinire i principi matematici fondamentali dell’apprendimento profondo. Ripensare le reti neurali come strutture gerarchiche che comprimono e apprendono le informazioni è vista come una chiave fondamentale per comprendere il complesso fenomeno dell’apprendimento contestuale che si manifesta nei Modelli Linguistici di Grande Dimensione (LLM), aprendo la strada a un’AI meno “amnesica” e più simile all’intelligenza umana.