L’architettura Parcae, sviluppata da ricercatori della University of California San Diego in collaborazione con Together AI, introduce un cambiamento significativo rispetto ai paradigmi consolidati dei Transformer tradizionali. Il punto centrale di questa innovazione risiede nella capacità di migliorare le prestazioni senza incrementare il numero di parametri o la memoria richiesta, intervenendo invece sulla dimensione computazionale del processo inferenziale.
I modelli Transformer convenzionali si basano su una struttura a profondità fissa, in cui l’informazione attraversa sequenzialmente una serie di livelli, ciascuno con pesi distinti. Questo approccio implica che l’aumento delle prestazioni sia generalmente ottenuto attraverso l’espansione della rete, aumentando il numero di parametri, la quantità di dati di addestramento o la potenza computazionale complessiva. Parcae introduce un’alternativa a questo schema, adottando una struttura a ciclo, in cui lo stesso blocco computazionale viene riutilizzato più volte durante l’elaborazione.
Questo meccanismo, definito profondità ricorrente, consente al modello di eseguire iterazioni successive sullo stesso stato latente, raffinando progressivamente la rappresentazione interna senza aumentare la dimensione del modello. Dal punto di vista ingegneristico, ciò si traduce in un aumento della capacità computazionale a parità di memoria, rendendo l’architettura particolarmente adatta a contesti in cui le risorse hardware sono limitate, come dispositivi mobili o ambienti edge.
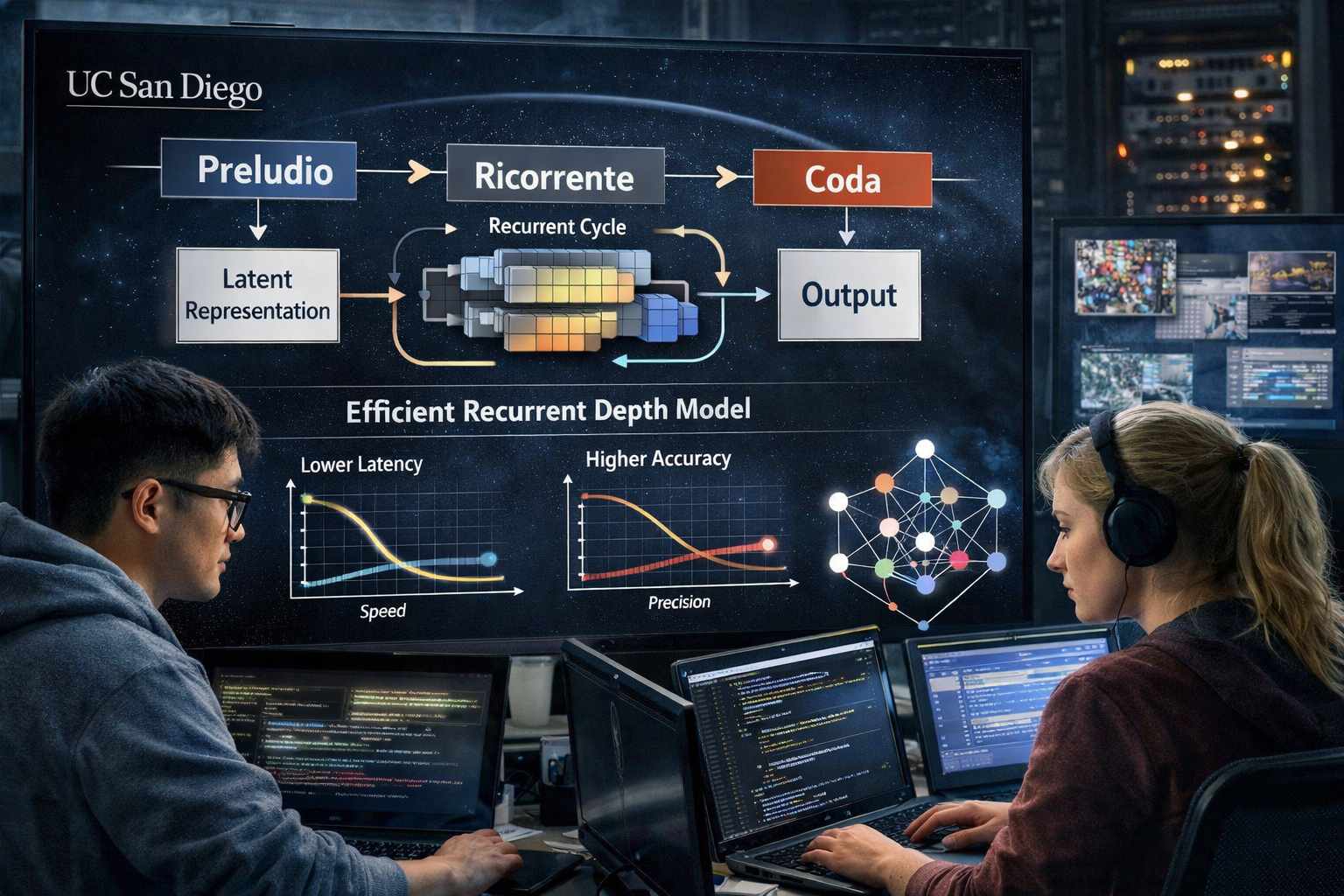
La struttura di Parcae è organizzata in tre fasi principali, denominate Preludio, Ricorrente e Coda. Nella fase iniziale, l’input viene trasformato in una rappresentazione latente compatta. Successivamente, questa rappresentazione viene aggiornata iterativamente all’interno del blocco ricorrente, che costituisce il nucleo del modello. Infine, nella fase di uscita, la rappresentazione finale viene convertita nel risultato desiderato. Un elemento chiave di questo processo è la reiniezione dell’input a ogni iterazione, una tecnica che consente di preservare l’informazione originale e prevenire la degradazione semantica nel corso delle iterazioni successive.
Uno degli aspetti più innovativi dell’architettura è la possibilità di regolare dinamicamente il numero di iterazioni durante la fase di inferenza. Questo introduce un nuovo grado di libertà nel bilanciamento tra prestazioni e costo computazionale. In scenari che richiedono alta precisione, il modello può eseguire un numero maggiore di iterazioni, migliorando la qualità dell’output. Al contrario, in contesti in cui la latenza o il consumo energetico sono critici, il numero di iterazioni può essere ridotto, ottenendo risposte più rapide a discapito di una minore accuratezza. Questo comportamento adattivo rappresenta una forma di scalabilità temporale, in cui il tempo di calcolo diventa una variabile controllabile, analogamente alla dimensione del modello o alla quantità di dati. Tale caratteristica è particolarmente rilevante per applicazioni on-device, dove la capacità di modulare il carico computazionale in tempo reale può determinare l’effettiva utilizzabilità del sistema.
Storicamente, architetture basate su profondità ricorrente erano già state esplorate, ad esempio nei modelli di tipo RDM. Tuttavia, queste soluzioni soffrivano di problemi di stabilità durante l’addestramento, legati alla natura iterativa del processo. Fenomeni come l’esplosione dello stato interno o la divergenza della funzione di perdita rendevano difficile l’ottimizzazione del modello. Il contributo principale di Parcae consiste nell’aver reinterpretato questi problemi attraverso la lente dei sistemi dinamici non lineari invarianti nel tempo, introducendo vincoli strutturali che garantiscono la stabilità del processo. In particolare, l’adozione di parametrizzazioni diagonali negative e tecniche di discretizzazione consente di controllare l’evoluzione dello stato interno, evitando comportamenti instabili. Questo approccio integra principi matematici nella progettazione dell’architettura, trasformando un problema empirico in una questione formalmente trattabile.
I risultati sperimentali evidenziano miglioramenti significativi rispetto ai Transformer tradizionali. A parità di condizioni di addestramento, il modello ha mostrato una riduzione della perplessità di validazione fino al 6,3% e un miglioramento delle prestazioni su dataset come WikiText fino al 9,1%. Anche nei benchmark zero-shot si registrano incrementi misurabili, indicando una maggiore capacità di generalizzazione. Un dato particolarmente rilevante riguarda l’efficienza parametrica. Un modello Parcae con circa 770 milioni di parametri è in grado di raggiungere prestazioni comparabili a quelle di un Transformer con 1,3 miliardi di parametri. Questo risultato suggerisce che la profondità iterativa può compensare la riduzione della dimensione del modello, offrendo una via alternativa alla scalabilità basata sull’espansione.
Un ulteriore contributo teorico del lavoro è l’introduzione di una legge di scala a tre variabili, che estende i modelli tradizionali basati su parametri e dati di addestramento. In questo nuovo framework, il numero di iterazioni diventa una terza variabile fondamentale, e il modello dimostra che esiste una relazione ottimale tra queste tre dimensioni. L’aumento delle risorse computazionali richiede un bilanciamento preciso tra quantità di dati e profondità iterativa, suggerendo nuove linee guida per la progettazione di modelli efficienti.
Nonostante i vantaggi, l’aumento indefinito del numero di iterazioni non garantisce un miglioramento continuo delle prestazioni. I risultati indicano che esiste un limite superiore determinato dalla profondità media utilizzata durante l’addestramento. Questo implica che la fase di training rimane cruciale nel definire il potenziale massimo del modello, e che l’inferenza non può compensare completamente eventuali carenze strutturali.