Mentre l’industria dell’intelligenza artificiale continua a investire miliardi di dollari nell’espansione delle infrastrutture di calcolo e nell’aumento delle dimensioni dei modelli, Sapient Intelligence — azienda con sede a Singapore — ha presentato HRM-Text, un language model da 1 miliardo di parametri che sfida apertamente il paradigma dominante del “più grande è meglio”.
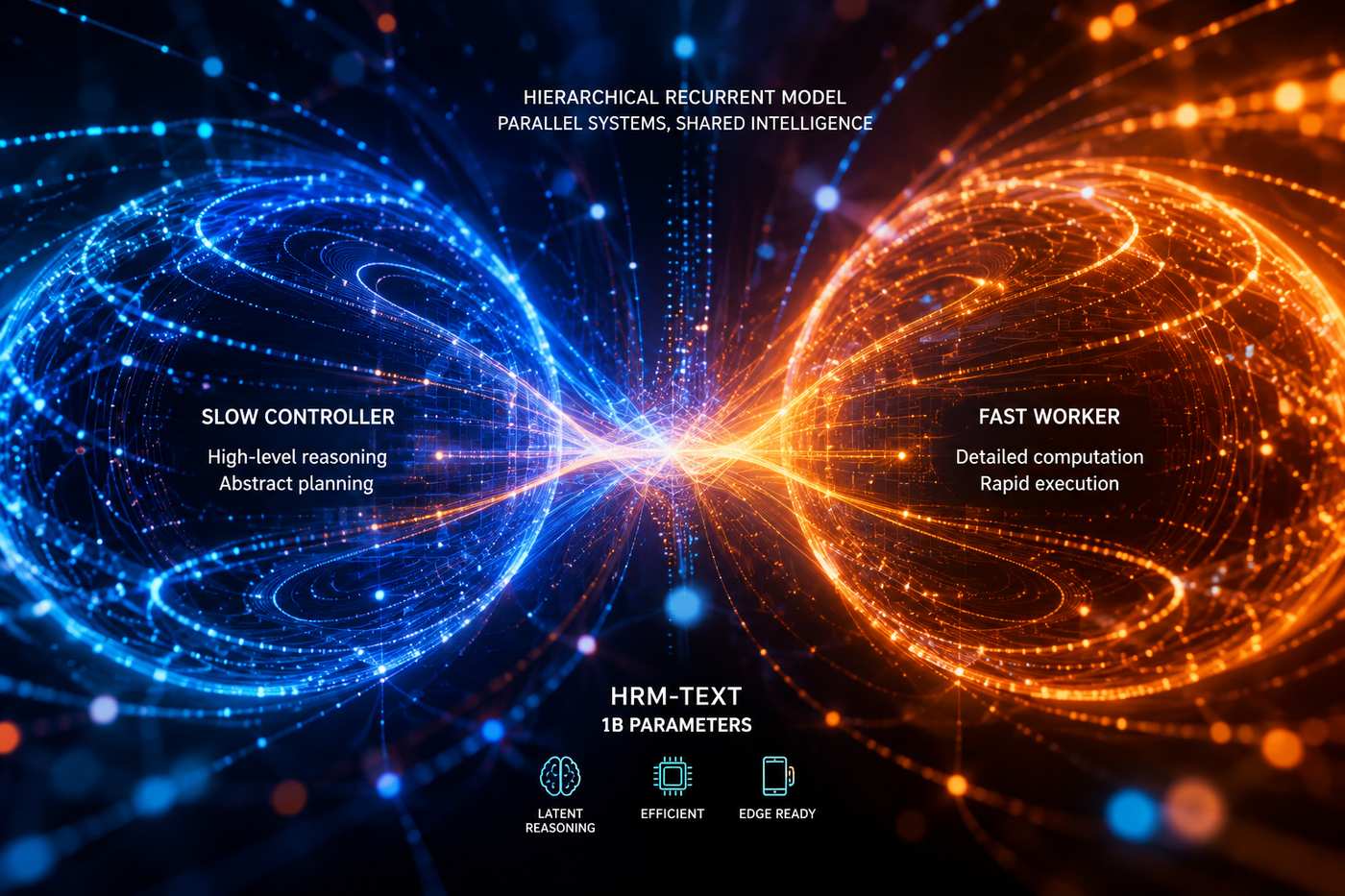
Il cuore dell’approccio è un’architettura denominata Hierarchical Recurrent Model, costruita attorno a due sistemi distinti che operano in parallelo e si influenzano reciprocamente prima ancora che venga generato qualsiasi output. Il primo è un livello “slow controller”, responsabile della pianificazione astratta e del ragionamento di alto livello. Il secondo è un livello “fast worker”, incaricato delle computazioni più dettagliate e operative. Questa separazione gerarchica non è casuale: riprende direttamente come la neuroscienza descrive il funzionamento del cervello umano, dove processi cognitivi lenti e deliberati coesistono con elaborazioni veloci e automatiche, ognuno con il proprio ritmo e la propria funzione.
Ciò che distingue HRM-Text dalla grande maggioranza dei modelli attualmente in circolazione è che il ragionamento avviene prevalentemente nello spazio latente, in modo implicito e interno, prima che il modello produca una risposta visibile. Questo si differenzia dai metodi di chain-of-thought classici, dove il processo di ragionamento viene esplicitato in sequenze di testo intermedie — approccio utile ma costoso in termini di latenza e lunghezza del contesto. In HRM-Text, la riflessione multi-step è incorporata direttamente nella dinamica ricorrente dell’architettura, non delegata a token di testo aggiuntivi.
I benchmark pubblicati dal team di ricerca parlano di 56,2% sul dataset MATH, 81,9% su ARC-Challenge, 82,2% su DROP e 60,7% su MMLU. Numeri che, pur non avvicinandosi ai modelli frontier di dimensioni molto superiori, risultano significativi considerando che HRM-Text è stato addestrato in circa un giorno, su 16 GPU distribuite su due macchine, con un costo totale di training stimato attorno ai 1.000 dollari. Il confronto con i budget di addestramento dei modelli di punta — che in alcuni casi superano centinaia di milioni di dollari — rende la proporzione particolarmente eloquente.
Sul fronte del deployment, il modello quantizzato in int4 occupa circa 0,6 GiB di memoria, rendendolo teoricamente utilizzabile su smartphone e dispositivi edge senza dipendenza da infrastrutture cloud. Questo aspetto apre scenari concreti per applicazioni in contesti dove la privacy dei dati, la latenza di rete o la disponibilità di connettività sono vincoli reali: inferenza offline, sistemi embedded, edge computing industriale.
La composizione del team di ricerca contribuisce a contestualizzare le ambizioni del progetto: Sapient Intelligence include ricercatori con esperienze pregresse in DeepMind, DeepSeek e xAI, oltre a profili accademici provenienti da MIT, Carnegie Mellon, Tsinghua University e University of Cambridge. Versioni precedenti dell’architettura HRM avevano già suscitato interesse nella comunità di ricerca per la capacità di ottenere prestazioni di ragionamento competitive con parametri notevolmente ridotti rispetto ai transformer convenzionali.
Il lancio di HRM-Text si inserisce in un momento in cui diversi indicatori strutturali del settore stanno mettendo sotto pressione la logica della scaling law pura: carenze di GPU, colli di bottiglia energetici, costi di inferenza in crescita e rendimenti decrescenti sull’aumento dei dati di addestramento stanno spingendo una parte della comunità di ricerca a esplorare alternative architetturali più radicali. L’intera codebase e i pesi del modello sono stati rilasciati open source su GitHub.