L’evoluzione dei sistemi agentic AI sta mettendo sotto pressione le architetture Retrieval-Augmented Generation tradizionali, nate originariamente per supportare interazioni umane episodiche e non workflow autonomi persistenti. Nei deployment enterprise più avanzati, il modello classico basato su query, retrieval vettoriale e generazione finale sta mostrando limiti evidenti quando viene applicato ad agenti software che devono operare continuativamente, coordinare task multi-step e mantenere stato operativo nel tempo.
Il problema principale è che il RAG tradizionale è stato progettato per recuperare informazioni rilevanti a partire da singole richieste utente, utilizzando chunk semantici recuperati tramite similarity search. In ambienti agentic enterprise, però, gli agenti non eseguono una sola interrogazione: pianificano, iterano, richiamano strumenti esterni, verificano risultati intermedi e navigano continuamente tra sorgenti informative differenti. Questo genera cicli di retrieval ripetuti che aumentano drasticamente costi computazionali, latenza e instabilità operativa.
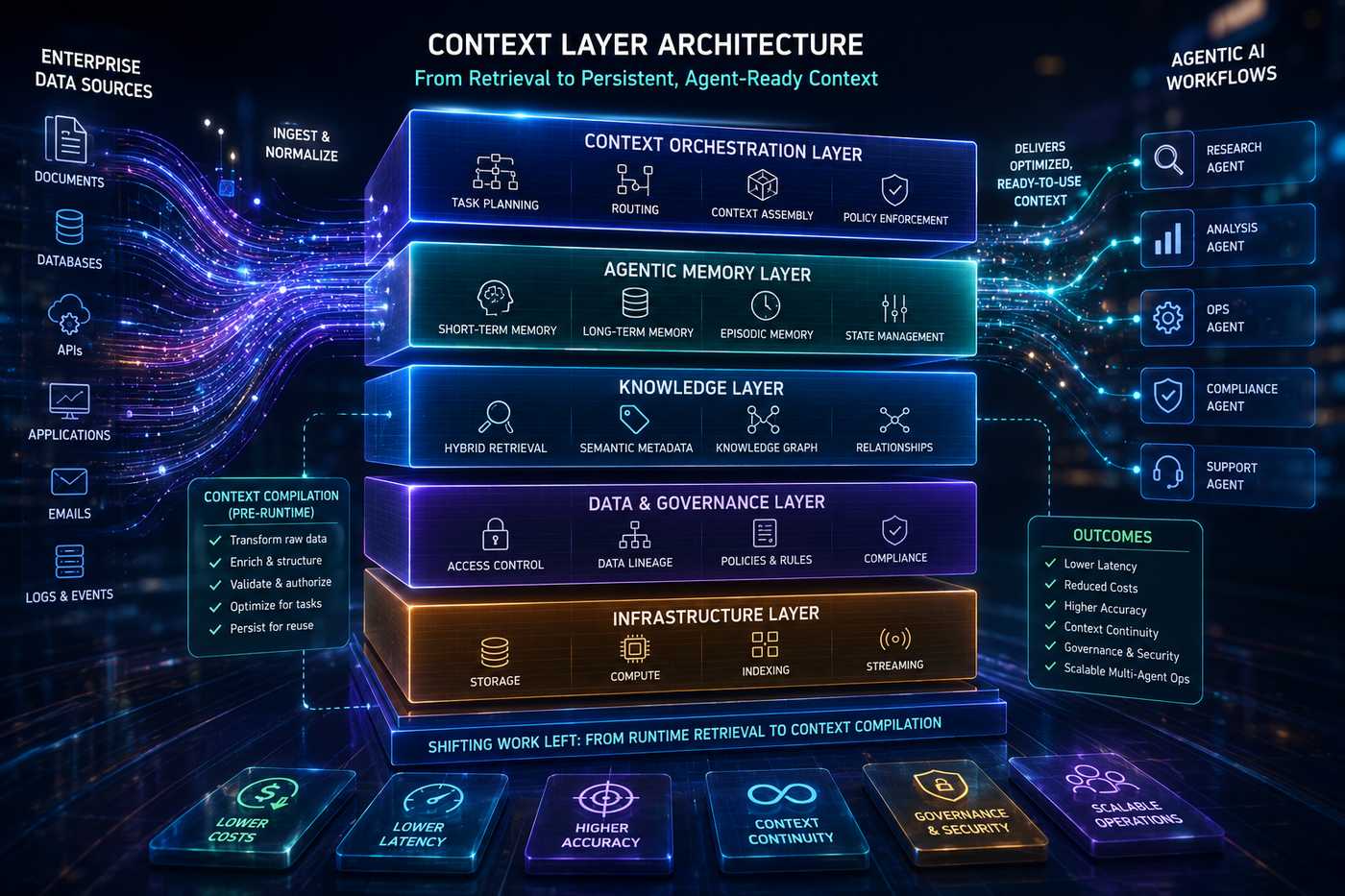
Per risolvere questi limiti sta emergendo il concetto di “context architecture” o “context layer”, un livello infrastrutturale che non si limita più a recuperare documenti, ma costruisce contesti operativi persistenti, strutturati e riutilizzabili per gli agenti AI. In questo paradigma, parte del lavoro di ragionamento e organizzazione della conoscenza viene spostato dalla fase di inferenza runtime a una fase preventiva di compilazione, trasformando dati grezzi in artefatti contestuali già ottimizzati per task specifici.
Questo significa introdurre knowledge layer persistenti che integrano retrieval ibrido, memoria agentica, metadata semantici, knowledge graph e sistemi di policy enforcement direttamente nel flusso operativo degli agenti. L’obiettivo non è più soltanto trovare documenti “semanticamente vicini”, ma fornire contesto computazionale già validato, autorizzato e coerente con il task corrente.
Uno degli aspetti più critici emersi nei deployment enterprise riguarda infatti la gestione del contesto su larga scala. Con l’aumento del numero di agenti, strumenti e sorgenti dati, i modelli iniziano a soffrire di fenomeni definiti “context rot”, nei quali grandi volumi di informazioni irrilevanti o ridondanti degradano precisione, reasoning e capacità decisionale. Questo problema è particolarmente evidente negli ambienti multi-agent, dove ogni agente accumula memoria operativa e cronologia contestuale differenti.
La risposta del settore sta quindi convergendo verso architetture contestuali dinamiche in cui il retrieval diventa soltanto uno dei componenti della pipeline. Sistemi di contextual memory, orchestration layer e policy-aware retrieval stanno assumendo un ruolo centrale perché permettono agli agenti di mantenere continuità operativa, isolamento multi-tenant e governance dei dati senza dover rieseguire continuamente retrieval completi su vector store generalisti.
Anche il mercato infrastrutturale sta cambiando rapidamente. I vector database standalone stanno perdendo centralità a favore di piattaforme ibride che combinano ricerca semantica, query strutturate, streaming real-time e gestione del contesto persistente. Secondo diversi segnali emersi nel settore enterprise AI, le aziende stanno iniziando a considerare il “context engineering” come una disciplina separata rispetto al semplice prompt engineering o retrieval engineering, con focus specifico su isolamento del contesto, provenienza dei dati, governance e ottimizzazione della memoria agentica.