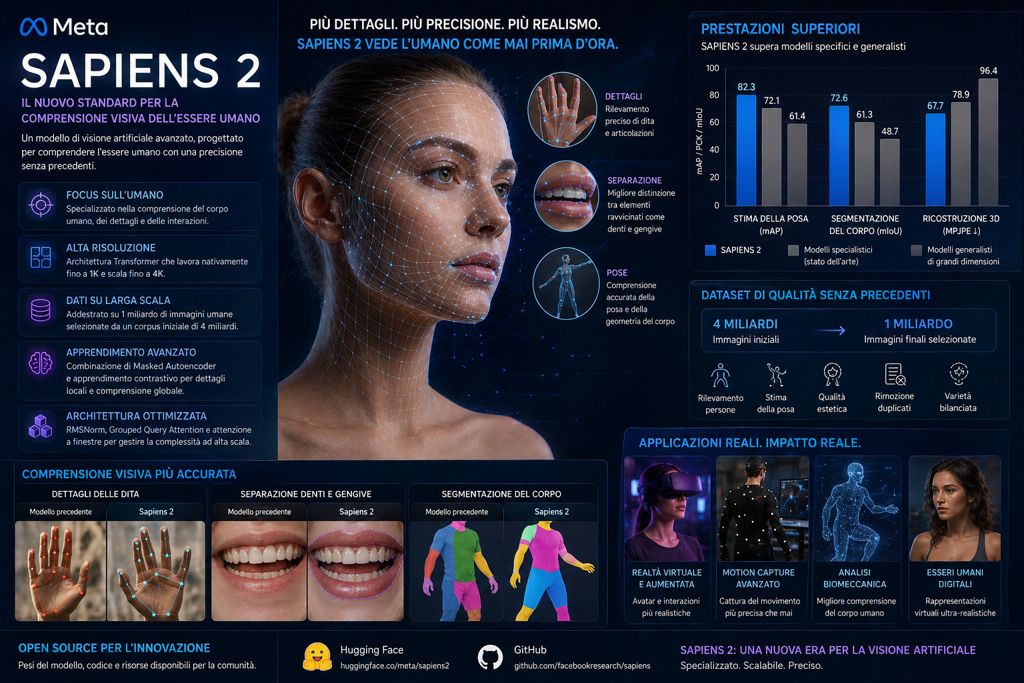
Nel campo della visione artificiale, pochi problemi si sono rivelati complessi quanto la comprensione accurata del corpo umano. Nonostante i progressi degli ultimi anni, i sistemi continuano a mostrare limiti evidenti: difficoltà nel distinguere dettagli sottili come le dita, errori nella separazione di elementi ravvicinati come denti e gengive, oppure interpretazioni imprecise delle superfici e delle pose. È proprio su queste criticità che si concentra il nuovo modello presentato da Meta, chiamato Sapiens 2, un sistema progettato per portare la percezione visiva incentrata sull’uomo a un livello superiore.
Sapiens 2 nasce come un modello di base, cioè una piattaforma generale su cui costruire applicazioni diverse, ma con una specializzazione molto precisa: la comprensione degli esseri umani nelle immagini. Questa scelta rappresenta già un cambio di prospettiva significativo rispetto ai modelli di visione generalisti, che cercano di interpretare qualsiasi tipo di scena. Qui, invece, l’obiettivo è approfondire un dominio specifico, spingendo al massimo la qualità e la precisione.
Dal punto di vista tecnico, il modello utilizza un’architettura Transformer ad alta risoluzione, capace di lavorare nativamente su immagini fino a 1K e di scalare fino a 4K grazie a una struttura gerarchica. Questo aspetto è tutt’altro che marginale. La capacità di gestire immagini ad altissima risoluzione consente di catturare dettagli visivi che spesso sfuggono ai modelli tradizionali, migliorando la qualità delle analisi in modo sostanziale.
Alla base di questa capacità c’è anche un lavoro imponente sui dati. Il modello è stato addestrato su un dataset finale di un miliardo di immagini umane, selezionate e raffinate a partire da un corpus iniziale di quattro miliardi. Questo processo non si è limitato a una semplice raccolta, ma ha incluso fasi avanzate di filtraggio, come il rilevamento automatico delle persone, la stima della posa, la valutazione della qualità estetica e la rimozione dei duplicati. Il risultato è un dataset bilanciato, progettato per rappresentare una grande varietà di condizioni reali, tra cui pose, illuminazione, abbigliamento ed etnie.
Questo aspetto è particolarmente rilevante perché la generalizzazione dei modelli di visione dipende fortemente dalla qualità e dalla diversità dei dati. In passato, molti sistemi hanno mostrato limiti proprio a causa di dataset sbilanciati o poco rappresentativi. Sapiens 2 prova a superare questo problema costruendo una base dati più ampia e più curata.
L’innovazione più interessante, però, riguarda il metodo di apprendimento. I modelli precedenti si basavano principalmente su tecniche come il Masked Autoencoder, che consiste nel nascondere parti dell’immagine e addestrare il sistema a ricostruirle. Questo approccio è efficace per apprendere strutture visive, ma tende a privilegiare alcuni aspetti a discapito di altri. Sapiens 2 introduce una combinazione tra questo metodo e l’apprendimento contrastivo, permettendo al modello di sviluppare contemporaneamente una comprensione dei dettagli locali e delle relazioni semantiche globali.
In pratica, il sistema non si limita a “riempire i vuoti”, ma impara anche a distinguere e confrontare elementi visivi, migliorando la capacità di interpretare il contesto. Questo si traduce in una maggiore precisione nella rappresentazione di caratteristiche complesse come la tonalità della pelle o le condizioni di illuminazione, riducendo al minimo le distorsioni cromatiche che spesso affliggono i modelli di visione artificiale.
Anche l’architettura è stata ottimizzata per gestire la complessità dell’addestramento su larga scala. Tecniche avanzate come RMSNorm, Grouped Query Attention e la normalizzazione QK contribuiscono a migliorare la stabilità e l’efficienza del modello. In particolare, l’utilizzo di meccanismi di attenzione basati su finestre consente di elaborare immagini ad altissima risoluzione senza compromettere le prestazioni, un equilibrio difficile da ottenere in sistemi di questa scala.
I risultati ottenuti riflettono chiaramente questi miglioramenti. Sapiens 2 ha mostrato prestazioni superiori in diverse attività chiave, tra cui la stima della posa, la segmentazione del corpo e la ricostruzione tridimensionale. Nella stima della posa, ad esempio, il modello ha raggiunto un punteggio di 82,3 mAP, migliorando significativamente rispetto alla generazione precedente. Nella segmentazione, i guadagni sono ancora più evidenti, con incrementi sostanziali nella qualità delle suddivisioni del corpo.
Un aspetto particolarmente interessante è che, pur essendo specializzato, Sapiens 2 riesce a superare anche modelli generalisti di grandi dimensioni. Questo risultato suggerisce una tendenza sempre più evidente nel settore: la specializzazione può essere più efficace della generalizzazione, soprattutto quando si lavora su problemi complessi e ben definiti.
Le implicazioni di questo sviluppo sono ampie. Migliorare la comprensione visiva del corpo umano significa aprire nuove possibilità in ambiti come la realtà aumentata e la realtà virtuale, dove la rappresentazione accurata delle persone è fondamentale. Ma non solo. Applicazioni come gli esseri umani digitali, il motion capture avanzato e l’analisi biomeccanica possono beneficiare direttamente di modelli più precisi e affidabili.
Allo stesso tempo, il fatto che Meta abbia reso disponibili i pesi del modello e il codice su piattaforme come Hugging Face e GitHub indica una volontà di stimolare l’adozione e lo sviluppo da parte della comunità. Questo potrebbe accelerare ulteriormente l’innovazione, permettendo a ricercatori e aziende di costruire applicazioni basate su questa nuova generazione di modelli.
In definitiva, Sapiens 2 rappresenta un passo importante verso una visione artificiale più precisa, più specializzata e più vicina alla complessità del mondo reale. Non è semplicemente un miglioramento incrementale, ma un esempio di come l’AI possa evolversi attraverso una combinazione di dati migliori, architetture più sofisticate e strategie di apprendimento più intelligenti. E in un campo come quello della comprensione umana, dove ogni dettaglio conta, questo tipo di progresso può fare la differenza.