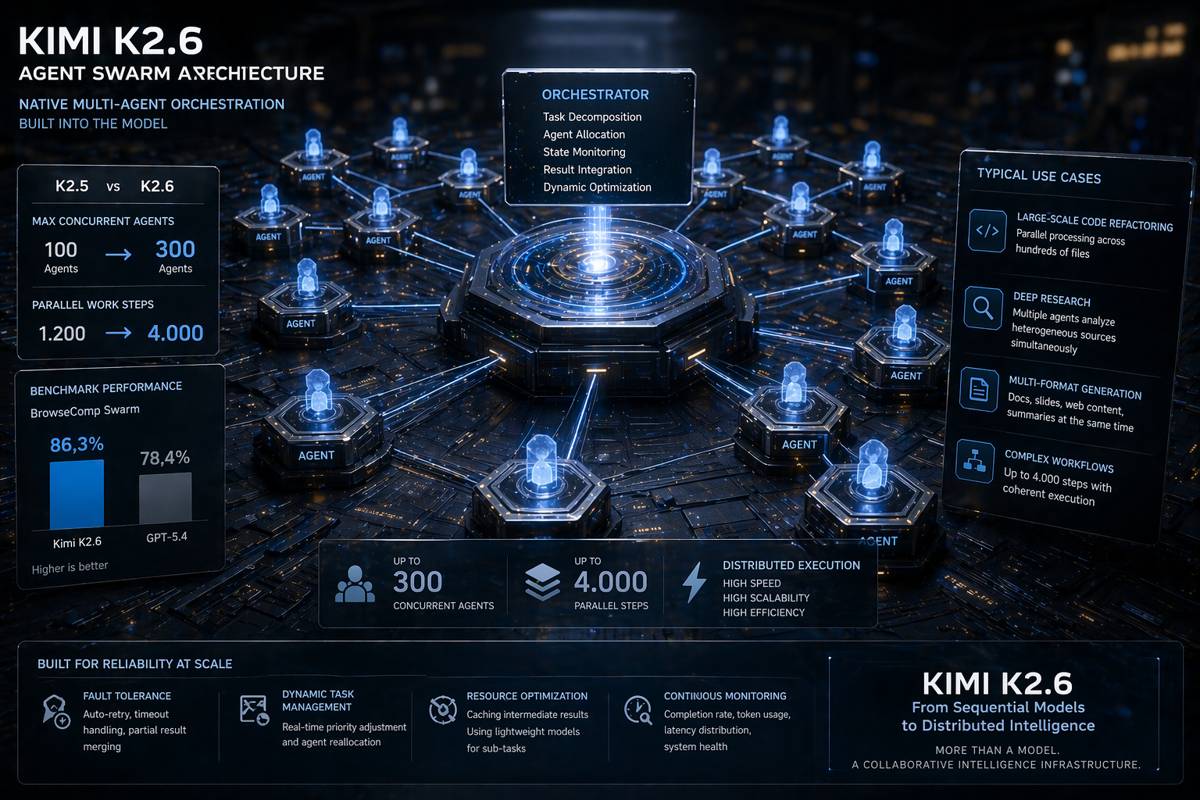
Il paradigma introdotto da Moonshot AI con il rilascio di Kimi K2.6 è un’evoluzione strutturale nel modo in cui i modelli di intelligenza artificiale affrontano l’esecuzione di compiti complessi. L’elemento centrale non è un semplice incremento delle capacità del modello, ma l’integrazione nativa di una logica di orchestrazione multi-agente direttamente all’interno dell’architettura del sistema. Questo approccio, definito “Agent Swarm”, supera i limiti del modello sequenziale tradizionale, in cui un singolo modello elabora le istruzioni passo dopo passo, introducendo invece una struttura distribuita capace di operare in parallelo su larga scala.
Nel modello sequenziale classico, ogni fase del processo dipende dall’esecuzione della precedente, creando un collo di bottiglia che limita sia la velocità sia la scalabilità. Kimi K2.6 rompe questa linearità attraverso un sistema in cui un orchestratore centrale analizza il task complessivo, lo decompone in sottocompiti granulari e assegna ciascuna unità operativa a sub-agenti specializzati. Questi agenti lavorano in modo indipendente, eseguendo operazioni simultanee fino a un massimo di 300 istanze attive e gestendo fino a 4.000 fasi di lavoro in parallelo. Il risultato è un sistema che si avvicina più a un’infrastruttura di calcolo distribuito che a un modello linguistico tradizionale.
La differenza più rilevante rispetto agli approcci precedenti risiede nel fatto che questa logica di orchestrazione non è implementata tramite framework esterni, ma è incorporata direttamente nel modello. In sistemi precedenti, la gestione multi-agente richiedeva layer aggiuntivi, spesso sviluppati ad hoc, che introducevano complessità e latenza. In Kimi K2.6, invece, il modello stesso gestisce l’intero ciclo operativo: dalla scomposizione del problema alla distribuzione dei compiti, dal monitoraggio dello stato degli agenti fino all’integrazione finale dei risultati. Questo consente una riduzione significativa dell’overhead e una maggiore coerenza tra le diverse fasi del processo.
Il confronto con la versione precedente, K2.5, evidenzia chiaramente l’evoluzione architetturale. Il limite di agenti simultanei è stato triplicato, passando da 100 a 300, ma l’aspetto più importante è il miglioramento nella gestione dinamica dei task e degli errori. Il sistema non si limita a distribuire il lavoro, ma è in grado di adattare in tempo reale la struttura dello sciame, ridefinendo priorità, riassegnando compiti e gestendo eventuali fallimenti senza compromettere l’intero processo.
Questa capacità si riflette direttamente nei benchmark. Nel test BrowseComp Swarm, progettato per valutare scenari di navigazione e aggregazione informativa distribuita, Kimi K2.6 raggiunge un punteggio dell’86,3%, superando modelli come GPT-5.4, fermo al 78,4%. Il dato non è attribuibile esclusivamente alla qualità del modello base, ma alla sua capacità di coordinare efficacemente più agenti, ottimizzando la collaborazione e riducendo i tempi di esecuzione complessivi. In questo contesto, la performance non è più una funzione lineare delle capacità del singolo modello, ma il risultato emergente di un sistema cooperativo.
L’architettura Agent Swarm mostra il massimo vantaggio in scenari ad alta parallelizzabilità. Nel refactoring di codice su larga scala, ad esempio, il sistema può suddividere il lavoro per file o moduli, assegnando a ciascun agente una porzione indipendente del codice. Questo consente di eseguire modifiche simultanee su centinaia di componenti, riducendo drasticamente i tempi rispetto a un approccio sequenziale. Analogamente, nei processi di ricerca, diversi agenti possono analizzare fonti eterogenee in parallelo, contribuendo alla generazione di un report unificato con una profondità informativa maggiore.
Un ulteriore caso d’uso significativo è la generazione multiformato. Partendo da un singolo input, il sistema può produrre simultaneamente documentazione tecnica, presentazioni, contenuti web e schede sintetiche, assegnando a ciascun agente un formato specifico. Questo tipo di workflow evidenzia come l’Agent Swarm non sia solo un’accelerazione del processo, ma una trasformazione qualitativa nella gestione della produzione di contenuti.
Tuttavia, l’aumento del parallelismo introduce complessità nuove, soprattutto in termini di gestione delle risorse. Quando centinaia di agenti operano simultaneamente, il consumo di token può crescere in modo esponenziale, rendendo il costo per singola esecuzione un fattore critico. In scenari ad alta intensità, il costo complessivo può raggiungere diversi dollari per singola operazione, rendendo necessarie strategie di ottimizzazione avanzate. Tra queste, il caching dei risultati intermedi consente di evitare ricalcoli ridondanti, mentre l’utilizzo di modelli più leggeri per task secondari riduce il carico computazionale complessivo.
Un altro aspetto fondamentale riguarda la gestione delle dipendenze tra i task. Non tutte le operazioni sono completamente indipendenti, e in presenza di vincoli logici o sequenziali è necessario un sistema di coordinamento che eviti conflitti o incoerenze. L’orchestratore svolge quindi anche un ruolo di sincronizzazione, garantendo che i risultati prodotti dai diversi agenti siano compatibili e integrabili.
La resilienza del sistema rappresenta un’ulteriore sfida tecnica. In un ambiente con centinaia di agenti, è inevitabile che alcuni falliscano o producano risultati incompleti. Per questo motivo, Kimi K2.6 integra meccanismi di fault tolerance, come la ripetizione automatica dei task falliti, la gestione dei timeout e la fusione di risultati parziali. Questi elementi sono essenziali per mantenere un livello di qualità costante, anche in presenza di errori distribuiti.
Il monitoraggio continuo diventa quindi una componente critica dell’architettura. Indicatori come il tasso di completamento degli agenti, l’utilizzo dei token e la distribuzione dei tempi di esecuzione forniscono informazioni necessarie per ottimizzare il sistema e prevenire inefficienze. Questo livello di osservabilità avvicina ulteriormente l’Agent Swarm a un’infrastruttura di calcolo distribuito tradizionale, piuttosto che a un semplice modello AI.