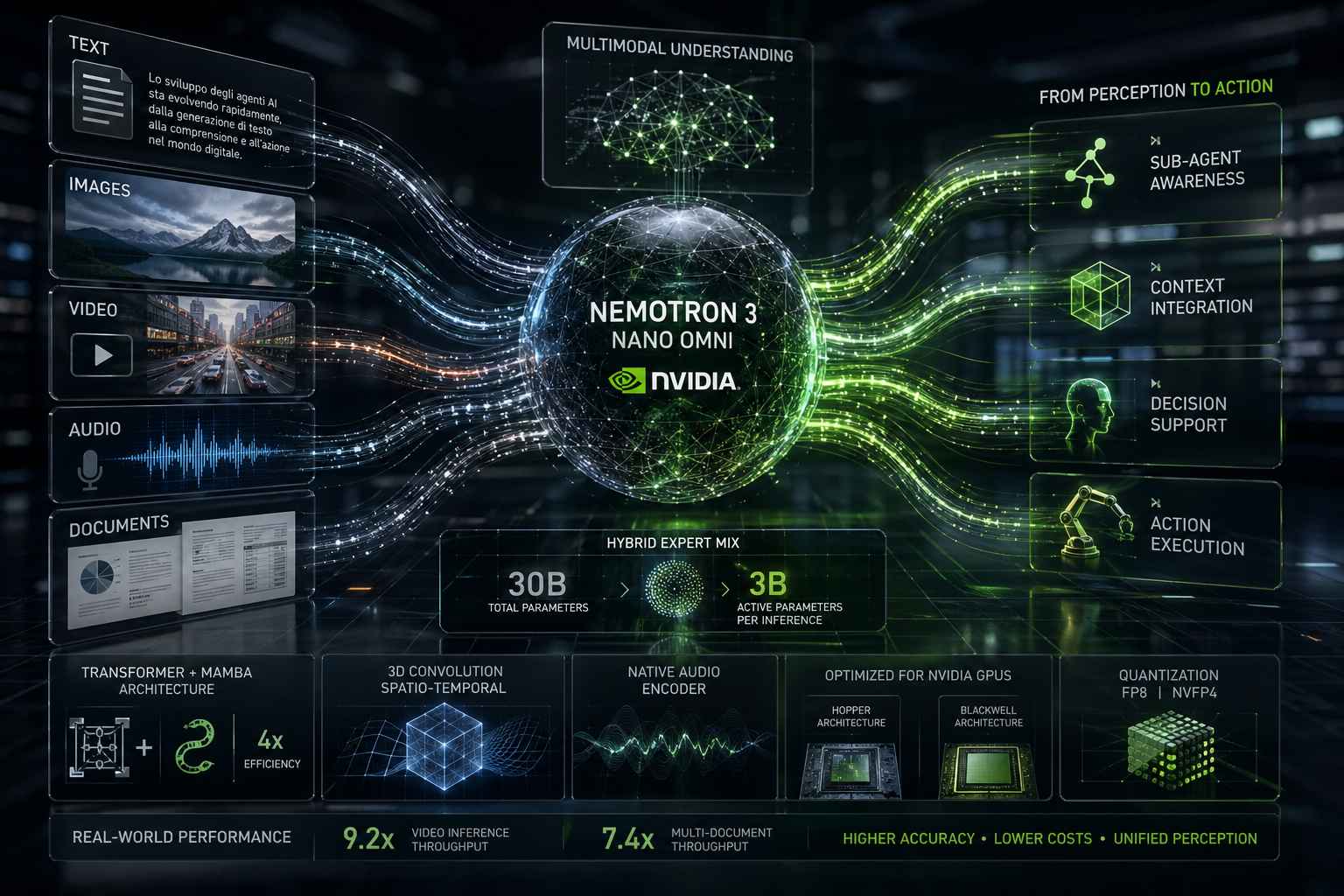
Negli ultimi anni, lo sviluppo degli agenti di intelligenza artificiale ha seguito una traiettoria sempre più ambiziosa: passare dalla semplice generazione di testo a sistemi capaci di osservare, comprendere e agire nel mondo digitale. Questo processo, spesso definito come un ciclo “dalla percezione all’azione”, richiede la capacità di interpretare contemporaneamente informazioni provenienti da fonti diverse, come immagini, video, audio e documenti. Tuttavia, fino a oggi, questa integrazione è stata costruita in modo frammentato, attraverso catene di modelli separati. È proprio questo limite che NVIDIA prova a superare con il lancio di Nemotron 3 Nano Omni.
Il modello rappresenta un cambiamento di approccio piuttosto netto. Invece di utilizzare sistemi distinti per la visione, il linguaggio e l’audio, Nemotron 3 Nano Omni integra tutte queste capacità all’interno di un unico modello multimodale. Questo significa che testo, immagini, video e suoni non vengono più elaborati in sequenza da componenti diverse, ma vengono interpretati insieme, nello stesso ciclo di inferenza. Il risultato è un sistema più compatto, ma soprattutto più coerente dal punto di vista del contesto.
La differenza non è solo tecnica, ma anche operativa. Nei sistemi tradizionali, ogni passaggio tra modelli introduce latenza, costi e potenziali errori di interpretazione. Quando un’immagine viene analizzata da un modello di visione, poi descritta in testo e infine elaborata da un modello linguistico, parte dell’informazione originale può andare persa o distorta. Con Nemotron 3 Nano Omni, questo passaggio intermedio viene eliminato, permettendo una comprensione più diretta e, almeno in teoria, più accurata.
Questo approccio si riflette anche nel ruolo che il modello è destinato a ricoprire. Più che un sistema standalone, viene concepito come un “sub-agente” all’interno di architetture più ampie, responsabile della consapevolezza multimodale. In altre parole, è il componente che osserva il mondo, interpreta segnali diversi e fornisce un contesto coerente agli altri agenti che si occupano dell’azione.
In base alle prestazioni, i risultati dichiarati indicano miglioramenti significativi. Il modello ha raggiunto livelli di accuratezza molto elevati nei benchmark di comprensione documentale come MM Long Bench-Doc e OCR Bench V2, ma ha mostrato anche risultati solidi in ambiti più complessi, come l’analisi video e audio, con valutazioni positive in test come WorldSense, Daily Omni e Voice Bench. Particolarmente rilevante è il benchmark MediaPerf, basato su dati multimediali reali, in cui Nemotron 3 Nano Omni è riuscito a combinare alta produttività e costi contenuti, un equilibrio raro nei sistemi multimodali.
A monte di queste prestazioni c’è un’architettura progettata per essere efficiente. Il modello utilizza un approccio Hybrid Expert Mix, una variante dei sistemi Mixture of Experts, in cui solo una parte dei parametri viene attivata per ogni operazione. In questo caso, su un totale di 30 miliardi di parametri, ne vengono utilizzati circa 3 miliardi per inferenza. Questo consente di mantenere un buon livello di potenza senza compromettere l’efficienza.
Un altro elemento chiave è la combinazione tra architetture Transformer e modelli della famiglia Mamba, una scelta che permette di migliorare significativamente l’efficienza in termini di memoria e calcolo. Secondo i dati disponibili, questo approccio consente di ottenere fino a quattro volte più efficienza rispetto alle soluzioni tradizionali, un fattore cruciale soprattutto in contesti operativi reali.
L’elaborazione delle immagini e dei video rappresenta uno degli aspetti più innovativi. Il modello utilizza tecniche di analisi spazio-temporale basate su convoluzioni 3D e sistemi di campionamento video avanzati, che permettono di comprimere grandi quantità di dati mantenendo le informazioni rilevanti. Questo consente una comprensione più accurata delle scene, basata sui contenuti visivi reali e non solo su elementi derivati, come trascrizioni audio o metadati.
Anche l’audio è integrato in modo nativo, grazie a un codificatore dedicato che lavora insieme agli altri componenti per creare una rappresentazione unificata dei dati. Tutti questi elementi vengono poi trasformati in token condivisi, che alimentano il modello linguistico centrale, creando una base comune per l’elaborazione multimodale.
Un aspetto particolarmente interessante riguarda l’ottimizzazione hardware. Nemotron 3 Nano Omni è progettato per funzionare in modo efficiente su diverse generazioni di GPU, come le architetture Hopper e Blackwell di NVIDIA, e utilizza tecniche di quantizzazione avanzate come FP8 e NVFP4 per ridurre la latenza e migliorare la stabilità. Questo lo rende adatto non solo al cloud, ma anche a scenari on-device e edge, inclusi PC di fascia alta.
I risultati in ambienti reali confermano questa impostazione. Il modello ha mostrato un aumento della capacità di elaborazione fino a 9,2 volte nelle attività di inferenza video e fino a 7,4 volte nelle operazioni su documenti multipli. Si tratta di numeri che indicano un miglioramento concreto nell’efficienza dei carichi di lavoro, non solo nei test teorici.
Il messaggio strategico dietro Nemotron 3 Nano Omni è chiaro. Invece di continuare a costruire sistemi complessi basati su catene di modelli separati, NVIDIA propone un approccio più integrato, in cui la percezione multimodale viene gestita in modo unitario. Questo non solo riduce i costi e la complessità, ma cambia anche il modo in cui si progettano gli agenti AI.