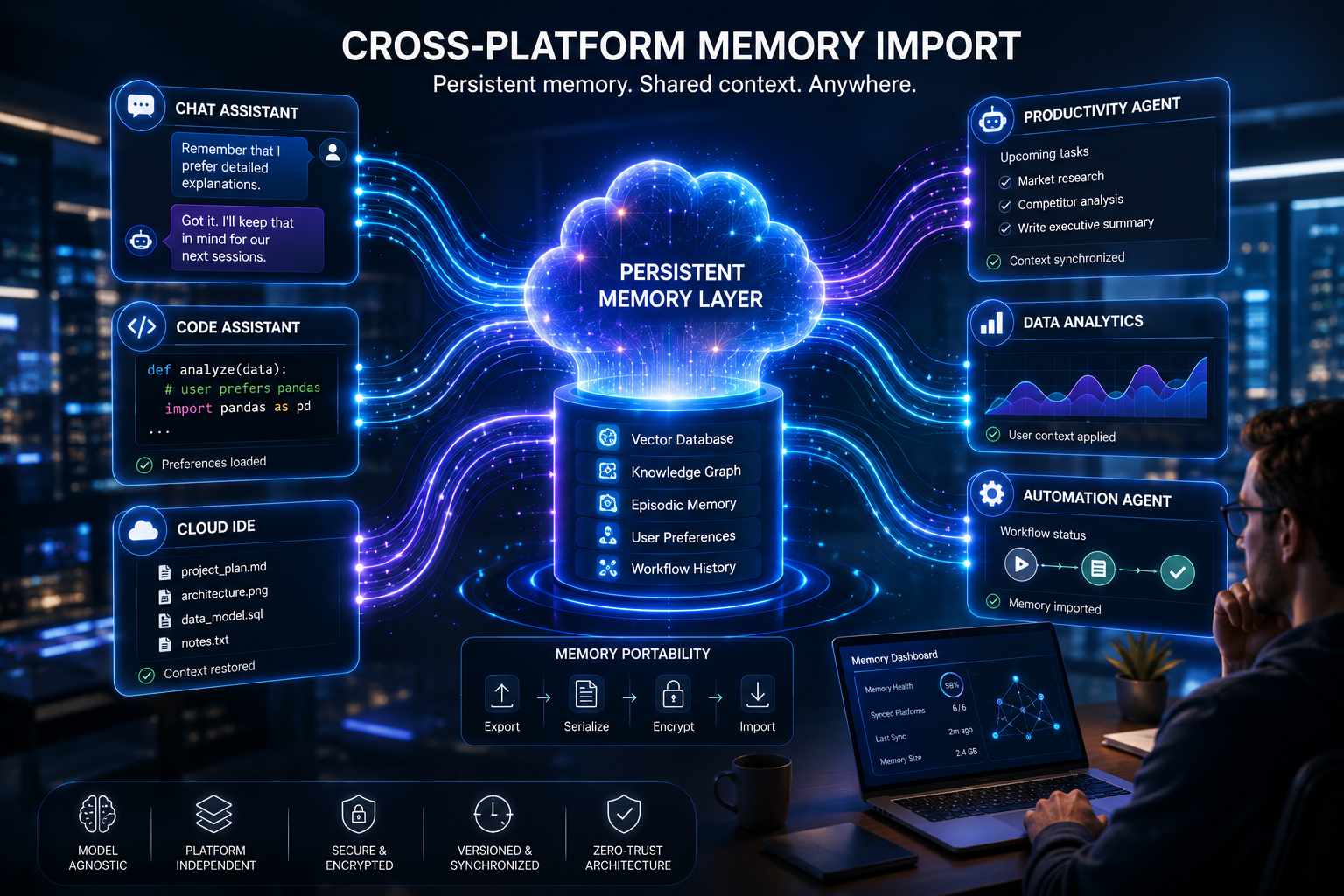
I sistemi AI stanno entrando in una nuova fase evolutiva in cui la memoria persistente diventa un’infrastruttura centrale, non più una semplice funzionalità accessoria limitata alla singola applicazione. Il concetto di cross-platform memory import nasce proprio da questa trasformazione: permettere a modelli, agenti e assistenti AI di trasferire contesto, preferenze, cronologia operativa e conoscenza accumulata tra piattaforme differenti senza dover ricominciare da zero a ogni sessione.
I grandi modelli linguistici restano intrinsecamente stateless. Anche con context window enormi, il modello non “ricorda” realmente le interazioni precedenti se queste non vengono reiniettate nel prompt o archiviate in un layer esterno di memoria persistente. Questo limite sta diventando sempre più problematico nei workflow enterprise e negli ambienti multi-agent, dove gli utenti si aspettano continuità contestuale tra strumenti diversi, coding assistant, piattaforme cloud, IDE e agenti autonomi.
La nuova generazione di memory layer sta quindi introducendo architetture dedicate che separano il reasoning del modello dalla gestione della memoria. Sistemi come Mem0, Cognee o nuove implementazioni open source agent-agnostic utilizzano database vettoriali, knowledge graph, retrieval semantico e storage persistente per costruire una “memoria esterna” condivisibile tra applicazioni AI differenti. In questo modello il contesto non appartiene più al singolo chatbot, ma diventa una risorsa portabile e sincronizzabile tra ecosistemi cloud diversi.
Il cross-platform memory import richiede diversi componenti architetturali. Il primo è un sistema di serializzazione standardizzato capace di rappresentare memoria episodica, preferenze utente, conoscenza semantica e stato operativo in un formato interoperabile. Il secondo è un layer di retrieval persistente basato su embedding, full-text search o knowledge graph che consenta di recuperare informazioni rilevanti indipendentemente dalla piattaforma AI di destinazione. Il terzo elemento riguarda la sincronizzazione e il versioning della memoria, necessari per evitare conflitti tra agenti multipli che aggiornano simultaneamente lo stesso contesto condiviso.
Uno degli aspetti più rilevanti è che la memoria sta evolvendo da semplice cronologia conversazionale a vera infrastruttura cognitiva distribuita. I nuovi sistemi non salvano soltanto chat precedenti, ma costruiscono relazioni persistenti tra entità, documenti, tool call, workflow e preferenze operative. Questo consente agli agenti AI di sviluppare continuità comportamentale tra ambienti differenti, mantenendo coerenza nelle attività anche quando cambiano modello, provider cloud o applicazione utilizzata.
Parallelamente stanno emergendo nuovi problemi di sicurezza e governance. Una memoria condivisa tra piattaforme implica infatti trasferimento continuo di dati contestuali sensibili, preferenze personali e cronologia operativa tra ambienti eterogenei. Per questo motivo diversi progetti stanno introducendo architetture zero-trust, crittografia verificabile, provenance tracking e sistemi di isolamento multi-tenant per impedire memory poisoning, leakage di contesto o manipolazione delle memorie persistenti.
Anche l’infrastruttura cloud sta iniziando ad adattarsi a questa evoluzione. I memory layer moderni vengono progettati come componenti distribuiti indipendenti dal modello AI sottostante, integrabili via API, MCP server o protocolli interoperabili. In pratica la memoria diventa un servizio cloud autonomo, riutilizzabile contemporaneamente da LLM differenti, agenti software e sistemi di automazione.
L’effetto finale è un cambiamento strutturale del paradigma AI-as-a-service. Finora ogni piattaforma ha costruito ecosistemi chiusi in cui il contesto rimaneva confinato all’interno del singolo provider. Il memory import cross-platform punta invece a rendere la memoria portabile, persistente e indipendente dal modello utilizzato, trasformandola in uno strato condiviso dell’infrastruttura cloud AI di nuova generazione.