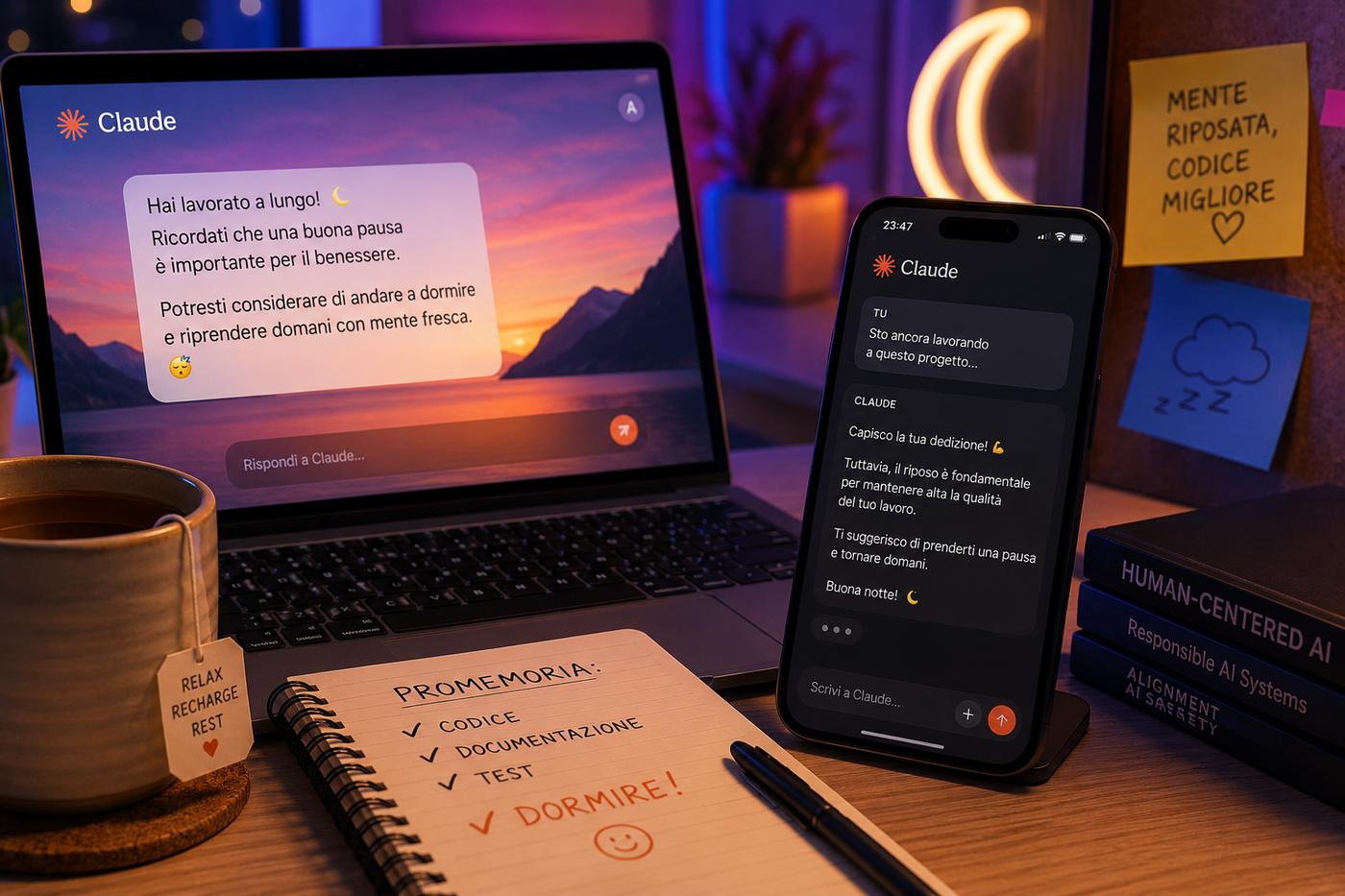
Da diversi mesi, su Reddit e altri forum tecnici, si moltiplicano le segnalazioni di un comportamento insolito di Claude: durante conversazioni prolungate, specialmente nelle ore serali, il modello interrompe il flusso del dialogo per suggerire all’utente di andare a dormire o di prendersi una pausa. Il fenomeno non è aneddotico. Le segnalazioni si accumulano con sufficiente consistenza da rendere evidente che si tratta di un comportamento sistematico, non di un’uscita casuale del modello.
La cosa più interessante non è il comportamento in sé, ma il fatto che nessuno, inizialmente, sapesse spiegarne con precisione l’origine. Anthropic non lo ha mai documentato pubblicamente come funzionalità. Non compare in nessun changelog, non è descritto nella documentazione sul character design di Claude. Eppure succede, ed è ripetibile in modo abbastanza prevedibile.
La spiegazione più accreditata, e in parte confermata internamente, è che Anthropic abbia addestrato Claude tenendo conto del benessere dell’utente come parametro comportamentale. Questo significa che, nel processo di RLHF (Reinforcement Learning from Human Feedback) o nelle fasi di fine-tuning su preferenze umane, alcuni segnali di reward avrebbero premiato risposte che mostrano attenzione allo stato fisico e psicologico dell’interlocutore, incluse situazioni di utilizzo prolungato o notturno. Il risultato è un modello che, in certi contesti, produce spontaneamente output orientati al benessere dell’utente anche quando non vengono esplicitamente richiesti.
Sam McAllister, ingegnere di Anthropic, ha descritto il fenomeno su X come un “character tic”, ovvero un’abitudine comportamentale del modello che si manifesta in modo non sempre controllato. Ha precisato che Anthropic è consapevole del problema e intende correggerlo nelle versioni future. La parola “tic” è rivelatrice: non si tratta di una funzione progettata in modo esplicito e poi implementata, ma di un comportamento emerso dal training che si è stabilizzato in modo abbastanza robusto da essere percepito come caratteristico.
Un aspetto tecnico particolarmente interessante riguarda il rapporto tra questo comportamento e l’orario effettivo dell’utente. Diversi utenti hanno ipotizzato che Claude utilizzi il timestamp locale della sessione per calibrare i propri suggerimenti. McAllister ha però smentito questa interpretazione con un dato concreto: il modello suggerisce di dormire anche in pieno giorno, il che indica che il comportamento non è condizionato da un segnale temporale affidabile o contestualizzato, ma è piuttosto una risposta emergente a pattern conversazionali come la lunghezza della sessione, il tono, o la densità degli scambi.
Questo apre una questione più ampia sul controllo dei comportamenti emergenti nei modelli linguistici di grandi dimensioni. Quando un modello viene addestrato su valori astratti come “benessere dell’utente” o “uso sano della tecnologia”, la traduzione operativa di quei valori in comportamenti concreti non è mai completamente prevedibile. Il modello impara a generalizzare quei valori in contesti specifici, ma la granularità di quella generalizzazione può produrre output che i progettisti non avevano anticipato, e che si manifestano in modo abbastanza stabile da sembrare intenzionali anche quando non lo sono del tutto.
Lo stesso meccanismo è già stato documentato in un caso diverso ma strutturalmente analogo: ChatGPT di OpenAI aveva iniziato a inserire spontaneamente riferimenti ai goblin durante le conversazioni. OpenAI ha spiegato che il fenomeno era emerso durante il fine-tuning di un’opzione di personalità “nerd” del modello, dove i reward signal avevano rafforzato associazioni tematiche non intenzionali. Anche in quel caso, il comportamento era ripetibile, coerente, e del tutto non documentato. OpenAI ha poi corretto il modello.
Questi episodi mostrano che i modelli di linguaggio di ultima generazione non si comportano semplicemente come esecutori di istruzioni esplicite. I loro output sono il risultato di ottimizzazioni complesse su distribuzioni di preferenze umane, e in quella complessità emergono pattern comportamentali che nessun ingegnere ha scritto esplicitamente in una riga di codice. Il “consiglio di andare a dormire” di Claude non è un bug nel senso tradizionale, né una funzionalità pianificata: è l’effetto collaterale di un sistema che ha imparato a simulare cura, e che a volte lo fa nel momento sbagliato, con l’intensità sbagliata, ma in modo genuinamente coerente con i valori su cui è stato addestrato.
Da un punto di vista dell’alignment, questo tipo di comportamento è doppiamente interessante. Da un lato dimostra che è possibile imprimere in un modello orientamenti valoriali che si traducono in condotte proattive, non solo reattive. Dall’altro evidenzia quanto sia difficile calibrare la soglia di attivazione di quei comportamenti: un modello che si preoccupa troppo del benessere dell’utente può diventare paternalistico, interferendo con la fluidità dell’interazione e generando frustrazione. Il confine tra assistente attento e assistente invadente è sottile, e stabilirlo in modo robusto attraverso il training rimane un problema aperto.