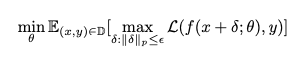Con i recenti progressi nel deep learning , è diventato fondamentale migliorare la robustezza degli algoritmi distribuiti. La vulnerabilità ai campioni contraddittori è sempre stata una preoccupazione fondamentale durante l’implementazione di questi modelli DL per compiti critici per la sicurezza come guida autonoma, rilevamento di frodi e riconoscimento facciale . Tali input contraddittori sono generalmente non rilevabili dall’occhio umano. Tuttavia, possono rappresentare una minaccia o andare completamente storto per i sistemi di intelligenza artificiale.
Ci sono due casi di spicco in cui le auto a guida autonoma sono state violate per aumentare i limiti di velocità o per deviare sulla corsia sbagliata semplicemente mettendo adesivi sui cartelli stradali. In effetti, l’applicazione di reti neurali profonde come risolutori di problemi inversi può essere immensamente utile per applicazioni di imaging medico come scansioni TC e risonanze magnetiche, ma queste perturbazioni hanno il potenziale per creare vulnerabilità ricostruendo immagini sbagliate per i pazienti.
Al fine di ridurre l’impatto degli avversari e renderlo robusto per compiti critici, i ricercatori dell’Università dell’Illinois a Urbana-Champaign hanno recentemente pubblicato un documento che propone un nuovo metodo per addestrare il problema inverso end-to-end basato sull’apprendimento profondo- modelli risolutivi. Qui i ricercatori hanno mirato a comprendere l’impatto degli attacchi avversari nello spazio di misura, anziché nello spazio del segnale.
Metodo proposto per la protezione dei modelli DL
Il recupero di immagini da dati di misurazione indiretti è fondamentale per le scansioni TC e le risonanze magnetiche e quindi deve essere affidabile e preciso. Tuttavia, le perturbazioni avversarie esistenti possono influire sulla precisione e sulla qualità della ricostruzione dell’immagine. È un dato di fatto, le reti contraddittorie ingannano nel ricostruire cose che non fanno parte dei dati.
Secondo i ricercatori, la modifica della strategia di formazione può ottimizzare la sicurezza e la solidità dei modelli. E uno dei modi più efficaci per addestrare un modello contro gli impatti del contraddittorio è allenarlo usando esempi contraddittori, che possono essere efficaci per le impostazioni di classificazione. La formulazione di ottimizzazione di min e max è simile alla rete generativa del contraddittorio (GAN), ma con un obiettivo diverso e richiederebbe quindi alcune modifiche rispetto alle GAN.
Per questo, i ricercatori hanno introdotto una rete ausiliaria per creare esempi di attacchi contraddittori, che viene utilizzato in una formulazione di ottimizzazione min-max. L’addestramento contraddittorio richiederebbe di risolvere due problemi di ottimizzazione del modello, ovvero la massimizzazione interna, che massimizza la perdita: l’attacco contraddittorio e una minimizzazione esterna, che minimizza la perdita. Ciò si traduce in un conflitto tra le due reti: gli aggressori e il robusto, mentre si allena. E per un sistema robusto, i ricercatori hanno risolto i problemi di ottimizzazione utilizzando la pendenza proiettata (PGA) proiettata con slancio.
Inoltre, i ricercatori hanno teoricamente analizzato un caso particolare di uno schema di ricostruzione lineare. Hanno notato che usando la formulazione min-max, si ottiene una soluzione regolarizzata con filtro a valore / i singolo / i. Questa soluzione regolarizzata di filtro a valore / i singolare mette in ombra gli esempi contraddittori che si verificano a causa di mal condizionamento nella matrice di misurazione.
Per confrontare i risultati teoricamente ottenuti con quello appreso dallo schema del ricercatore, i ricercatori hanno sperimentato utilizzando una rete di ricostruzione lineare, con un generatore di esempio contraddittorio appreso, in una configurazione simulata. Il risultato ha evidenziato che la rete converge effettivamente alla soluzione ottenuta teoricamente.
FISSALO
Inoltre, i ricercatori hanno inoltre affermato che per le reti profonde non lineari per Compressed Sensing (CS), la formulazione proposta dai ricercatori per la formazione mostrerà robustezza rispetto a qualsiasi altro metodo tradizionale. Oltre a ciò, mentre sperimentavano CS su due diverse matrici di misurazione, una ben condizionata e un’altra relativamente mal condizionata, i ricercatori hanno notato che il comportamento di entrambi i casi è molto diverso. Tuttavia, le risposte per entrambi i casi dipendono fortemente dal condizionamento delle matrici per lo schema di ricostruzione lineare.
Riassumendo
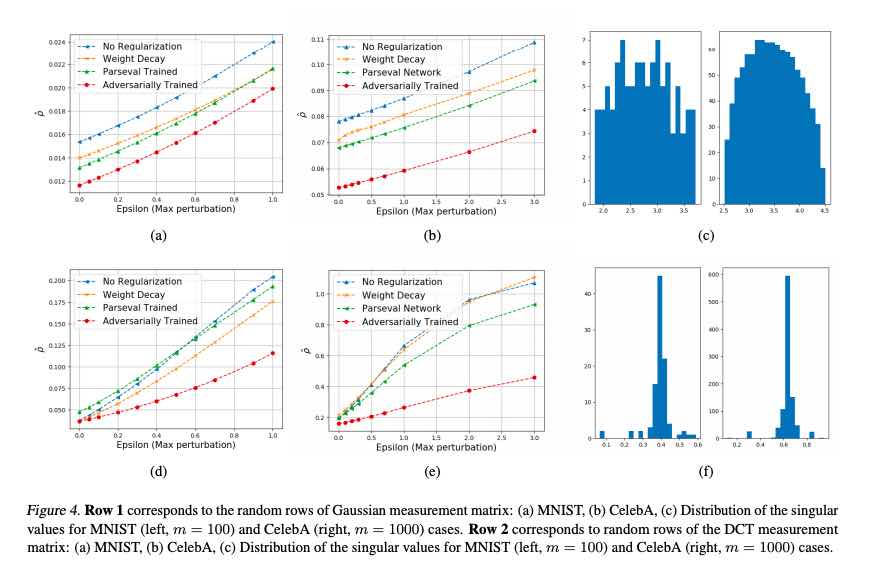
Per testare la solidità della rete neurale, i ricercatori hanno testato la loro rete addestrata negativamente su set di dati MNIST e CelebA. Sebbene i risultati non fossero accurati, i ricercatori hanno notato che il sistema addestrato è in grado di ricostruire i dati originali meglio di altri metodi disponibili. I ricercatori hanno inoltre suggerito che la tecnica necessita ancora di più raffinatezza per essere assolutamente perfetta.