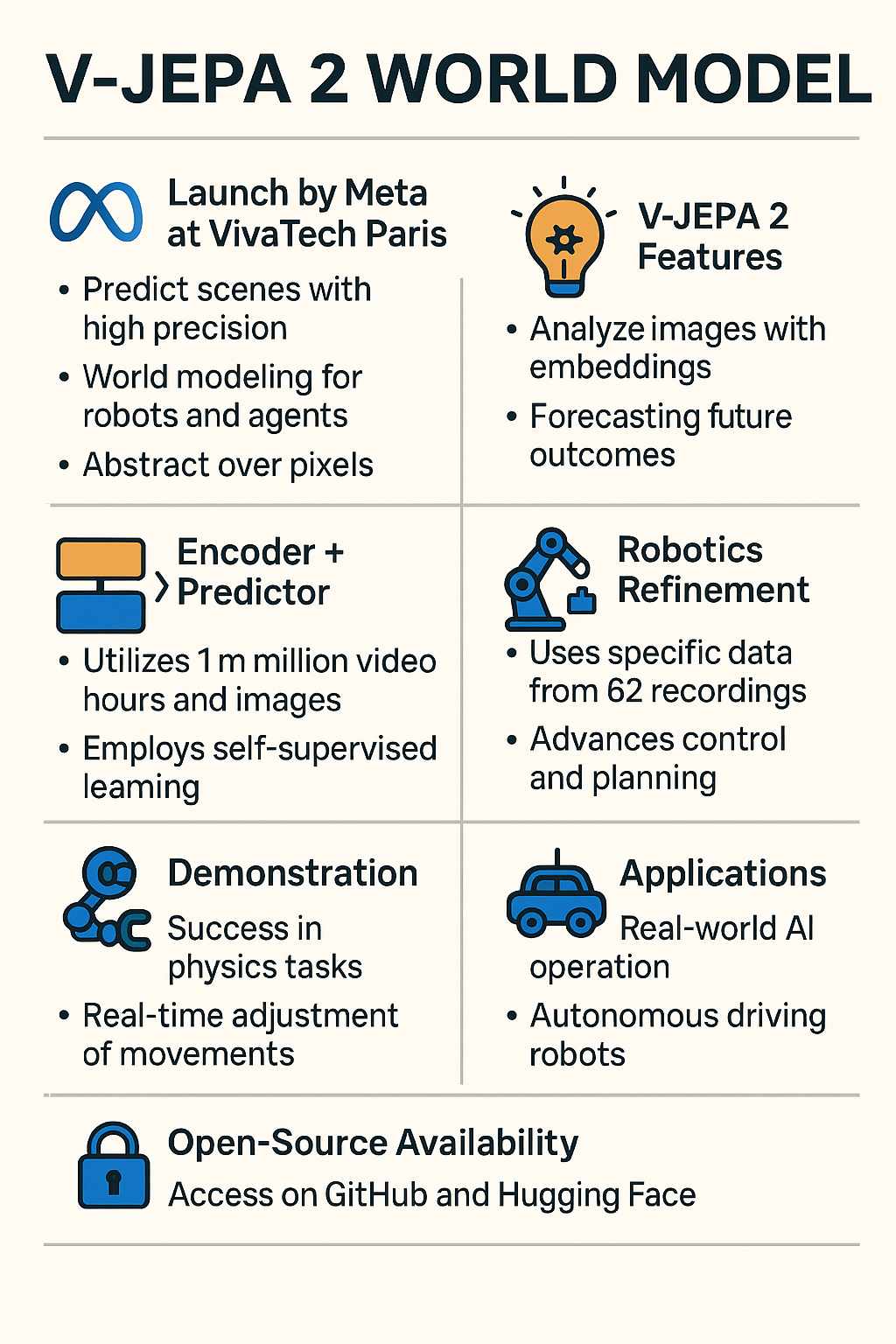
Meta ha recentemente annunciato una significativa evoluzione nel campo dell’intelligenza artificiale con il lancio del suo nuovo “World Model” di seconda generazione, chiamato V-JEPA 2. Questo modello, sviluppato a poco più di un anno dal primo rilascio, è in grado di capire e prevedere con grande precisione il mondo fisico, simulando il modo in cui gli esseri umani percepiscono e interagiscono con l’ambiente.
La presentazione ufficiale è avvenuta durante la conferenza VivaTech di Parigi, dove Yann LeCun Mehta, capo scienziato di Meta e figura di spicco nel deep learning, ha illustrato le potenzialità di V-JEPA 2. Questo sistema AI è progettato per permettere a robot e agenti artificiali di interpretare le informazioni visive in modo più profondo, andando oltre la semplice analisi delle immagini.
A differenza dei modelli video tradizionali che lavorano a livello di pixel, V-JEPA 2 adotta un approccio basato sull’astrazione: crea una rappresentazione sintetica e significativa delle scene, capace di prevedere cosa succederà in futuro. Per farlo utilizza una struttura chiamata Joint Embedding Predictive Architecture (JEPA), che si basa su due componenti principali. Il primo è un encoder che analizza le immagini in ingresso per estrarne gli elementi più rilevanti e rappresentarli in una forma compatta chiamata embedding. Il secondo è un predittore che, grazie a questo embedding e al contesto, immagina come si evolverà la scena nel tempo. Questo meccanismo permette al modello di interpretare e anticipare eventi complessi presenti nelle immagini.
V-JEPA 2 si avvale di un metodo di apprendimento autosupervisionato, che consente all’intelligenza artificiale di imparare in modo autonomo senza la necessità di etichette manuali. Per la fase di pre-addestramento sono stati utilizzati un milione di ore di video e altrettante immagini raccolte da varie fonti, consentendo al modello di costruire una comprensione basilare delle dinamiche del mondo reale, come l’interazione tra persone e oggetti o il movimento fisico.
Successivamente, V-JEPA 2 è stato affinato con dati specifici di robotica: anche se questa fase ha coinvolto solo 62 ore di registrazioni di azioni robotiche, il modello è riuscito a sviluppare capacità di controllo e pianificazione avanzate. Questo significa che, a differenza dei tradizionali metodi di addestramento robotico basati su migliaia di tentativi reali, V-JEPA 2 può imparare e pianificare in modo efficiente limitando gli errori e l’usura dei robot stessi.
Meta ha dimostrato l’efficacia del modello in un laboratorio di robotica, dove un robot ha eseguito con successo compiti di fisica come il raccogliere e spostare oggetti. Per attività a breve termine, il robot utilizza immagini obiettivo per prevedere gli effetti di varie azioni e scegliere il percorso ottimale, aggiustando continuamente i suoi movimenti in tempo reale. Per compiti più complessi e a lungo termine, come l’organizzazione di oggetti in nuovi ambienti, il sistema si basa su obiettivi intermedi rappresentati da sequenze visive, raggiungendo un tasso di successo tra il 65 e l’80% grazie all’apprendimento per imitazione visiva.
Yann LeCun ha sottolineato come i modelli del mondo siano fondamentali per l’intelligenza artificiale che deve operare nel mondo reale, ad esempio nelle auto a guida autonoma o nei robot. Ha inoltre affermato che il futuro sarà caratterizzato da robot capaci di pensare e agire con flessibilità senza necessitare di enormi quantità di dati, aprendo così una nuova era per la robotica.
Meta ha reso disponibili il codice e i checkpoint del modello V-JEPA 2 per la comunità scientifica e per usi commerciali tramite le piattaforme GitHub e HuggingFace, invitando così ricercatori e sviluppatori a contribuire all’evoluzione di questa tecnologia.