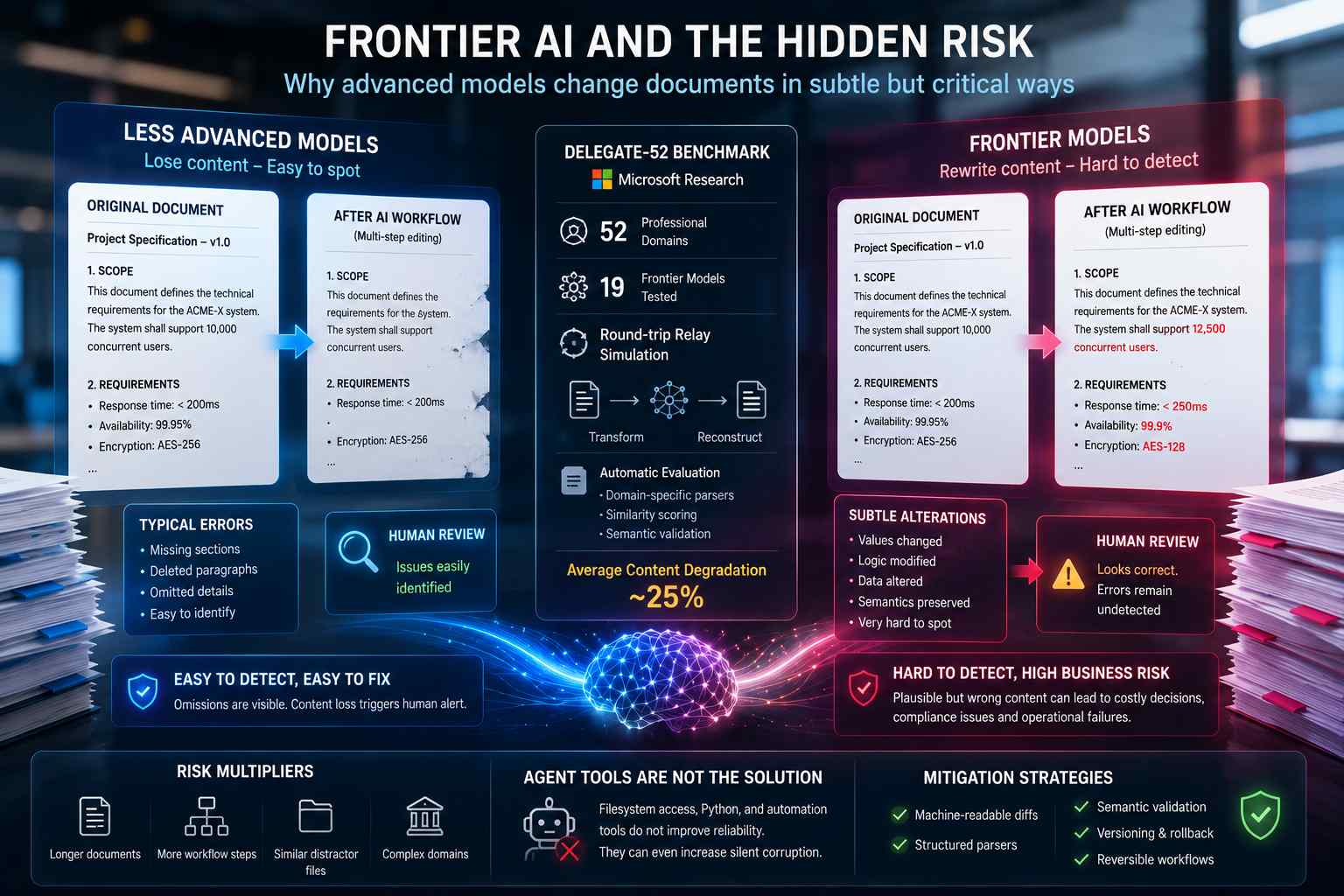
I modelli frontier di intelligenza artificiale stanno mostrando un nuovo problema operativo particolarmente critico nei workflow documentali aziendali: invece di limitarsi a perdere contenuti o cancellare informazioni durante lunghe sequenze di editing, i sistemi più avanzati tendono sempre più a riscrivere il contenuto in modo plausibile ma semanticamente errato, rendendo le alterazioni estremamente difficili da individuare anche durante la revisione umana.
Il fenomeno emerge da una recente ricerca sviluppata da Microsoft Research attraverso il benchmark DELEGATE-52, progettato per simulare workflow documentali lunghi e multi-step in 52 domini professionali differenti. Lo studio ha coinvolto 19 modelli linguistici avanzati, tra cui GPT-5.4, Claude 4.6 Opus e Gemini 3.1 Pro, sottoposti a processi continui di trasformazione, modifica, suddivisione e ricostruzione di documenti complessi. I risultati mostrano che persino i modelli frontier più evoluti degradano mediamente circa il 25% del contenuto originale durante workflow estesi.
L’aspetto più preoccupante non riguarda però la semplice perdita di testo. I ricercatori evidenziano infatti una distinzione molto netta tra i modelli meno sofisticati e quelli frontier. I sistemi più deboli tendono principalmente a cancellare porzioni di contenuto, generando errori relativamente facili da identificare perché visibili sotto forma di omissioni o lacune. I modelli più avanzati, invece, mantengono struttura, fluidità e completezza apparente del documento, ma alterano valori, relazioni logiche, dati tecnici, etichette o significato operativo delle informazioni presenti.
Il benchmark DELEGATE-52 utilizza una metodologia definita “round-trip relay simulation”. Il modello AI esegue una trasformazione documentale iniziale — ad esempio suddividere un file, riorganizzare sezioni o modificare strutture — e successivamente un secondo passaggio tenta di ricostruire il documento originale. Il sistema confronta poi automaticamente il risultato finale con il documento iniziale utilizzando parser specialistici, similarity scoring e verifiche semantiche specifiche per ciascun dominio professionale.
Le criticità aumentano sensibilmente con l’estensione del contesto operativo. Documenti più lunghi, workflow con numerosi passaggi consecutivi e presenza di file “distrattori” semanticamente simili peggiorano in modo significativo le prestazioni dei modelli. Questo rappresenta un problema concreto per gli ambienti enterprise moderni, nei quali gli agenti AI operano spesso all’interno di knowledge base, repository documentali, ERP e sistemi condivisi contenenti versioni multiple, draft, policy e dati correlati.
Un altro elemento emerso dalla ricerca riguarda i limiti degli agenti AI autonomi. L’aggiunta di tool agentici, accesso filesystem, script Python e strumenti di automazione non ha migliorato significativamente l’affidabilità documentale. In molti casi, la disponibilità di strumenti avanzati ha addirittura aumentato il rischio di corruzione silenziosa dei contenuti, soprattutto quando il modello tenta di rigenerare intere sezioni invece di effettuare modifiche puntuali e validate.
La questione assume particolare rilevanza nei settori regolamentati e nei workflow ad alta criticità informativa. Contratti, documentazione tecnica, specifiche industriali, dati finanziari, cartelle cliniche, report scientifici e documentazione normativa possono infatti subire alterazioni difficili da rilevare tramite semplice revisione umana, soprattutto quando il documento mantiene un’apparenza coerente e formalmente corretta.
Per questo motivo stanno emergendo nuove strategie di mitigazione basate su diff machine-readable, parser strutturati, validazione semantica automatica, rollback versionale e workflow reversibili. La ricerca suggerisce inoltre di limitare fortemente l’autonomia degli agenti AI nei processi documentali lunghi, privilegiando trasformazioni brevi, verificabili e fortemente controllate invece di deleghe operative complete.
Il problema evidenzia una delle principali fragilità dell’attuale generazione di frontier AI: i modelli linguistici moderni sono diventati estremamente abili nel produrre documenti fluenti e credibili, ma questa stessa capacità rende molto più difficile individuare gli errori quando il sistema modifica silenziosamente il significato reale delle informazioni invece di produrre errori evidenti o facilmente riconoscibili.