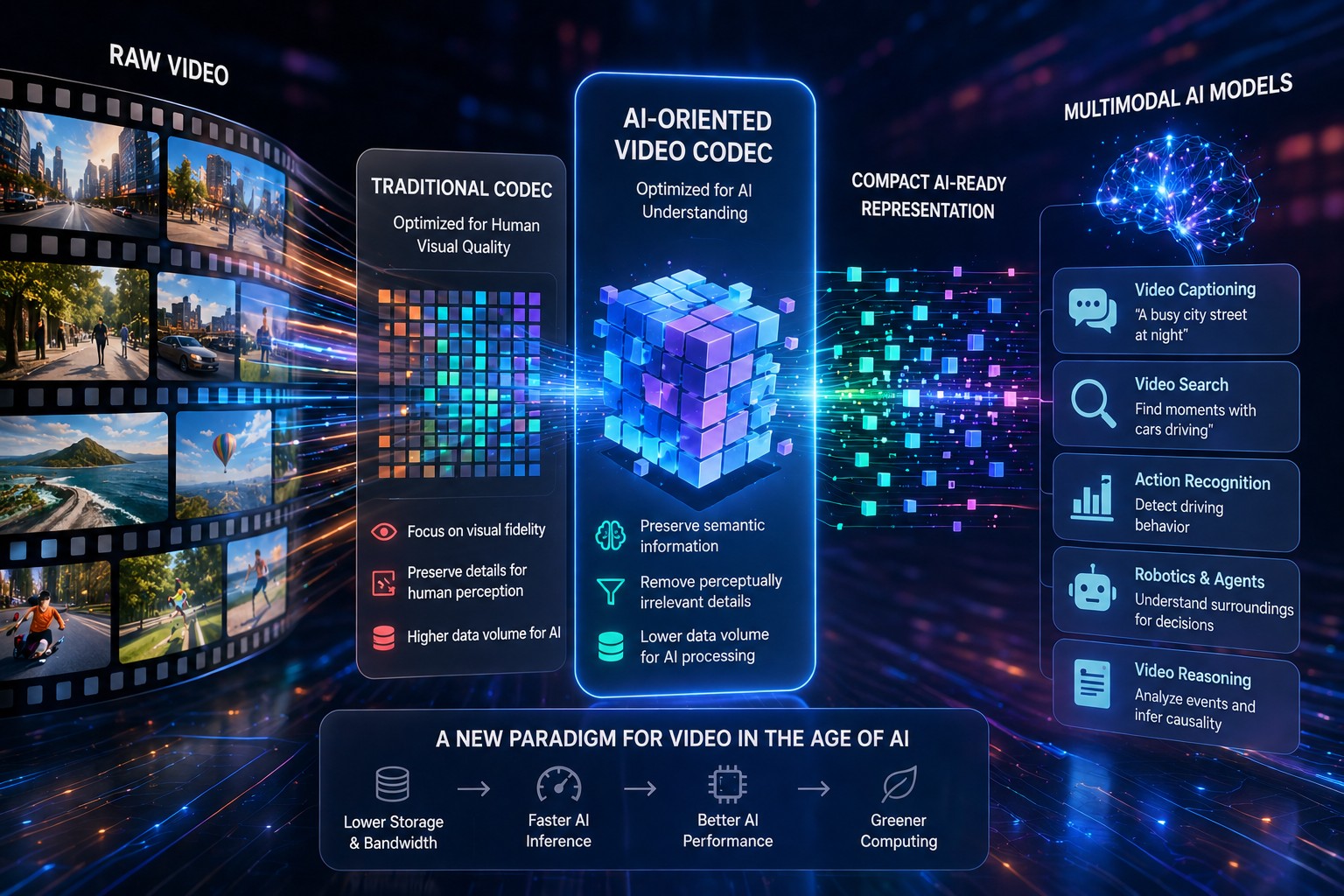
Un gruppo di ricercatori della Shanghai Jiao Tong University, dello Shanghai Innovation Institute e di JD.com ha sviluppato un nuovo approccio alla codifica video progettato specificamente per l’elaborazione da parte dei modelli di intelligenza artificiale. Il progetto nasce dall’osservazione che i codec tradizionali sono stati progettati per ottimizzare la qualità percepita dagli esseri umani, mentre le moderne applicazioni basate su modelli multimodali richiedono una rappresentazione dei contenuti differente, in grado di preservare le informazioni più utili per l’analisi automatica.
La ricerca propone un sistema che trasforma i video in una rappresentazione compatta orientata alle esigenze dei modelli AI anziché alla semplice ricostruzione visiva. In questo scenario il codec non viene più considerato esclusivamente uno strumento per ridurre la quantità di dati da trasmettere o archiviare, ma diventa un’interfaccia tra il contenuto video e il modello di intelligenza artificiale incaricato di comprenderlo, analizzarlo o utilizzarlo per attività successive di ragionamento.
Secondo i ricercatori, l’aumento della diffusione dei modelli multimodali sta mettendo in evidenza i limiti delle tecnologie di compressione tradizionali. I sistemi attuali sono infatti ottimizzati per mantenere dettagli visivi rilevanti per l’occhio umano, ma non necessariamente le informazioni semantiche che risultano più importanti per un modello linguistico o visivo. Questo porta a un utilizzo inefficiente delle risorse computazionali e della larghezza di banda quando i video vengono elaborati da sistemi AI.
L’architettura proposta mira quindi a identificare e conservare gli elementi informativi più significativi per la comprensione automatica delle scene. L’obiettivo è consentire ai modelli di lavorare su rappresentazioni più leggere, riducendo il volume dei dati da elaborare senza compromettere le capacità di interpretazione del contenuto. In pratica, il video viene trasformato in una forma maggiormente allineata ai processi interni utilizzati dai modelli multimodali per estrarre significato dalle informazioni visive.
La ricerca si inserisce in un filone emergente che vede l’infrastruttura video adattarsi progressivamente alle esigenze dell’intelligenza artificiale. Se i codec tradizionali sono stati sviluppati per ottimizzare la distribuzione di contenuti destinati alle persone, le future generazioni di codec potrebbero essere progettate sempre più spesso per alimentare sistemi AI, agenti multimodali e piattaforme di elaborazione automatica. In questo contesto, la codifica video non rappresenterebbe più soltanto una tecnologia di compressione, ma una componente fondamentale dell’interazione tra dati visivi e modelli di intelligenza artificiale.