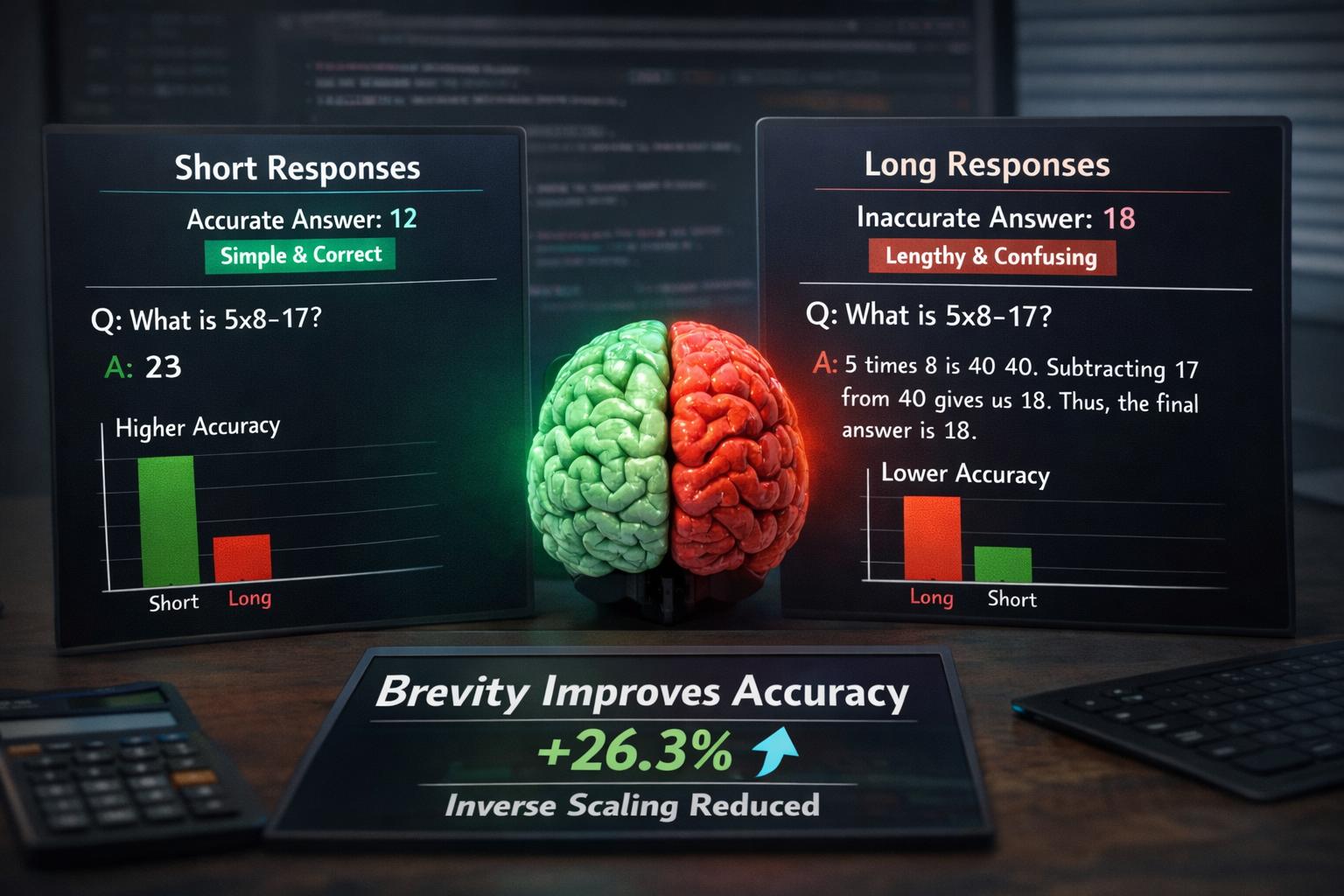
Un recente articolo evidenzia un aspetto controintuitivo ma sempre più rilevante nell’utilizzo dei modelli linguistici di grandi dimensioni: l’aumento della lunghezza delle risposte può ridurre l’accuratezza delle informazioni prodotte. Il lavoro analizzato mostra infatti che imporre ai modelli vincoli di brevità porta, in molti casi, a risultati più corretti e coerenti, suggerendo che l’eccesso di verbosità non sia solo una questione stilistica, ma un fattore tecnico che incide direttamente sulla qualità dell’output.
Lo studio prende in esame 31 modelli linguistici e dimostra che forzare risposte più brevi migliora l’accuratezza fino al 26,3%, riducendo significativamente anche il cosiddetto “inverse scaling”, cioè il fenomeno per cui modelli più grandi ottengono risultati peggiori rispetto a modelli più piccoli in alcuni compiti. La riduzione della lunghezza delle risposte ha inoltre diminuito il divario di prestazioni tra modelli grandi e piccoli di circa due terzi, evidenziando che la verbosità può mascherare capacità latenti dei sistemi più complessi.
Questo comportamento è legato a una dinamica definita come “overthinking” o eccesso di elaborazione. Quando il modello genera molte parole, tende a introdurre spiegazioni aggiuntive, ipotesi alternative e ripetizioni che non migliorano la qualità dell’informazione, ma aumentano la probabilità di inserire errori. In pratica, il messaggio centrale può essere diluito o addirittura compromesso dalla quantità di testo generato, soprattutto nei compiti di ragionamento logico o matematico.
I risultati mostrano che l’effetto è particolarmente evidente in ambiti come la matematica e la comprensione del testo. Nei test citati, ai modelli è stato chiesto di rispondere con meno di 50 parole nei problemi matematici e con meno di 10 parole nelle prove di comprensione, ottenendo un miglioramento significativo della precisione. Ciò suggerisce che l’espansione discorsiva non aiuta il processo di inferenza, ma introduce rumore cognitivo nella generazione.
Il fenomeno non è isolato. Altri studi accademici parlano di “verbosity compensation”, una tendenza dei modelli a produrre risposte più lunghe quando l’incertezza aumenta. Questa strategia, simile a un comportamento umano, consiste nel generare più contenuto nella speranza che parte della risposta sia corretta. Tuttavia, le ricerche dimostrano che le risposte verbose sono associate a maggiore incertezza e a un gap prestazionale significativo rispetto alle versioni concise.
La scoperta ha implicazioni dirette sul prompt engineering. Non è necessario modificare l’architettura del modello per ottenere miglioramenti: basta introdurre vincoli di brevità nel prompt o nei parametri di generazione. Questo approccio agisce come una forma di controllo del ragionamento, limitando la produzione di passaggi intermedi non necessari e riducendo la probabilità di deviazioni semantiche.
Un ulteriore elemento rilevante riguarda la relazione tra lunghezza delle risposte e percezione umana dell’affidabilità. Studi paralleli mostrano che gli utenti tendono a considerare più accurate le risposte più lunghe, anche quando l’accuratezza reale non aumenta. Questo crea un paradosso operativo: l’output più sintetico è spesso più corretto, ma può apparire meno convincente a chi lo legge.
Questa evidenza suggerisce che le interfacce AI dovrebbero separare chiarezza e verbosità. In contesti professionali, come analisi tecniche, supporto decisionale o automazione documentale, risposte più concise possono migliorare la precisione e ridurre i costi computazionali, perché generano meno token e meno latenza. L’effetto è particolarmente importante nei sistemi di produzione, dove la lunghezza delle risposte incide direttamente su tempi di risposta e costi operativi.
Inoltre, la ricerca indica che i modelli più grandi non sono necessariamente meno accurati, ma soffrono maggiormente di verbosità spontanea. Quando questa viene controllata, le loro prestazioni possono superare quelle dei modelli più piccoli, invertendo completamente le gerarchie di performance osservate nei benchmark tradizionali. Questo rafforza l’idea che il problema non sia la capacità del modello, ma il modo in cui viene guidato durante l’inferenza.
Le implicazioni sono rilevanti anche per chi sviluppa contenuti e sistemi basati su AI. L’approccio “più lungo è meglio” non è sempre valido, e in molti casi può essere controproducente. Una progettazione dei prompt orientata alla sintesi, unita a eventuali livelli di approfondimento opzionali, permette di mantenere precisione e leggibilità senza sacrificare la completezza informativa.