È emerso uno studio che sostiene che i modelli linguistici di grandi dimensioni (LLM) comprendono e generano testo, piuttosto che essere “pappagalli probabilistici” che combinano informazioni pre-appresi senza senso.
Quanta Magazine ha riferito che man mano che il LLM cresce e viene formato con più dati, le competenze individuali legate alla lingua migliorano attraverso un sito cartaceo online dei ricercatori dell’Università di Princeton e di Google DeepMind e che non esistono nei dati di formazione combinando le competenze. È stato riferito che è stato pubblicato un documento sullo sviluppo di nuove abilità che non sono ancora disponibili.
In base a ciò, questo articolo suggerisce che LLM non si limita a ripetere a pappagallo ciò che vede nei dati di addestramento, ma comprende e genera il testo che elabora.
I ricercatori hanno utilizzato un oggetto matematico chiamato “grafico casuale” per modellare il comportamento di LLM e hanno scoperto che all’aumentare delle dimensioni del modello o della quantità di dati di addestramento, la perdita del modello sui dati di test diminuisce in un certo modo. La perdita si riferisce alla differenza tra le previsioni per il nuovo testo e la risposta corretta dopo l’allenamento.
Nel grafico, una bassa perdita di test è indicata da una diminuzione della percentuale di nodi di test falliti. Pertanto, ci sono meno nodi di test che complessivamente falliscono.
E quando il numero di nodi di test falliti è piccolo, ci sono anche meno connessioni tra nodi di test falliti e nodi tecnologici. Pertanto, un numero maggiore di nodi tecnici è collegato ai nodi di test di successo, indicando che le capacità tecniche del modello sono migliorate. Questo è il motivo per cui i LLM più grandi sono più competenti nelle competenze linguistiche individuali rispetto ai LLM più piccoli.
“Una riduzione molto piccola delle perdite aumenta la capacità delle macchine di acquisire queste competenze”, ha affermato Anirudh Goyal, ricercatore presso Google DeepMind.
Secondo i ricercatori, man mano che la dimensione del LLM aumenta e la perdita di test diminuisce, le persone diventano più abili nell’usare più di una tecnica alla volta e iniziano a utilizzare più tecniche per generare testo. Sosteniamo che ciò si traduce in una combinazione di abilità, il che è la prova che LLM non si basa esclusivamente sulla combinazione di abilità osservate nei dati di formazione.
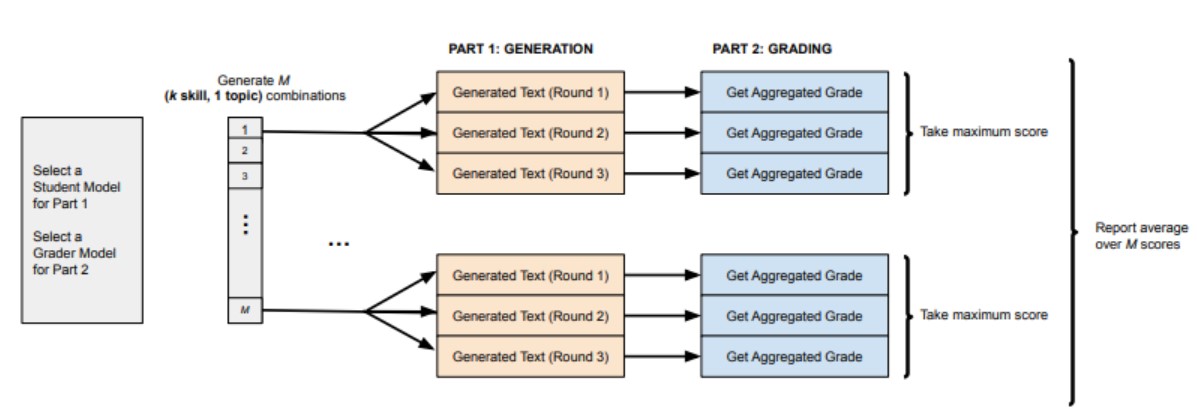
I ricercatori hanno testato la loro teoria utilizzando un metodo chiamato “skill-mix” per valutare la capacità di LLM di generare testo utilizzando una varietà di competenze e hanno scoperto che il modello funzionava esattamente come previsto.
In conclusione, la spiegazione è che LLM può generare testo che non sarebbe stato visto nei dati di addestramento e che questa è una tecnologia che può essere definita “comprensiva”.
“Ciò che abbiamo dimostrato teoricamente e confermato empiricamente è che il LLM può generalizzare e combinare tecniche, piuttosto che limitarsi a replicare ciò che abbiamo visto in precedenza nei dati di addestramento”, ha affermato Sanjiv Arora, professore di informatica all’Università di Princeton. “È l’essenza della creatività ,” Egli ha detto.
Nel caso di “GPT-4”, è noto anche per generare testo combinando competenze e argomenti in modi che quasi certamente non si sono verificati nei dati di addestramento, ad esempio risolvendo alcuni problemi di matematica.