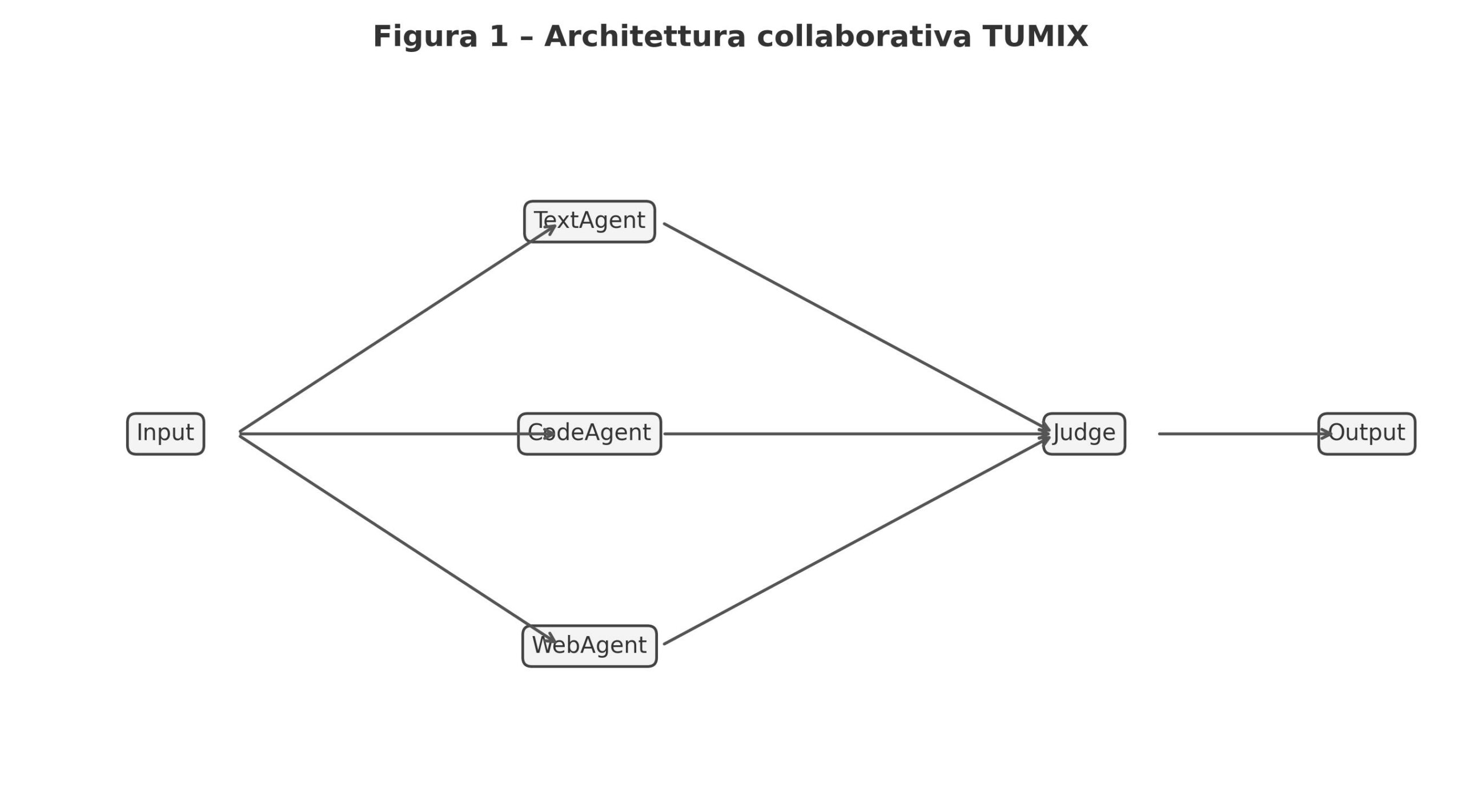
TUMIX (Tool-Use Mixture) è un framework proposto da Google DeepMind in collaborazione con MIT e Harvard che organizza diversi agenti specializzati – ognuno con modalità d’azione (tool-use, codice, ricerca, ragionamento testuale) – che lavorano insieme in rounds iterativi, condividendo ragionamenti intermedi e affinando le proprie risposte. L’obiettivo è ottenere una risposta finale più accurata, spendendo meno risorse rispetto al semplice “campionamento massivo” di un singolo modello.
Il flusso tipico in TUMIX parte da una domanda: tutti gli agenti ricevono quella richiesta e producono una prima risposta secondo il proprio metodo (alcuni “solo testo”, altri soluzioni che generano/eseguono codice, altri che cercano sul web). Poi, nelle iterazioni successive, ogni agente osserva non solo la domanda originaria ma anche le risposte degli altri agenti nei round precedenti, e rielabora la propria proposta tenendo conto delle idee emerse. A ogni round uno strato “giudice” (spesso un’istanza LLM) valuta se la convergenza è sufficiente: se sì, si interrompe e si produce la risposta definitiva, altrimenti si procede con un nuovo round.
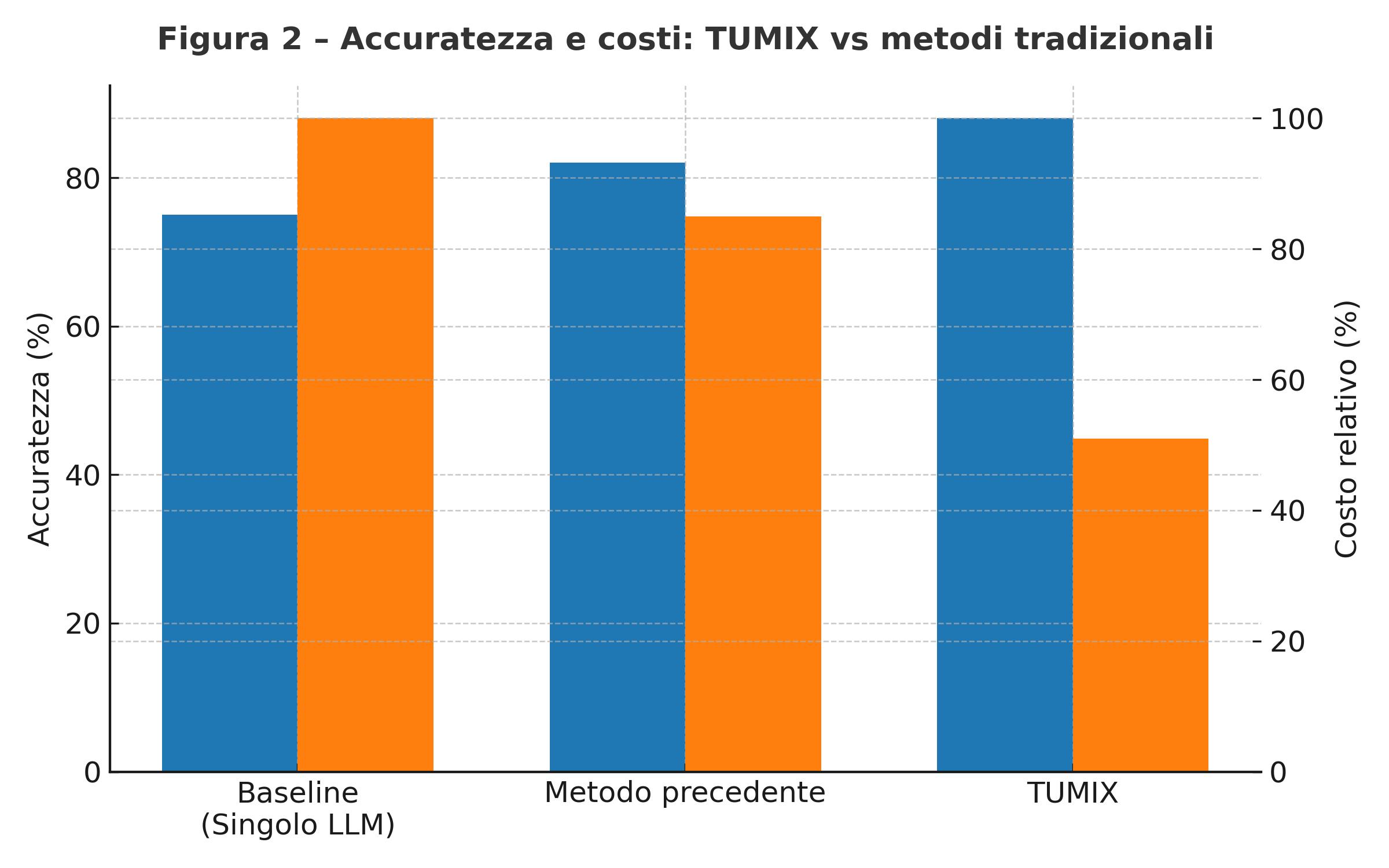
Uno dei punti di forza è il meccanismo di early termination: non sempre serve spingere all’infinito la rifinitura. Se già al quarto/quinto round la maggioranza delle risposte converge con sufficiente fiducia, TUMIX può chiudere il processo per non continuare a spendere token e calcolo inutilmente. In tal modo, il costo effettivo dell’inferenza — in termini di token, modelli invocati e tool usati — può restare contenuto, spesso intorno al 49 % del costo che ci si aspetterebbe da metodi seriali o brute force analoghi.
Nel paper, i ricercatori mostrano come l’approccio abbia un “sweet spot” attorno a 12–15 stili di agente: aggiungerne molti di più non porta guadagni proporzionali in accuratezza, ma aumenta rapidamente la complessità, il sovraccarico di comunicazione interna e il costo totale dell’inferenza.
Per chiarire visivamente, l’immagine che ho inserito sopra mostra un tipo di architettura “multi-agent orchestrated”: un prompt iniziale che viene distribuito ai vari agenti, ciascuno con un “ruolo” diverso (codice, ragionamento, ricerca, ecc.), e uno strato di coordinamento in cui i risultati intermedi vengono incrociati e raffinati. Pur non essendo il disegno specifico di TUMIX, illustra bene lo spirito architetturale: non agenti isolati, ma cooperanti.
Per apprezzare l’innovazione di TUMIX, è utile metterlo accanto ad altri metodi noti nel mondo dell’inferenza e del “scaling” dei modelli:
- Con il campionamento multiplo (ad esempio, chiedere più volte allo stesso modello di generare risposte casuali e poi scegliere quella migliore), si aumenta la probabilità di trovare una risposta corretta, ma si ripete lo stesso ragionamento, senza varietà metodologica.
- L’ensemble di modelli simili (ad esempio, versioni diverse dello stesso LLM) è un altro approccio: più modelli, stessa modalità, voto o aggregazione. È utile, ma rischia ridondanze e mancanza di diversità.
- Alcuni metodi come Self-MoA, Symbolic-MoE, DEI, SciMaster, GSA (citati nel paper) tentano ibridi tra modelli e strumenti o stratificazioni di competenze, ma spesso restano ancorati a strategie ripetitive o modelli con tool, senza coordinazione raffinata tra agenti.
In confronto, TUMIX introduce due elementi distintivi:
- Diversità strutturata: non si tratta solo di più risposte, ma di risposte generate con strategie diverse, sfruttando modalità che spaziano dal codice alla ricerca, passando per ragionamento puro.
- Comunicazione e raffinamento iterativo: gli agenti “parlano” tra loro — condividono ciò che hanno prodotto, valutano criticamente le proposte altrui e migliorano le proprie risposte. L’approccio cooperativo rende possibile convergere su soluzioni che nessun agente da solo avrebbe trovato.
Nei risultati pratici, applicando TUMIX a modelli come Gemini-2.5 Pro e Gemini-2.5 Flash, i ricercatori hanno ottenuto incrementi interessanti: nel benchmark Humanity’s Last Exam (HLE) il modello Pro è salito dal 21,6 % al 34,1 % di accuratezza; per Flash da 9,7 % a 23,1 %. In altri test come GPQA-Diamond e AIME 2024/25, i punteggi raggiunti da Pro superano l’88 % in alcune configurazioni. Complessivamente, l’aumento medio rispetto al miglior metodo precedente è circa 3,55 % in più di accuratezza, restando con un costo inferiore.
Un dato cruciale è che, rispetto a modelli che non usano metodi di scaling (cioè un singolo passaggio standard), TUMIX mostra guadagni del 7,8 % (per Pro) fino al 17,4 % (per Flash). In altre parole, la collaborazione fra agenti produce benefici anche rispetto a scenari “base” senza sofisticazioni.
È interessante anche la parte in cui l’LLM stesso può generare nuovi agenti “automatici”, mescolandoli con gli agenti progettati dall’uomo per ottenere una performance extra (circa +1,2 %) senza costi aggiuntivi. In questo modo, il sistema non è vincolato solo alla varietà definita a priori, ma può evolversi autonomamente.
Infine, il termine “costo” in questi confronti non è solo economico, ma computazionale: riguarda quanti token vengono elaborati, quanti modelli o tool vengono invocati, quanto tempo e quante risorse hardware si consumano. Grazie al meccanismo di interruzione anticipata e alla diversificazione ragionata, TUMIX riesce a ottenere guadagni mantenendo il bilancio delle risorse favorevole.