Il crescente utilizzo dei modelli linguistici di grandi dimensioni sta mettendo sotto pressione l’infrastruttura su cui si basa l’intelligenza artificiale moderna. L’inferenza dei LLM, cioè il processo con cui questi modelli generano risposte e contenuti, è oggi fortemente concentrata nei data center, con costi elevati legati a GPU potenti, consumo energetico e larghezza di banda. In questo contesto si inserisce la nuova tecnologia annunciata dal Korea Advanced Institute of Science and Technology, che propone un cambio di paradigma nel modo in cui i servizi di intelligenza artificiale possono essere distribuiti e resi sostenibili.
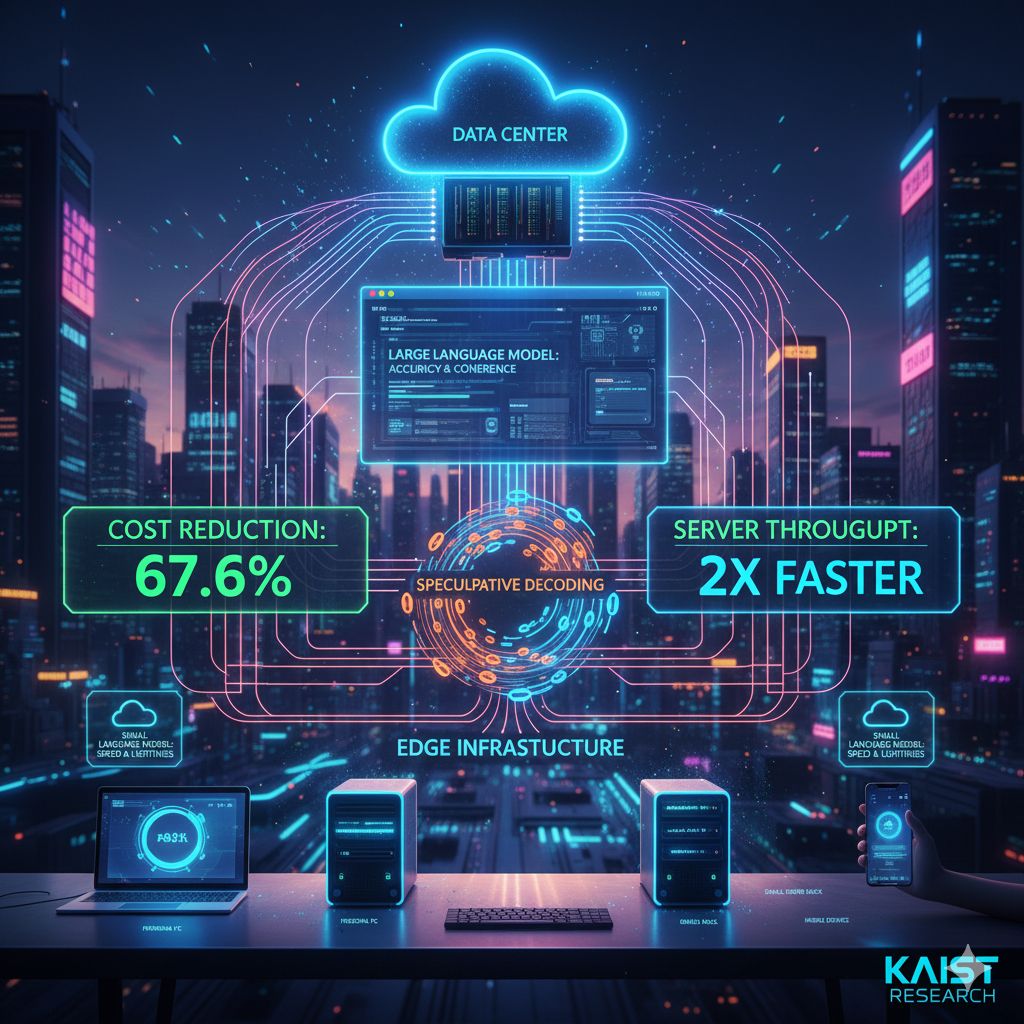
Il team di ricerca guidato dal professor Dong-Soo Han del Dipartimento di ingegneria elettrica ed elettronica ha sviluppato una tecnologia chiamata SpecEdge, pensata per ridurre in modo significativo i costi dell’inferenza LLM sfruttando infrastrutture alternative ai tradizionali data center. Invece di affidare tutto il carico computazionale a grandi server centralizzati, SpecEdge distribuisce il lavoro tra le GPU dei data center e le GPU edge, come quelle presenti nei PC personali, nei piccoli server e, in prospettiva, anche nei dispositivi mobili.
Il principio alla base di SpecEdge è la separazione intelligente dei ruoli tra modelli e hardware differenti. I modelli linguistici di grandi dimensioni restano nel data center, dove mantengono il compito di garantire accuratezza e coerenza delle risposte. All’edge, invece, operano modelli linguistici più piccoli, ottimizzati per velocità e leggerezza, che anticipano il lavoro generando sequenze di token altamente probabili. Questo approccio permette di alleggerire il carico sul data center e di ridurre drasticamente il numero di operazioni costose eseguite sulle GPU più potenti.
Il meccanismo tecnico che rende possibile questa architettura è la cosiddetta decodifica speculativa. In pratica, il modello più piccolo installato sull’edge produce rapidamente una serie di possibili token senza dover attendere una risposta dal server centrale. Queste proposte vengono poi inviate al data center, dove il modello linguistico di grandi dimensioni le verifica in blocco. Se la sequenza risulta valida, viene accettata immediatamente; in caso contrario, il sistema corregge e procede con nuove proposte. Il risultato è un flusso continuo di generazione che riduce le attese e migliora l’utilizzo complessivo delle risorse.
Secondo i dati forniti dal team di ricerca, questo approccio consente di ridurre del 67,6% il costo di generazione di un singolo token rispetto ai metodi tradizionali basati esclusivamente su GPU da data center. Non solo: anche confrontando SpecEdge con altre soluzioni di decodifica speculativa eseguite interamente nei data center, l’efficienza economica risulta quasi raddoppiata, mentre la velocità di trasmissione del server aumenta di oltre due volte. Questi numeri indicano che il beneficio non è solo teorico, ma si traduce in miglioramenti concreti sia in termini di costi sia di prestazioni.
Un aspetto particolarmente rilevante è che SpecEdge funziona efficacemente anche con le normali velocità di connessione Internet. Non richiede reti dedicate o ambienti di comunicazione specializzati, rendendo la tecnologia immediatamente applicabile ai servizi reali. Questo elemento è cruciale per una diffusione su larga scala, perché elimina uno dei principali ostacoli all’adozione di architetture distribuite basate sull’edge computing.
Dal punto di vista dell’infrastruttura server, il sistema è progettato per gestire in modo efficiente le richieste di verifica provenienti da molteplici GPU edge contemporaneamente. Il server centrale non resta inattivo in attesa di singole richieste, ma lavora in modo continuo e parallelo, massimizzando l’utilizzo delle GPU del data center. In questo modo si realizza un modello di servizio LLM più bilanciato, in cui le risorse costose vengono sfruttate in maniera ottimale e quelle diffuse sul territorio contribuiscono attivamente al processo di inferenza.
Il significato più ampio di questa ricerca va oltre il semplice risparmio economico. Distribuire l’elaborazione dei modelli linguistici dall’infrastruttura centralizzata all’edge apre la strada a un’intelligenza artificiale più accessibile e meno dipendente da grandi investimenti in data center. In prospettiva, questo potrebbe favorire la nascita di servizi AI avanzati fruibili anche da utenti e organizzazioni che oggi non possono sostenere i costi delle soluzioni centralizzate.
Il professor Han Dong-soo ha sintetizzato questa visione affermando che l’obiettivo è utilizzare le risorse edge degli utenti, insieme ai data center, come vera e propria infrastruttura per i modelli linguistici. Guardando al futuro, il team prevede che SpecEdge possa estendersi a dispositivi edge sempre più diffusi, come smartphone, personal computer e NPU dedicate, ampliando ulteriormente la platea di utenti in grado di accedere a servizi di intelligenza artificiale di alta qualità.