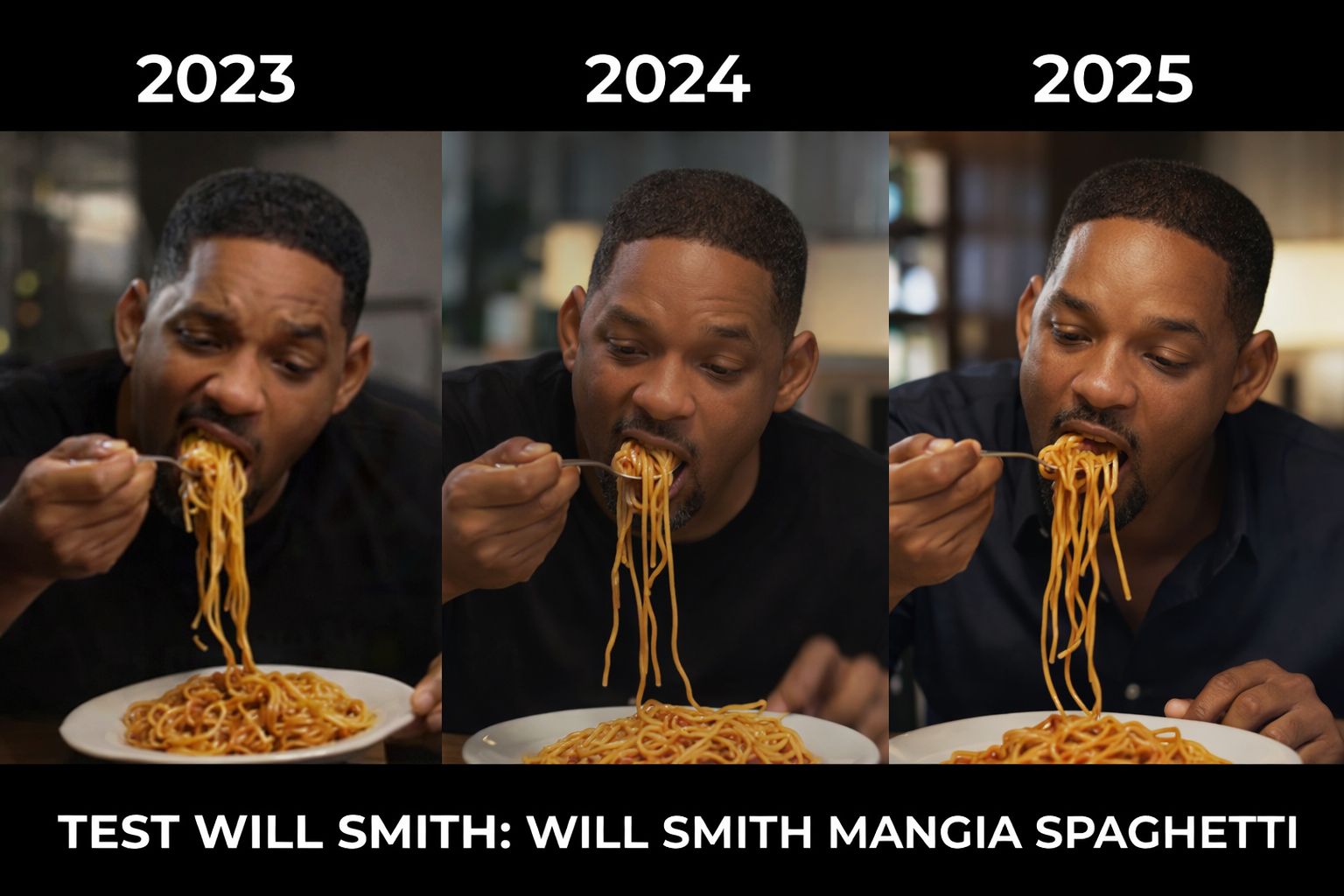
Negli ultimi anni la generazione automatica di video tramite intelligenza artificiale è passata da una curiosità tecnologica a un campo di sviluppo concreto e rapidamente in evoluzione, grazie ai progressi nei modelli di sintesi visiva e audio combinati. Un esempio che sintetizza bene questo percorso è l’«esperimento» informale ormai noto come Test Will Smith: Will Smith mangia gli spaghetti, un meme diventato virale che negli ambienti della AI community funziona come benchmark non ufficiale per valutare la capacità dei sistemi di generare sequenze video realistiche e coerenti partendo da un prompt testuale. Nato come clip grottesca e innaturale, questo caso rappresenta un utile punto di osservazione per comprendere quanto siano progrediti i modelli di intelligenza artificiale che generano contenuti video negli ultimi tre anni.
Il fenomeno affonda le radici in un video generato con modelli text-to-video basati su tecnologie emergenti di deep learning, pubblicato su Reddit nel marzo del 2023 da un utente con nickname chaindrop e raffigurante l’attore mentre mangia spaghetti. Quel primo tentativo, realizzato con l’ausilio di strumenti come Stable Diffusion o ModelScope, si distingueva per un realismo estremamente basso: il volto dell’attore si deformava irregolarmente da un fotogramma all’altro, i movimenti delle mani e della bocca non rispettavano la fisica e persino gli spaghetti si comportavano come oggetti privi di consistenza fisica. La qualità complessiva era tale che molti commentatori sui social definirono il risultato inquietante anziché convincente.
La presenza di questo meme nella cultura digitale non è stata solo aneddotica: l’evoluzione delle versioni generate, anno dopo anno, è diventata una sorta di “termometro” informale per misurare i miglioramenti nelle architetture video generative. Nel corso del 2024 l’output di tali modelli iniziò a mostrare progressi evidenti rispetto agli esempi primitivi. Se le deformazioni e le incoerenze tra fotogrammi non scomparvero del tutto, la scena divenne gradualmente più coerente, con movimenti meno caotici e una maggiore stabilità delle caratteristiche del volto e della postura dell’attore.
I progressi si sono concretizzati in modo ancora più evidente nel 2025, quando modelli di sintesi video di nuova generazione — tra cui Veo 3 di Google — hanno prodotto versioni del test in cui l’espressione facciale, la fisica degli oggetti e la fluidità del movimento apparivano sorprendentemente realistiche, tanto da rendere difficile per osservatori non esperti distinguere il contenuto generato dall’IA da un filmato girato con attori reali. Queste iterazioni sono state condivise in compilation che mostrano l’evoluzione anno per anno, consentendo un confronto diretto e visivo dei progressi ottenuti nell’ambito della generazione video automatica.
Nel 2026 il test è arrivato a includere non solo immagini più realistiche, ma anche audio sincronizzato generato artificialmente, un elemento aggiuntivo che rappresenta una sfida significativa per la tecnologia di generazione multimodale. In alcune delle versioni più recenti, la scena non si limita a una singola ripresa, ma utilizza tecniche di illuminazione più sofisticate, inquadrature curate e una sceneggiatura implicita che conferisce un tono cinematografico al video. Questo salto qualitativo riflette miglioramenti nei modelli di text-to-video che integrano moduli di sintesi del parlato, motore fisico simulato e reti neurali avanzate in grado di mantenere la coerenza delle caratteristiche del soggetto attraverso sequenze di fotogrammi.
L’uso di un meme come standard informale di riferimento può sembrare bizzarro, ma sul piano tecnico funge da microbenchmark per vari aspetti della generazione video: la stabilità dell’identità visiva del soggetto, la dinamica dei movimenti, la coerenza delle superfici e delle interazioni fisiche e la sincronizzazione labiale con l’audio. In sostanza, ogni versione di questo test porta con sé una serie di indicatori sulle capacità specifiche dei modelli, simili a come nelle reti neurali per immagini si utilizzano dataset di riferimento per misurare accuratezza, fedeltà e realismo.
Il fatto che questo test sia diventato parte del lessico della comunità AI riflette la rapidità con cui la generazione video automatica sta diventando una tecnologia significativa. A differenza di generazioni di immagini statiche, che si sono sviluppate prima e hanno raggiunto livelli di realismo elevati ormai da anni, la generazione video richiede la padronanza di sfide aggiuntive come continuità temporale, simulazione della fisica e generazione audio coerente. Il Test Will Smith, per quanto informale o ironico possa apparire, fornisce una narrazione intuitiva di questi progressi, mettendo in evidenza quanto i modelli si siano evoluti da risultati naif a sequenze complesse che possono avvicinarsi a produzioni simulate con tecniche cinematografiche.
Questa evoluzione non è priva di implicazioni tecniche e sociali. Dal punto di vista della ricerca, mostra come la comunità stia spostando l’attenzione da semplici fotogrammi generati in isolamento a video completi con caratteristiche dinamiche complesse. Dal punto di vista dell’etica e dell’uso reale, solleva discussioni sulla distinzione tra contenuto generato artificialmente e realtà documentata, sulla potenziale facilità con cui materiale sintetico potrebbe essere scambiato per autentico e sulle necessità di meccanismi di watermarking o di tracciabilità dei contenuti generati dall’IA.