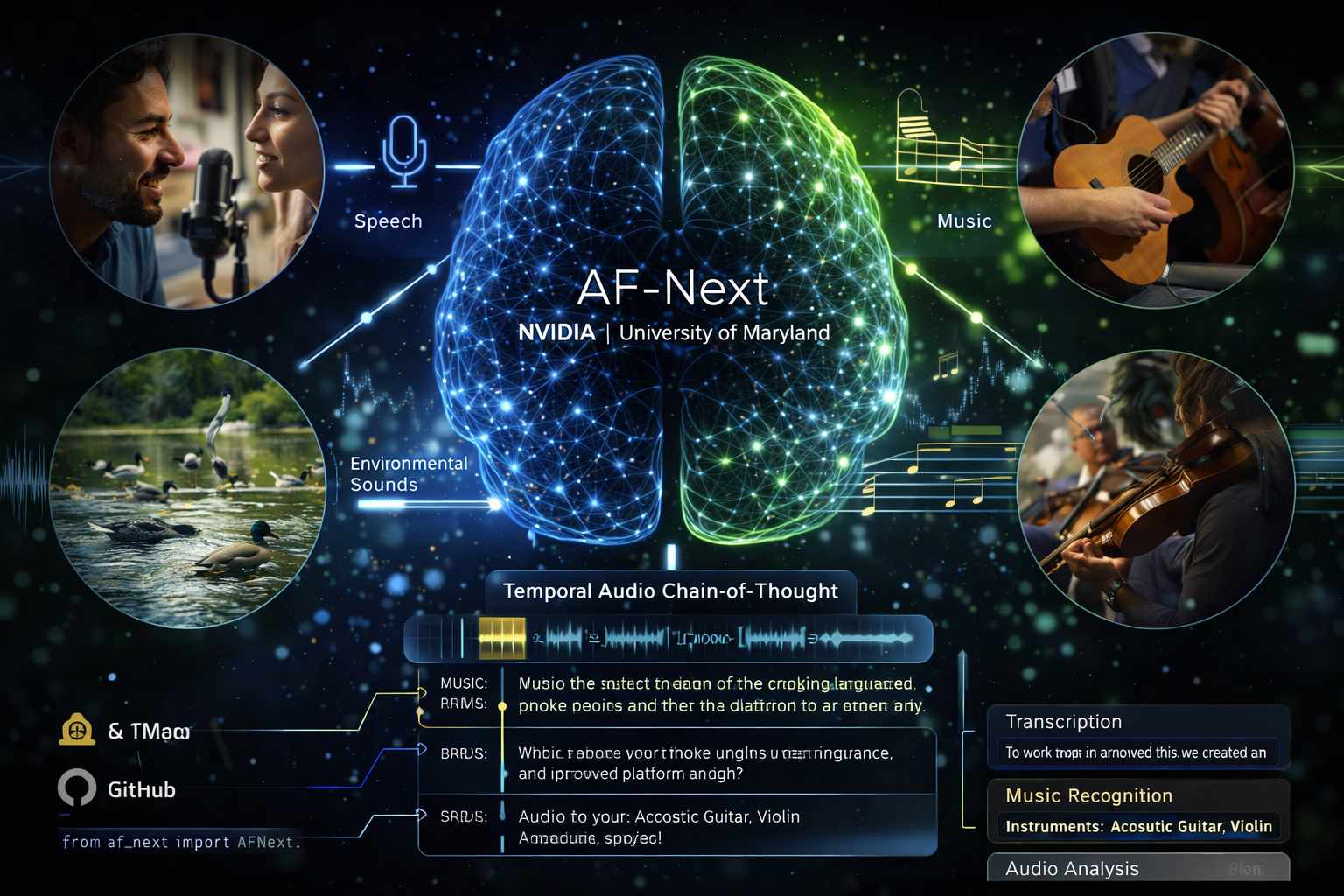
L’intelligenza artificiale nel dominio acustico ha raggiunto un nuovo traguardo con la presentazione di AF-Next (Audio Flamingo Next), un modello audio-linguistico di grandi dimensioni (LALM) sviluppato da NVIDIA in collaborazione con i ricercatori dell’Università del Maryland. Questa tecnologia segna il passaggio da sistemi specializzati in singoli compiti verso un’architettura unificata open-source capace di processare simultaneamente parlato, suoni ambientali e composizioni musicali. A differenza degli approcci tradizionali, che richiedevano l’impiego di modelli distinti per il riconoscimento vocale e l’analisi della musica, AF-Next integra queste funzioni in un unico framework, applicando al suono una logica di elaborazione simile a quella che i modelli multimodali utilizzano per le immagini e il testo.
L’ossatura del modello poggia su una combinazione sofisticata di componenti specializzati. Il sistema utilizza AF-Whisper, un’estensione del noto codificatore audio Whisper, accoppiato a un adattatore che funge da ponte tra le informazioni acustiche estratte e un modello linguistico con 7 miliardi di parametri. Una delle innovazioni strutturali più rilevanti è l’implementazione del Rotating Time Embedding (RoTE), una tecnica che incorpora le coordinate temporali direttamente nel processo di analisi. Questo permette al modello di non percepire l’audio come una sequenza statica di dati, ma come un flusso dinamico in cui la posizione di ogni evento sonoro è contestualizzata cronologicamente, facilitando una comprensione profonda della narrazione audio.
La gestione della dimensione temporale rappresenta il principale elemento di rottura rispetto alle generazioni precedenti. AF-Next è progettato per analizzare clip audio che si estendono fino a 30 minuti, superando i limiti dei modelli addestrati su brevi campioni. Per gestire tale complessità, è stato introdotto il metodo denominato Catena di pensiero audio temporale (Temporal Audio Chain-of-Thought). Questa funzione consente al modello di articolare il proprio ragionamento in fasi distinte, collegando ogni deduzione a momenti precisi del file audio. Tale approccio non solo aumenta la precisione nell’individuazione delle prove acustiche all’interno di registrazioni estese, ma riduce drasticamente il rischio di allucinazioni, fornendo una tracciabilità costante tra l’output testuale e la sorgente sonora originale.
L’addestramento del modello ha richiesto una mole di dati senza precedenti, con l’utilizzo di circa 108 milioni di campioni e oltre un milione di ore di materiale audio proveniente da scenari del mondo reale, tra cui film, conversazioni spontanee, video di lunga durata e brani musicali. Questa vasta base di conoscenza ha permesso di ottimizzare il modello in tre varianti specifiche: Instruct, dedicata alla risposta a domande generali; Think, specializzata nel ragionamento logico a più fasi; e Captioner, focalizzata sulla generazione di descrizioni testuali dettagliate del panorama sonoro. L’efficacia di questo addestramento è confermata dai risultati dei benchmark, dove AF-Next ha mostrato prestazioni superiori a modelli proprietari di alto livello, eccellendo in particolare nel riconoscimento vocale multi-parlante e nella classificazione degli strumenti musicali.
L’apertura del codice e dei pesi del modello su piattaforme come HuggingFace e GitHub sottolinea la volontà di NVIDIA di promuovere una scalabilità diffusa dell’intelligenza artificiale audio. Superando la frammentazione dei task acustici, AF-Next si propone come una piattaforma versatile per lo sviluppo di applicazioni industriali e creative, che spaziano dalla trascrizione intelligente di lunghi convegni alla catalogazione automatica di archivi musicali complessi, stabilendo un nuovo standard per l’interazione uomo-macchina mediata dal suono.