YouTube sta evolvendo la propria infrastruttura di moderazione e classificazione dei contenuti attraverso una nuova pipeline end-to-end basata su Large Language Model, progettata per gestire l’enorme volume di video caricati quotidianamente sulla piattaforma. Il sistema è stato sviluppato all’interno del team engineering di Google da Jonghyun Jeong, ingegnere software specializzato in data infrastructure e machine learning applicato ai sistemi su larga scala.
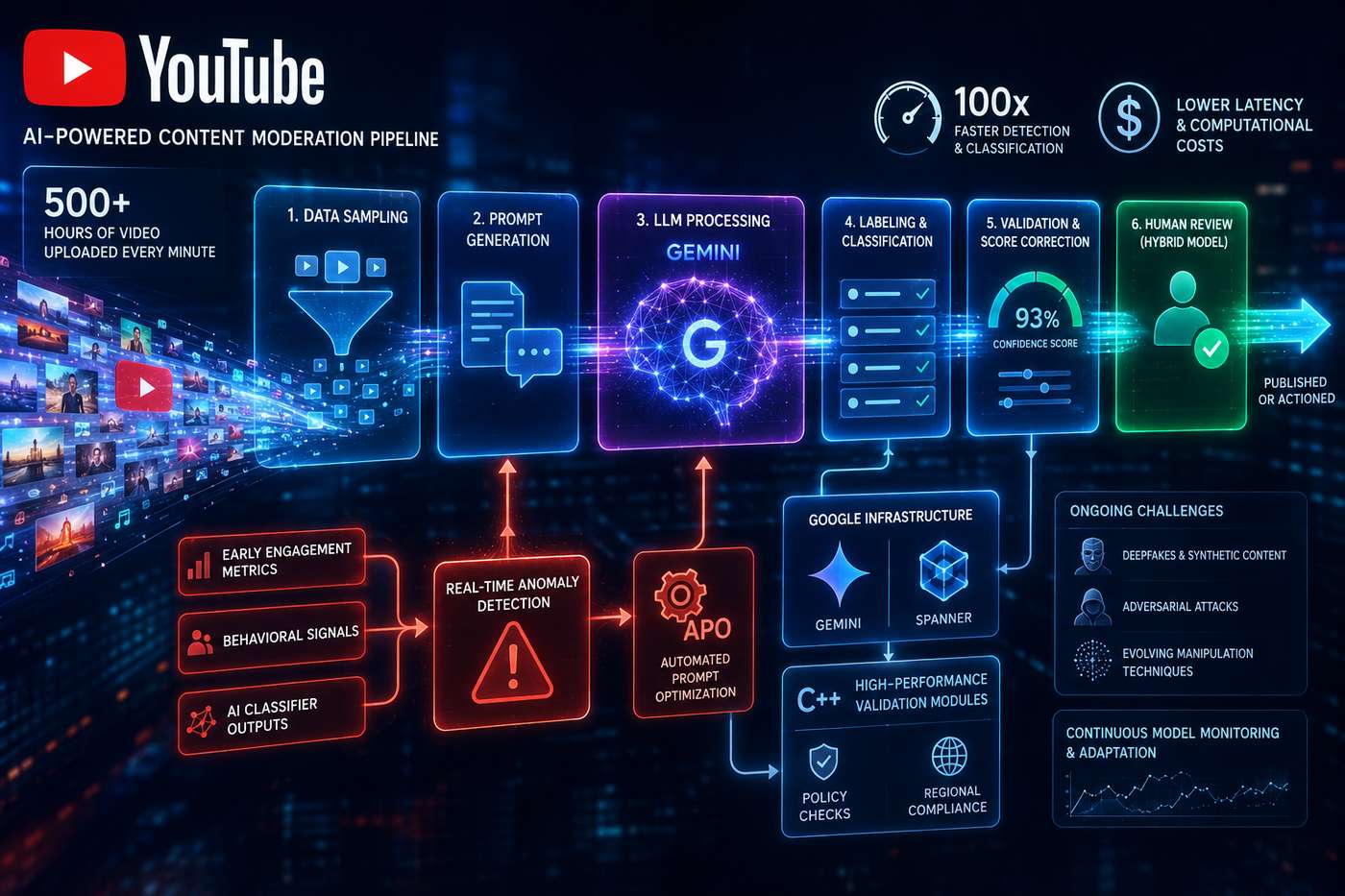
La sfida affrontata da YouTube è legata alle dimensioni estreme della piattaforma. Con oltre 500 ore di video caricate ogni minuto, i tradizionali sistemi di revisione manuale e i classificatori basati esclusivamente su reti neurali profonde non risultavano più sufficienti in termini di costi, velocità e scalabilità operativa.
La nuova architettura introduce una pipeline integrata che utilizza modelli linguistici avanzati per classificare, etichettare e analizzare automaticamente grandi quantità di contenuti video. Il sistema copre l’intero flusso operativo, dal campionamento dei dati alla generazione dei prompt per il modello, fino alla validazione delle etichette e alla correzione automatica dei punteggi di classificazione.
Secondo quanto condiviso dal team, il nuovo framework avrebbe ridotto di oltre 100 volte la velocità di rilevamento e classificazione dei contenuti rispetto ai sistemi precedenti, abbattendo contemporaneamente latenza e costi computazionali. Il miglioramento deriva principalmente dalla capacità degli LLM di comprendere il contesto semantico dei contenuti in maniera più flessibile rispetto ai classificatori statici tradizionali.
Uno degli elementi centrali della piattaforma è il sistema di anomaly detection in tempo reale. Subito dopo il caricamento di un video, la pipeline analizza metriche iniziali di engagement, segnali comportamentali e output dei classificatori AI per individuare rapidamente eventuali contenuti potenzialmente problematici. In presenza di segnali di rischio, viene attivato automaticamente un sistema di APO (Automated Prompt Optimization) che modifica dinamicamente i prompt utilizzati dal modello per accelerare e affinare la classificazione del contenuto.
Il progetto sfrutta direttamente tecnologie interne di Google, tra cui il modello Gemini e il database distribuito Spanner. Questa combinazione consente di eseguire inferenza AI e gestione dei dati su scala globale mantenendo tempi di risposta compatibili con i requisiti operativi della piattaforma.
Per ottimizzare ulteriormente le prestazioni, il team ha integrato moduli di validazione ad alte prestazioni sviluppati in C++, utilizzati per effettuare controlli preventivi relativi a policy regionali e vincoli normativi specifici. Questo approccio riduce il numero di elaborazioni inutili e limita il consumo di risorse computazionali prima che il contenuto venga analizzato completamente dagli LLM.
Nonostante l’elevato livello di automazione, YouTube continua a mantenere un modello ibrido uomo-macchina. Le decisioni finali più sensibili vengono infatti prese combinando i risultati generati dal sistema AI con verifiche effettuate da revisori umani, aumentando affidabilità e controllo qualitativo.
Rimangono però aperte diverse problematiche, soprattutto legate ai deepfake e ai contenuti sintetici avanzati. Con il rapido miglioramento delle tecnologie generative, diventa sempre più difficile verificare autenticità e integrità dei contenuti, aumentando il rischio di utilizzi malevoli e attacchi avversariali progettati per aggirare i sistemi di classificazione automatica.
Per affrontare questi scenari, il team di YouTube sta sviluppando framework capaci di monitorare continuamente l’affidabilità dei modelli e adattarsi dinamicamente all’evoluzione dei dati e delle tecniche di manipolazione dei contenuti. L’obiettivo dichiarato è costruire un’infrastruttura di governance AI proattiva, in grado di intervenire prima che contenuti problematici si diffondano su larga scala.