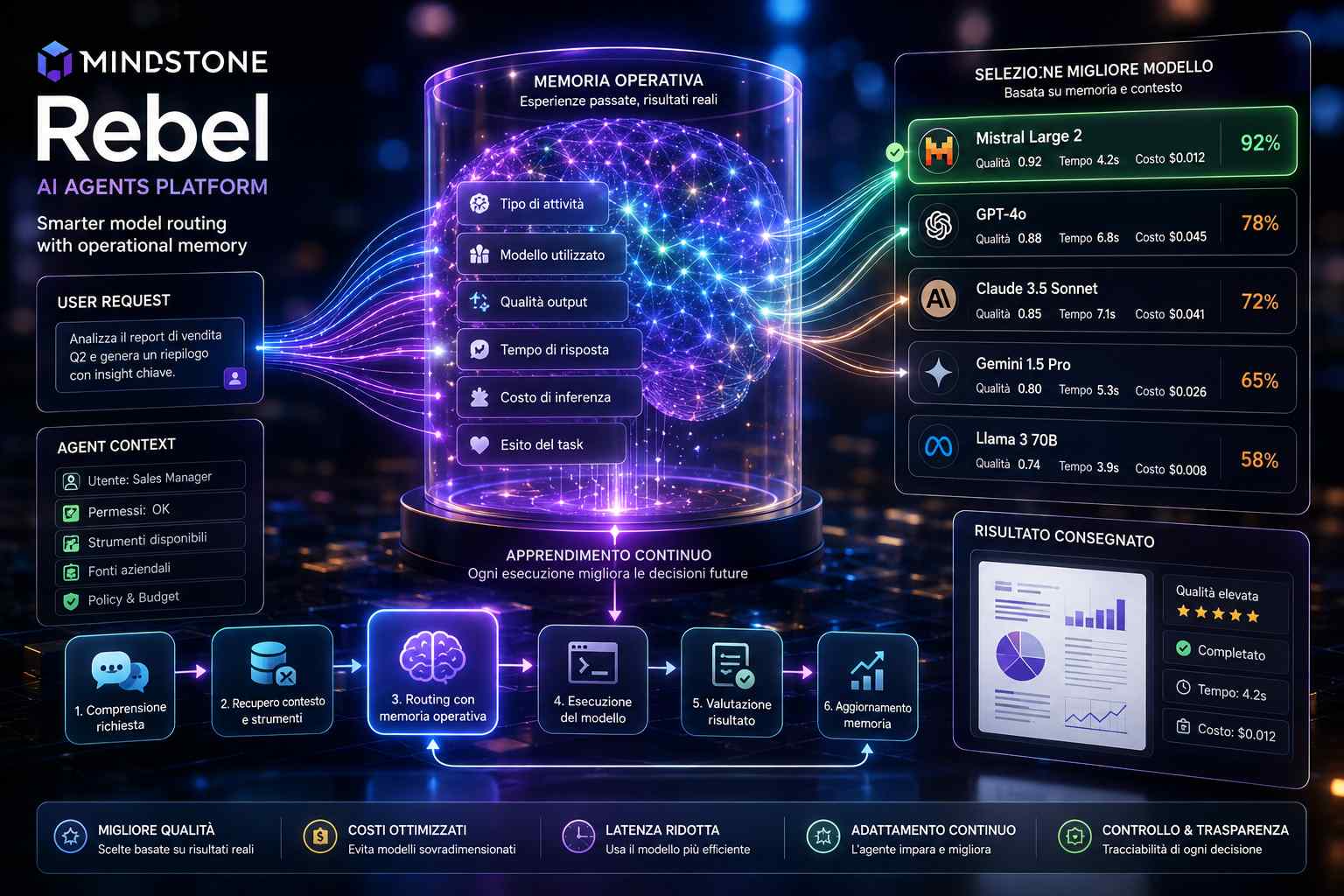
Mindstone ha introdotto in Rebel una funzione di memoria operativa dedicata alla selezione dei modelli linguistici, pensata per evitare che gli agenti aziendali debbano valutare da zero quale LLM utilizzare a ogni nuova richiesta. Il sistema conserva infatti il risultato delle esecuzioni precedenti e associa tipi di attività, contesto, qualità dell’output, tempi di risposta e costo del modello utilizzato, creando nel tempo una base di esperienza che può orientare le decisioni successive.
Nelle architetture multi-modello, la scelta dell’LLM viene spesso affidata a regole statiche. Un task di sintesi può essere inviato a un modello leggero, una richiesta complessa a un modello più costoso, mentre le attività di coding, analisi documentale o recupero di dati vengono instradate verso endpoint configurati manualmente. Questo approccio funziona quando i flussi sono prevedibili, ma tende a perdere efficacia quando un agente deve lavorare su documenti interni, strumenti aziendali, processi ripetitivi e richieste formulate in modi diversi da utenti diversi.
Rebel introduce un routing basato sulla memoria delle prestazioni osservate. Dopo avere completato un’attività, il sistema può registrare quali strumenti sono stati utilizzati, quale modello ha prodotto il risultato, se il task è stato completato correttamente, quanto tempo è stato necessario e quale costo di inferenza è stato sostenuto. Quando l’agente incontra una richiesta simile, non deve limitarsi a classificare il prompt in base alla sua lunghezza o complessità apparente: può recuperare esperienze precedenti e utilizzare il modello che ha dimostrato di funzionare meglio in quello specifico contesto.
La logica è rilevante soprattutto nei casi in cui il modello più potente non è necessariamente quello più efficiente. Un LLM di fascia alta può essere utile per attività che richiedono ragionamento complesso, interpretazione di documenti ambigui, pianificazione multi-step o generazione di codice articolato, ma può risultare sovradimensionato per classificazioni, estrazioni strutturate, risposte basate su procedure interne, sintesi ricorrenti o recupero di informazioni da fonti già indicizzate. La memoria di Rebel consente di associare queste differenze non soltanto a categorie generiche di task, ma all’esperienza reale maturata all’interno dell’organizzazione.
Il routing può quindi considerare variabili che normalmente restano separate. La qualità dell’output viene confrontata con il costo, la latenza e il tasso di completamento del compito; il modello scelto non deve essere soltanto capace di generare una risposta plausibile, ma deve dimostrare di essere adatto al livello di affidabilità richiesto da quella procedura. In una piattaforma aziendale, questa distinzione è importante perché molte attività non vengono valutate soltanto sulla qualità linguistica del testo prodotto, ma sulla correttezza di campi estratti, sull’esecuzione di un workflow, sulla capacità di interrogare un sistema esterno o sulla conformità a regole interne.
La memoria non sostituisce completamente i criteri di routing in tempo reale. Un agente deve continuare a considerare il contenuto della richiesta, le autorizzazioni dell’utente, la disponibilità degli strumenti, le politiche di sicurezza e i limiti di spesa. Il vantaggio della funzione introdotta da Mindstone consiste nell’aggiungere una componente storica: l’agente può utilizzare risultati precedenti per ridurre tentativi inutili, evitare di inviare compiti semplici a modelli costosi e riconoscere quando un modello economico ha già dato risultati insufficienti per quella particolare classe di attività.
L’approccio permette anche di distinguere tra modelli apparentemente simili. Due LLM possono produrre risposte di qualità comparabile su domande generiche, ma comportarsi in modo molto diverso quando devono usare strumenti, rispettare un formato JSON, estrarre dati da documenti aziendali, seguire una procedura di approvazione oppure mantenere coerenza tra più passaggi. La memoria di routing può registrare queste differenze operative e usarle per evitare una selezione basata soltanto su benchmark generali o su parametri dichiarati dal fornitore.
All’interno di Rebel, la funzione si inserisce in un’architettura che collega agenti AI, strumenti aziendali, contesto operativo e processi di lavoro. Il modello non viene quindi selezionato in astratto, ma nel momento in cui deve svolgere un’azione concreta: consultare una fonte, classificare una richiesta, preparare un documento, eseguire un controllo, aggiornare un sistema o supportare una procedura interna. La scelta del modello diventa parte della memoria dell’agente, insieme alle informazioni necessarie per comprendere il lavoro dell’organizzazione.
Per le aziende che utilizzano più fornitori e più modelli, questa impostazione può ridurre la dipendenza da configurazioni manuali che devono essere aggiornate ogni volta che cambia il listino di un’API, viene introdotto un nuovo modello o emergono differenze di prestazione su un workflow specifico. Invece di definire una volta per tutte che un determinato LLM debba occuparsi di una categoria di richieste, Rebel può costruire una preferenza basata sui risultati effettivamente ottenuti nel tempo.
La novità proposta da Mindstone non riguarda quindi solo l’instradamento dei prompt, ma l’uso della memoria come livello decisionale per l’orchestrazione multi-modello. L’agente conserva l’esperienza acquisita su compiti precedenti e la utilizza per scegliere, con maggiore precisione, quale modello coinvolgere, quando ricorrere a un’opzione più potente e quando utilizzare un modello meno costoso ma già dimostratosi affidabile per quella specifica attività.