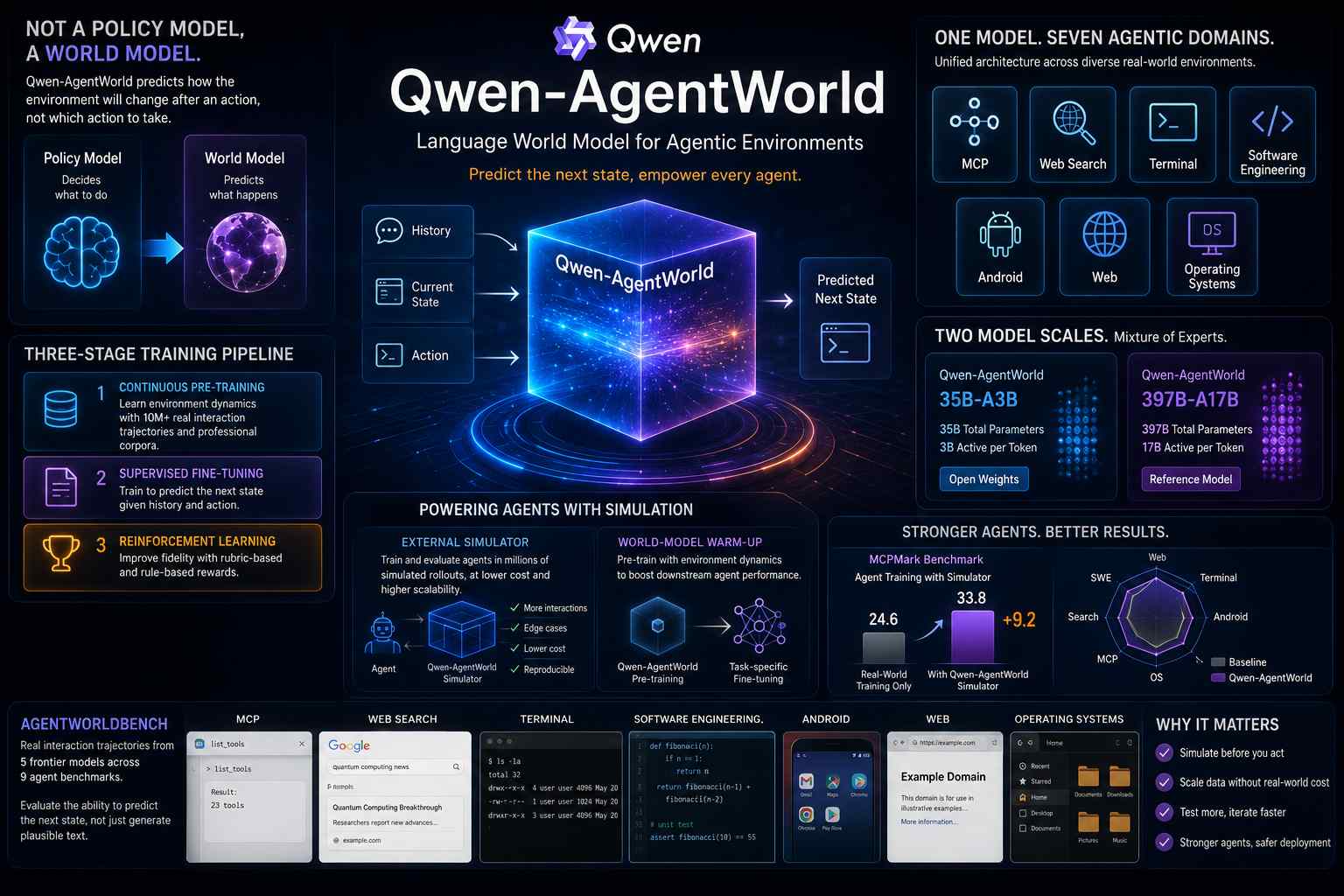
Alibaba, attraverso il team Qwen, ha rilasciato Qwen-AgentWorld, una famiglia di language world model progettata non per decidere direttamente quale azione un agente debba compiere, ma per prevedere come cambierà l’ambiente dopo quell’azione. Il progetto riguarda quindi un livello diverso rispetto ai normali modelli agentici: invece di addestrare il modello a selezionare strumenti, cliccare interfacce o completare task, Alibaba lo addestra a stimare il prossimo stato dell’ambiente a partire dalla cronologia dell’interazione e dall’azione appena eseguita.
Qwen-AgentWorld copre sette domini agentici all’interno della stessa architettura: MCP, ricerca web, terminale, software engineering, Android, web e sistemi operativi. Il modello può ricevere lo stato corrente di un ambiente, le osservazioni precedenti e l’azione proposta da un agente, quindi generare una previsione testuale dell’esito atteso. In pratica, può simulare ciò che un browser, un terminale, un’app Android, un tool MCP o un ambiente software restituirebbe dopo una determinata chiamata.
Alibaba ha sviluppato due versioni: Qwen-AgentWorld-35B-A3B, con 35 miliardi di parametri totali e 3 miliardi attivi per token, e Qwen-AgentWorld-397B-A17B, con 397 miliardi di parametri e 17 miliardi attivi. Entrambi i modelli utilizzano un’architettura Mixture of Experts, nella quale solo una parte dei parametri viene attivata durante ogni passaggio di inferenza. Il modello più piccolo è disponibile con pesi aperti, mentre la versione più grande viene proposta come modello di riferimento per le valutazioni e per i casi che richiedono una simulazione più accurata.
Il training si basa su oltre dieci milioni di traiettorie di interazione raccolte in ambienti reali. Una traiettoria contiene la sequenza di osservazioni, azioni, chiamate a strumenti e risultati prodotti durante il completamento di un task. Alibaba ha organizzato l’addestramento in tre fasi. La prima, Continuous Pre-Training, introduce conoscenze sulle dinamiche degli ambienti e integra corpora professionali aggiuntivi. La seconda, Supervised Fine-Tuning, addestra il modello a ragionare sulla previsione dello stato successivo. La terza utilizza reinforcement learning con ricompense basate sia su rubriche di valutazione sia su regole deterministiche, con l’obiettivo di aumentare la fedeltà della simulazione.
Il punto tecnico centrale è che Qwen-AgentWorld non viene addestrato come policy agentica. Non riceve un task con l’obiettivo di scegliere il prossimo tool o l’azione successiva per massimizzare il successo finale. Il modello deve invece apprendere le transizioni dell’ambiente: data una situazione e una possibile azione, deve prevedere che cosa accadrà. Questo consente di separare l’agente che pianifica e decide dal modello che rappresenta le conseguenze delle sue azioni.
Alibaba utilizza questo approccio in due modi. Il primo consiste nell’impiego di Qwen-AgentWorld come simulatore esterno. Un agente può essere addestrato o valutato in un ambiente generato dal world model, senza dover eseguire ogni tentativo su browser reali, repository software, applicazioni Android o infrastrutture di sistema. La simulazione permette di generare molte più interazioni, introdurre casi limite e ripetere scenari difficili da riprodurre nei sistemi reali, mantenendo sotto controllo costi, disponibilità degli strumenti e variabilità dell’ambiente.
Nel benchmark MCPMark, Alibaba riporta che l’addestramento dell’agente con il simulatore Qwen-AgentWorld ha portato il punteggio dal 24,6 al 33,8. Il risultato viene confrontato con agenti addestrati esclusivamente negli ambienti reali, dove la possibilità di produrre traiettorie aggiuntive è limitata dal costo delle chiamate, dalla disponibilità degli strumenti e dalla difficoltà di costruire in modo controllato casi anomali o rari.
Il secondo utilizzo riguarda il world-model warm-up. In questo caso la capacità di simulare l’ambiente viene incorporata direttamente nel modello che sarà poi sottoposto a fine-tuning per compiti agentici. Alibaba ha verificato che il pre-addestramento sulle dinamiche ambientali migliora le prestazioni downstream su sette benchmark, compresi tre benchmark che non erano presenti nei dati di training. L’effetto osservato suggerisce che la previsione delle conseguenze delle azioni può fornire una base utile per task successivi di pianificazione, tool use e navigazione in ambienti digitali.
Per valutare il modello, il team Qwen ha costruito AgentWorldBench, un benchmark composto da interazioni reali effettuate da cinque modelli frontier su nove benchmark agentici esistenti. L’obiettivo non è misurare soltanto se il modello riesce a generare una risposta plausibile, ma se riesce a prevedere in modo corretto lo stato successivo dopo una sequenza di azioni. Questa distinzione è importante perché un world model destinato agli agenti deve riprodurre non solo testo o conoscenza generale, ma errori, output di tool, modifiche di stato, risultati intermedi e vincoli specifici dell’ambiente.
Qwen-AgentWorld si colloca quindi tra il modello linguistico e il sistema nel quale l’agente opera. Non sostituisce il planner, il router degli strumenti o l’agente esecutivo, ma fornisce un livello di simulazione che può essere utilizzato per generare dati sintetici, testare strategie, prevedere gli effetti delle azioni e preparare un agente prima del confronto con ambienti reali. Alibaba punta così a ridurre la dipendenza dall’addestramento diretto in sistemi operativi, browser, terminali e tool esterni, trasferendo parte del processo di apprendimento in un ambiente simulato basato sul linguaggio.