Cognition ha presentato Devin Fusion, una nuova architettura multi-modello per il proprio agente di coding Devin, progettata per mantenere prestazioni comparabili ai modelli di frontiera riducendo in modo significativo il costo operativo delle attività di sviluppo software. Il sistema utilizza più modelli AI all’interno della stessa sessione di lavoro e assegna a ciascuno compiti diversi in base alla complessità tecnica, alla fase del workflow e al rapporto tra qualità richiesta e costo di inferenza.
Devin Fusion nasce dal limite dei tradizionali sistemi di model routing, nei quali un router sceglie un solo modello all’inizio del task e gli affida l’intera esecuzione. Questo approccio può funzionare nei benchmark, ma risulta meno affidabile nei progetti software reali, dove una richiesta inizialmente semplice può evolvere in un problema con dipendenze, bug, refactoring, test falliti o requisiti ambigui. La scelta effettuata sul prompt iniziale non è sempre sufficiente a prevedere quale livello di ragionamento sarà necessario nelle fasi successive.
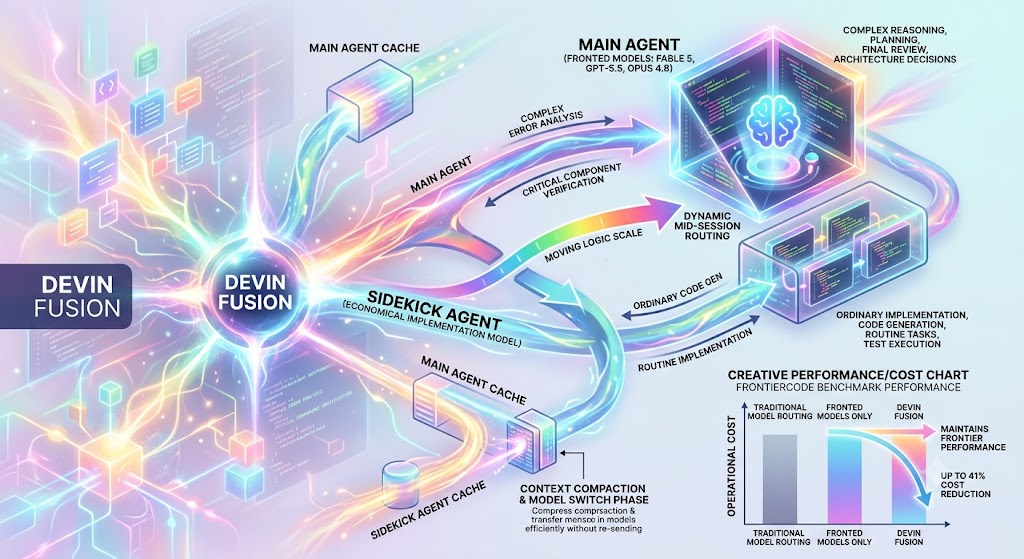
L’architettura introduce una struttura definita Sidekick. Invece di delegare l’intero lavoro a un unico modello, Devin Fusion esegue in parallelo un agente principale e un agente secondario più economico. Il main agent utilizza modelli di frontiera come Fable 5, GPT-5.5 o Opus 4.8 e viene riservato alle decisioni che richiedono maggiore capacità di ragionamento, come la pianificazione generale, l’interpretazione di richieste poco definite, la revisione finale e la valutazione delle modifiche più delicate. Il sidekick model viene invece impiegato per una parte consistente delle attività di implementazione, dove il costo di un modello premium non è sempre giustificato.
I due agenti lavorano con strumenti e ambienti separati, mantenendo una propria esecuzione autonoma. Questo permette al sistema di assegnare e riassegnare attività durante la sessione senza trattare il modello secondario come una semplice estensione passiva del modello principale. La ripartizione del lavoro viene gestita tramite Dynamic Mid-session Routing, un meccanismo che consente di cambiare modello mentre il task è in corso, anziché fissare il routing una sola volta all’avvio.
Il routing dinamico permette di intervenire quando emergono condizioni nuove. Un’attività di generazione di codice può essere trasferita al sidekick durante la fase di implementazione ordinaria e tornare al modello principale quando serve valutare un’architettura, risolvere un errore complesso, verificare il comportamento di un componente critico o decidere tra alternative tecniche. La selezione del modello diventa quindi un processo continuo, basato sull’evoluzione concreta del lavoro e non soltanto sulla formulazione iniziale della richiesta.
Un elemento centrale della progettazione riguarda la gestione della cache. In una normale architettura multi-modello, il passaggio da un modello a un altro può richiedere il reinvio dell’intero contesto della sessione, con costi elevati dovuti alla ricostruzione del prompt, alla lettura della cronologia e alla nuova elaborazione dei file di progetto. Devin Fusion evita questo problema mantenendo cache indipendenti e persistenti per il main agent e per il sidekick.
Il sistema sfrutta inoltre il momento in cui avviene la context compaction, cioè la compressione della cronologia necessaria per ridurre il peso del contesto operativo. Il cambio di modello viene effettuato in corrispondenza di questa fase, così da limitare il costo aggiuntivo della transizione e impedire che il routing dinamico annulli i vantaggi economici ottenuti usando un modello meno costoso. In pratica, l’architettura combina la selezione del modello con il ciclo di gestione del contesto già necessario per mantenere sostenibili le sessioni di coding più lunghe.
Cognition ha valutato Devin Fusion sul benchmark proprietario FrontierCode, pensato per misurare sia la correttezza del codice sia la qualità dell’output in scenari più vicini allo sviluppo reale. Secondo i risultati comunicati, il sistema mantiene prestazioni paragonabili a GPT-5.5 e Opus 4.8, riducendo al tempo stesso i costi di circa il 35%. Il confronto con Fable 5 mostra una riduzione fino al 41% a parità di prestazioni dichiarate.
La riduzione rispetto a Fable 5 viene indicata come particolarmente rilevante perché ottenuta senza ulteriori ottimizzazioni rese possibili dall’accesso diretto al modello. Cognition ha spiegato che l’interruzione dell’accesso a Fable 5 dovuta ai controlli all’esportazione degli Stati Uniti ha limitato le possibilità di intervenire ulteriormente sul sistema. L’azienda prevede di integrare Fable 5 in Devin Fusion quando il servizio tornerà disponibile, con l’obiettivo di aumentare ulteriormente l’efficienza complessiva.
L’architettura è stata testata anche nei workflow interni di Cognition. Nei dati diffusi dall’azienda, l’88% delle pull request effettivamente unite al codice principale è stato gestito integralmente dal router automatico. Il dato indica che, nella maggior parte dei casi conclusi con merge, il sistema è riuscito a distribuire il lavoro tra modelli senza richiedere una selezione manuale costante da parte degli sviluppatori.
Devin Fusion è disponibile in anteprima per gli utenti cloud di Devin. Il progetto riflette un’evoluzione degli agenti di coding da un modello unico e generalista verso sistemi di orchestrazione multi-modello, nei quali le attività di implementazione, code review, test dell’interfaccia, individuazione dei bug e gestione dei requisiti possono essere affidate a modelli diversi. L’obiettivo non è utilizzare sempre il modello più potente, ma impiegare la capacità più costosa soltanto dove produce un vantaggio concreto, lasciando ai modelli più efficienti le attività che possono essere eseguite con minore consumo di risorse.