La digitalizzazione dei manoscritti medievali ha reso disponibili online milioni di immagini ad alta risoluzione, ma per lungo tempo queste riproduzioni sono rimaste poco utilizzabili nella ricerca computazionale. Un manoscritto fotografato può essere consultato da uno specialista, ma non è automaticamente interrogabile, confrontabile o analizzabile su larga scala. La trascrizione manuale richiede competenze paleografiche molto specifiche e tempi estremamente lunghi, soprattutto quando i documenti presentano grafie diverse, abbreviazioni, correzioni, annotazioni marginali e ortografie prive di standard condivisi.
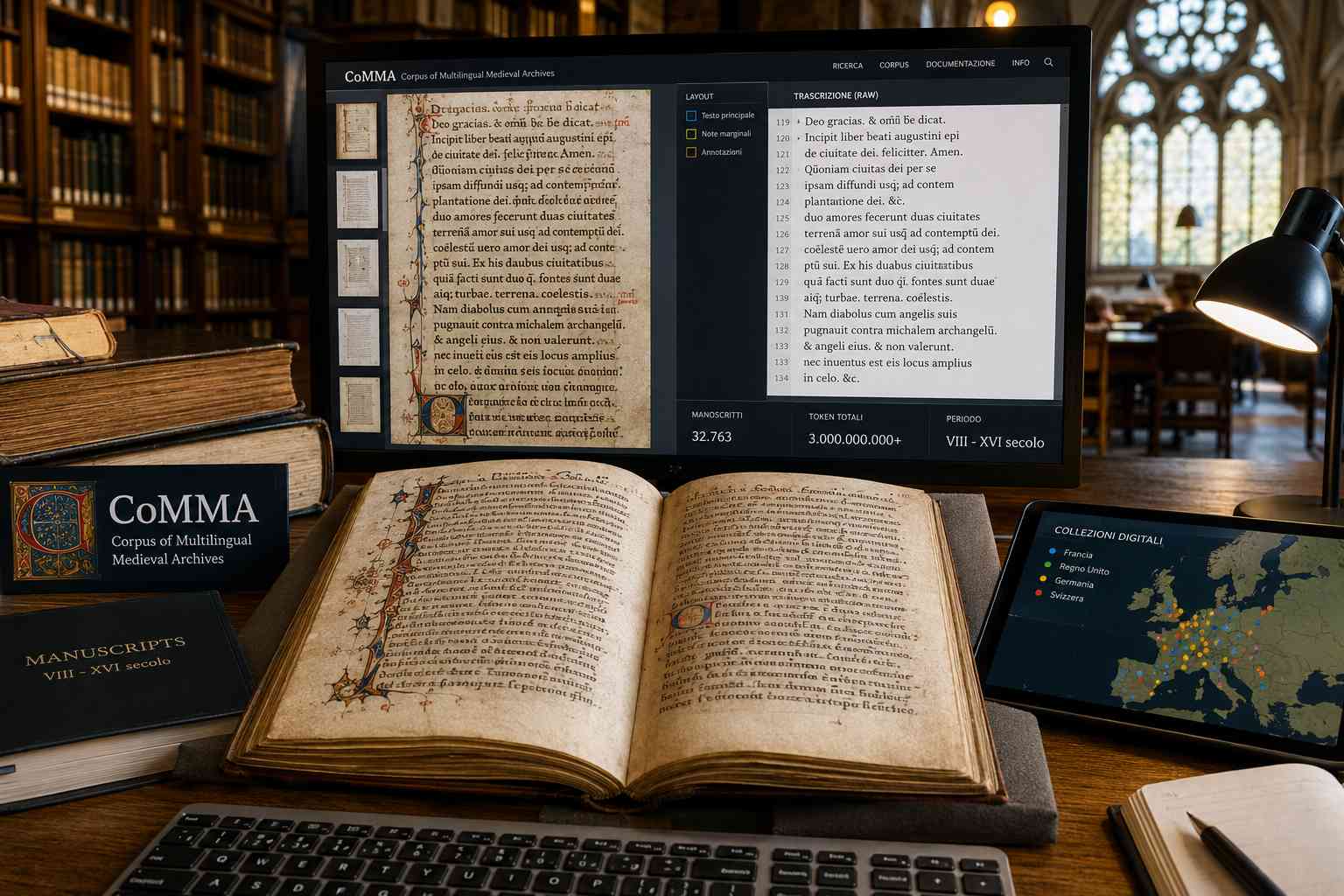
Il progetto CoMMA, Corpus of Multilingual Medieval Archives, affronta questo limite creando un grande corpus testuale ottenuto tramite riconoscimento automatico della scrittura manoscritta. Il sistema ha elaborato 32.763 manoscritti digitalizzati, prevalentemente in latino medievale e francese antico, producendo una raccolta di oltre 3 miliardi di token testuali. Il materiale copre un arco cronologico compreso tra l’VIII e il XVI secolo e proviene da collezioni digitali distribuite tra Francia, Regno Unito, Germania e Svizzera, incluse Gallica della Bibliothèque nationale de France, la Bodleian Library di Oxford, la Bayerische Staatsbibliothek di Monaco e la piattaforma E-Codices.
La scala del risultato è rilevante soprattutto per lo studio delle lingue medievali. Per il francese antico, il corpus mette a disposizione centinaia di milioni di pseudo-parole, cioè sequenze testuali conservate senza forzarle dentro convenzioni linguistiche moderne. Per il latino, il volume raggiunge diversi miliardi di token. Questo permette di cercare formule ricorrenti, varianti ortografiche, abbreviazioni, strutture lessicali e usi locali della scrittura su una quantità di fonti che sarebbe impossibile leggere integralmente con il solo lavoro manuale.
Il punto centrale del progetto non è affidare la trascrizione a un modello linguistico generativo generalista. Nei manoscritti medievali, la stessa parola può apparire in forme molto differenti a seconda del copista, della zona geografica, del secolo e della tradizione scrittoria. In molti testi latini le abbreviazioni rappresentano una quota significativa delle parole, mentre alcune grafie possono rendere ambigua perfino la distinzione tra lettere simili. Un modello orientato a completare o normalizzare il testo rischierebbe di sostituire la fonte con una ricostruzione plausibile ma storicamente falsa.
Per ridurre questo rischio, CoMMA utilizza un approccio di automatic text recognition concentrato sulla lettura grafica della pagina. Il flusso di lavoro combina strumenti open source come Kraken ed eScriptorium: un componente individua le diverse aree della pagina, separando testo principale, note, margini o altri elementi, mentre il modello di trascrizione interpreta le righe manoscritte senza trasformarle in una versione modernizzata. Anche accenti, abbreviazioni, inversioni di lettere ed errori del copista vengono conservati, perché costituiscono dati utili per la ricerca filologica, linguistica e paleografica.
Il modello è stato costruito a partire dal lavoro svolto nel progetto CATMuS, che ha uniformato le regole di trascrizione di circa 300 manoscritti già studiati, per un insieme iniziale di circa 200.000 righe. Questa fase è stata decisiva: l’addestramento automatico richiede criteri coerenti, mentre le trascrizioni prodotte da studiosi diversi possono seguire convenzioni editoriali differenti. Standardizzare il dataset senza cancellare la specificità dei documenti ha reso possibile addestrare un sistema capace di operare su migliaia di fonti.
L’elaborazione dei manoscritti è stata completata in quattro mesi, un tempo incompatibile con una trascrizione integrale realizzata esclusivamente da paleografi. Il risultato non viene però presentato come privo di errori. Su un campione di 670 manoscritti, il tasso medio di errore rilevato è stato del 9,7%, con oltre l’80% delle righe riconosciute correttamente nella maggior parte dei casi. Le prestazioni diminuiscono nei manoscritti più tardivi o caratterizzati da grafie corsive, meno rappresentate nei dati di addestramento. Proprio per questo le trascrizioni restano “raw”, cioè non corrette automaticamente dopo il riconoscimento: il sistema rende visibile il testo letto dalla macchina senza mascherare le incertezze attraverso completamenti artificiali.
La disponibilità pubblica del corpus trasforma il manoscritto medievale da oggetto consultabile singolarmente in una base dati esplorabile per tema, periodo, lingua, forme grafiche e ricorrenze testuali. Storici della medicina, della filosofia, del diritto, della religione e della letteratura possono ora lavorare su fonti che in precedenza restavano difficili da individuare o comparare. Il valore dell’intelligenza artificiale, in questo caso, non consiste nel riscrivere il passato in un linguaggio contemporaneo, ma nel creare un accesso strutturato a testi che mantengono le loro irregolarità, le loro abbreviazioni e la loro complessità originale.