DEEPMIND CONFRONTA IL MODO IN CUI I BAMBINI E L’IA ESPLORANO IL MONDO
Recentemente, i ricercatori di Alphabet DeepMind e dell’Università della California, Berkeley hanno proposto un framework AI per confrontare i comportamenti dei bambini e degli agenti di IA e quindi sviluppare nuove tecniche di esplorazione.
Durante lo sviluppo di un agente per l’apprendimento per rinforzo , ci sono diverse domande relative al comportamento esplorativo che viene in mente ai ricercatori: come dovrebbe un agente raccogliere esperienza sufficiente da ambienti diversi per produrre comportamenti ottimali. Secondo i ricercatori, il problema delle esplorazioni è stato considerato come uno dei problemi fondamentali di RL.
Sono stati condotti numerosi ricercatori su questo problema. Nonostante questi sforzi, il problema dell’esplorazione rimane irrisolto. Gli algoritmi che hanno raggiunto prestazioni all’avanguardia su benchmark popolari come Atari, spesso si basano su semplici strategie di esplorazione – avide – combinate con enormi quantità di calcolo.
Dalla prospettiva di un bambino
In questo articolo, i ricercatori hanno eseguito confronti diretti e controllati tra bambini e agenti per sfruttare le intuizioni del comportamento esplorativo dei bambini per migliorare la progettazione degli algoritmi RL.
Un essere umano possiede un’innata capacità di esplorare l’ambiente dal giorno in cui nasce un bambino. I bambini sono uno studente attivo e curioso che esplora i dintorni in modo completo ed efficiente per imparare cose nuove.
Secondo i ricercatori, recenti prove suggeriscono che i bambini esplorano davvero più di un essere adulto. Ciò significa che i bambini tendono a svolgere una maggiore quantità di apprendimento rispetto a un adulto. La generalizzazione e l’apprendimento rapido risultanti dall’esplorazione dei bambini è in effetti in contrasto con ciò che mostrano i moderni agenti RL.
Ci sono tre ragioni principali per confrontare il comportamento dei bambini con un agente RL. Sono menzionati di seguito: –
Validità ecologica: secondo i ricercatori, un motivo cruciale per la raccolta di dati da bambini e agenti RL nello stesso ambiente è che aiuta gli agenti di apprendimento del rinforzo a essere valutati in un ambiente più ecologicamente valido, in contrasto con le impostazioni simili alla griglia del mondo, Giochi Atari 2D, tra gli altri.
Confronti controllati: il confronto diretto dei bambini con gli agenti dell’apprendimento per rinforzo mira a fornire una base standard per la valutazione del comportamento degli agenti e può aiutare a identificare le aree di ricerca promettente nel RL profondo.
Modellistica cognitiva: oltre alle due condizioni sopra menzionate, i confronti diretti tra bambini e agenti RL forniscono una forte direzione nello sviluppo di nuovi modelli cognitivi di comportamento, promuovendo il “ciclo virtuoso” tra scienza cognitiva e IA.
Leggi anche dopo la favolosa vittoria di AlphaGo Zero, perché DeepMind AI non ha mai prodotto nulla di spettacolare?
Dietro il quadro
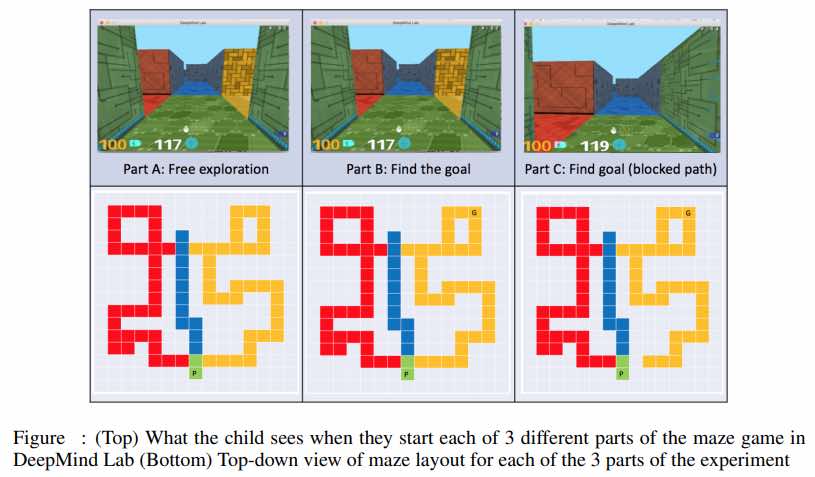
I ricercatori hanno presentato una metodologia basata su DeepMind Lab per confrontare direttamente il comportamento dei bambini e degli agenti RL in attività di esplorazione simulate. Ciò ha permesso ai ricercatori di testare con precisione le domande su come i bambini esplorano, come gli agenti esplorano e come e perché differiscono.
Inoltre, usando questa metodologia, i ricercatori hanno proposto due esperimenti candidati progettati per testare le previsioni qualitative chiave di diversi algoritmi di esplorazione rispetto a ciò che è noto sul comportamento di esplorazione dei bambini in altri settori. I due esperimenti sono esplorazione gratuita contro obiettivo e ricompense sparse contro densi. Questi esperimenti sono stati convalidati su domande come la quantità di bambini e agenti che sono disposti a esplorare, se le strategie di esplorazione gratuite rispetto agli obiettivi differiscono e in che modo la modellazione della ricompensa influenza l’esplorazione.
Come funziona
DeepMind Lab è un ambiente di apprendimento, basato sul motore di gioco di Quake, che offre una suite di impegnativi compiti di navigazione 3D e di risoluzione di puzzle per agenti didattici. I ricercatori hanno proposto un ambiente unificato con compiti di formazione e valutazione di esseri umani e agenti.
Secondo i ricercatori, questi compiti richiedono capacità di navigazione fisica o spaziale per raggiungere e sono modellati su giochi che i bambini giocano da soli. Nella configurazione sperimentale, i bambini possono interagire con l’ ambiente DeepMind Lab attraverso un controller personalizzato basato su Arduino. Il controller espone quattro azioni che gli agenti dovrebbero utilizzare in questo ambiente, che si muovono in avanti, indietro, si spostano a sinistra e girano a destra.
RIassumendo
In entrambi gli esperimenti di cui sopra, i ricercatori hanno scoperto che durante l’esplorazione libera contro diretta, le strategie di ricerca dei bambini differiscono tra no-goal e condizione dell’obiettivo. Il comportamento dei bambini viene confrontato con un agente di ricerca approfondita (DFS) e ha dimostrato che nella condizione senza obiettivo, i bambini hanno fatto scelte coerenti con DFS 89,61 per cento delle volte rispetto alla condizione dell’obiettivo, in cui i bambini hanno fatto scelte coerenti con il DFS 96,04 per cento delle volte. Nel secondo esperimento, che è scarso rispetto a premi densi, i ricercatori hanno scoperto che i bambini hanno meno probabilità di esplorare un’area nella condizione di premi densi.