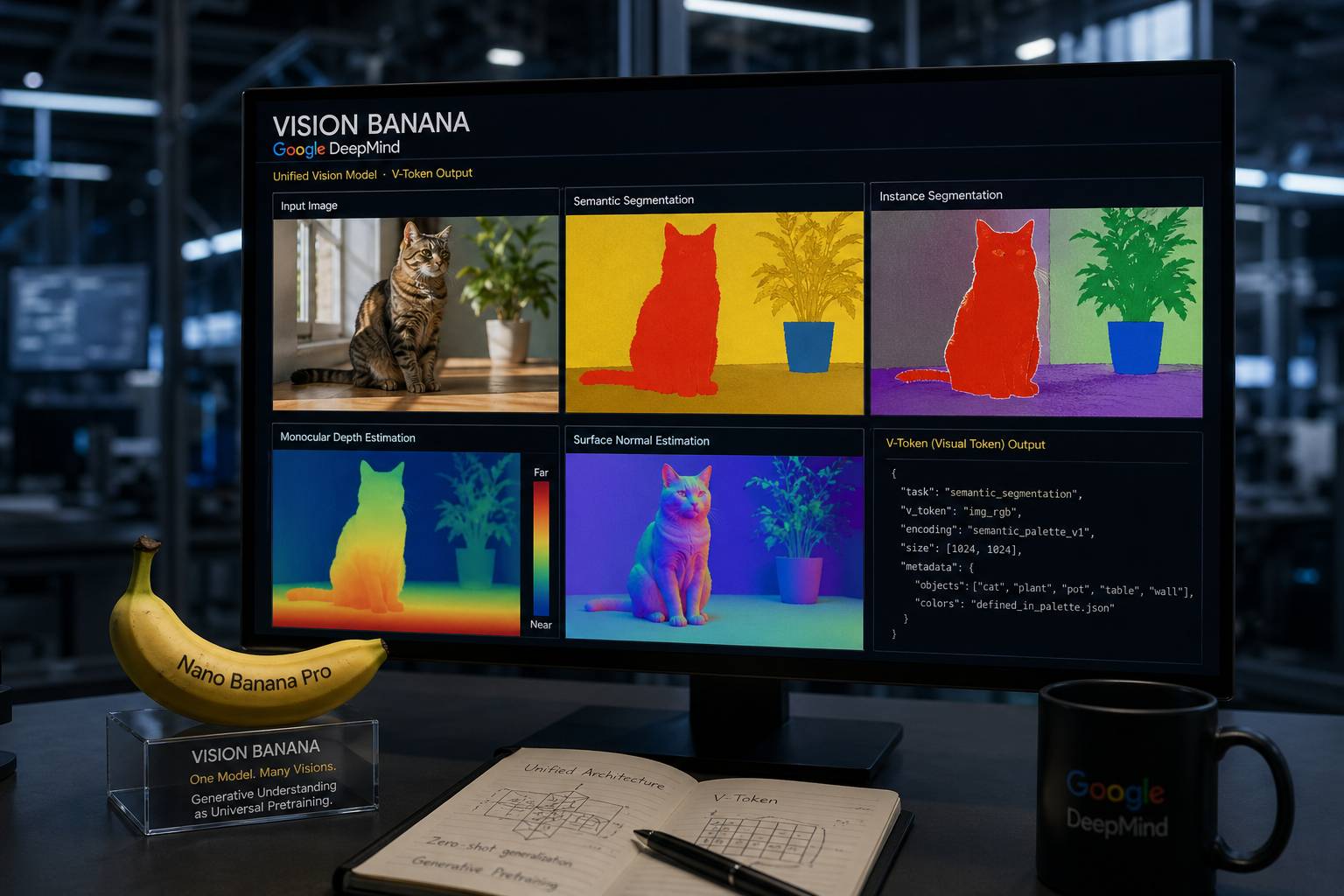
I ricercatori di Google DeepMind hanno recentemente rilasciato Vision Banana, un modello integrato che dimostra come la capacità di generare immagini realistiche porti intrinsecamente con sé una profonda comprensione delle strutture spaziali e semantiche del mondo fisico. Questa ricerca suggerisce che il processo di generazione delle immagini possa fungere da fase di pre-addestramento universale, ricoprendo un ruolo analogo a quello svolto dalla generazione di testo nei modelli linguistici di grandi dimensioni, dove la previsione del contenuto successivo permette l’emergere di capacità cognitive latenti.
Vision Banana è stato sviluppato partendo dalla solida base del modello generativo Nano Banana Pro. Il team di ricerca ha dimostrato che non è necessario stravolgere l’architettura originale per dotare il sistema di capacità analitiche avanzate; è stato infatti sufficiente applicare una leggera procedura di messa a punto delle istruzioni utilizzando un volume ridotto di dati specifici per i compiti visivi. Grazie a questo approccio, il modello è in grado di eseguire compiti complessi come la segmentazione semantica, la segmentazione degli oggetti, la stima della profondità monoculare e la determinazione delle normali di superficie semplicemente modificando il prompt di input testuale. La struttura del modello rimane invariata, eliminando la necessità di moduli separati o “teste” specializzate per ogni diversa funzione di visione artificiale.
Una delle innovazioni più significative introdotte con Vision Banana riguarda l’unificazione del formato di output attraverso l’impiego dei cosiddetti V-Token (Visual Token). Invece di produrre dati numerici astratti o mappe di calore isolate, il modello converte ogni analisi in un’immagine RGB standardizzata. Ad esempio, in un compito di segmentazione semantica, il modello genera una rappresentazione visiva dove gli oggetti sono codificati cromaticamente in base a regole predefinite, come un gatto visualizzato in rosso su uno sfondo giallo. Poiché questi colori rispondono a una codifica semantica rigorosa, l’output visivo può essere riconvertito istantaneamente in dati quantitativi precisi, offrendo al contempo una modalità di verifica intuitiva per l’utente umano e una struttura dati leggibile per altre macchine.
Le prestazioni rilevate nei benchmark evidenziano come questa espansione funzionale non abbia compromesso le capacità generative originali del modello. Al contrario, Vision Banana ha mostrato risultati superiori o paragonabili a modelli di punta specializzati, come SAM (Segment Anything Model) 3 per la segmentazione e Depth Anything per la stima della profondità, operando in ambienti zero-shot. Questo significa che il modello è capace di interpretare correttamente scene e oggetti mai incontrati durante la fase di addestramento specifico, basandosi esclusivamente sulla ricca rappresentazione del mondo acquisita durante la fase generativa. La capacità di determinare la distanza tra gli oggetti o l’orientamento delle superfici deriva infatti dalla necessità intrinseca del modello di comprendere la coerenza prospettica e strutturale necessaria a generare un’immagine credibile.