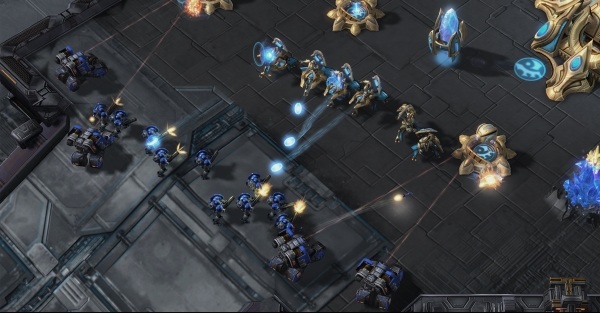
Gli agenti di intelligenza artificiale sviluppati dalla sussidiaria DeepMind di Google hanno battuto i professionisti umani a Starcraft II – una novità assoluta nel mondo dell’intelligenza artificiale. In una serie di partite trasmesse in streaming su YouTube e Twitch , i giocatori di IA hanno battuto gli umani 10 partite di fila. Nella partita finale, il giocatore professionista Grzegorz “MaNa” Komincz è stato in grado di strappare una sola vittoria per l’umanità.
“La storia dell’IA è stata contrassegnata da una serie di importanti vittorie nel benchmark in diversi giochi”, ha dichiarato David Silver, co-lead della ricerca DeepMind, dopo le partite. “E spero – anche se c’è chiaramente lavoro da fare – che la gente in futuro possa guardare indietro a oggi e forse considerarlo come un ulteriore passo avanti per ciò che i sistemi di intelligenza artificiale possono fare”.
Colpire gli esseri umani ai videogiochi potrebbe sembrare un evento secondario nello sviluppo dell’IA, ma è una sfida significativa per la ricerca. Giochi come Starcraft II sono più difficili da giocare con i computer rispetto a giochi da tavolo come scacchi o Go. Nei videogiochi, gli agenti IA non possono osservare il movimento di ogni pezzo per calcolare la loro prossima mossa e devono reagire in tempo reale.
Questi fattori non sembravano molto di ostacolo al sistema AI di DeepMind, soprannominato AlphaStar. In primo luogo, ha battuto il giocatore professionista Dario “TLO” Wünsch, prima di passare a MaNa. I giochi erano originariamente giocati a dicembre l’anno scorso al quartier generale di DeepMind a Londra, ma una partita finale contro MaNa è stata trasmessa in diretta oggi, fornendo agli umani la loro singola vittoria.
I commentatori di Starcraft hanno descritto il gioco di AlphaStar come “fenomenale” e “superumano”. In Starcraft II , i giocatori iniziano su lati diversi della stessa mappa prima di costruire una base, addestrare un esercito e invadere il territorio nemico. AlphaStar era particolarmente bravo in quello che viene chiamato “micro”, abbreviazione di microgestione, che si riferisce alla capacità di controllare le truppe rapidamente e in modo decisivo sul campo di battaglia.
“CONTROLLO DELL’UNITÀ FENOMENALE, SOLO NON QUALCOSA CHE VEDIAMO MOLTO SPESSO”
Anche se i giocatori umani riuscivano a volte a addestrare unità più potenti, AlphaZero era in grado di sconfiggerli da vicino. In una partita, AlphaStar brulicava MaNa con un’unità in rapido movimento chiamata Stalker. Il commentatore Kevin “RotterdaM” van der Kooi lo ha descritto come “controllo dell’unità fenomenale, non è qualcosa che vediamo molto spesso”. MaNa ha notato dopo la partita: “Se gioco a qualsiasi giocatore umano, non lo faranno microingendo i loro Stalker “.
Ciò riecheggia il comportamento che abbiamo visto da altri AI di gioco di alto livello. Quando gli agenti di OpenAI hanno giocato con professionisti umani a Dota 2 lo scorso anno, alla fine sono stati sconfitti . Ma gli esperti hanno notato che gli agenti hanno di nuovo giocato con una “chiarezza e precisione” che era “ipnotica”. Prendere decisioni rapide senza errori è, ovviamente, il terreno di casa di una macchina.
Gli esperti hanno già iniziato a analizzare i giochi e discutere se AlphaStar avesse vantaggi ingiusti. L’agente AI era zoppicante in qualche modo. Ad esempio, è stato impedito di eseguire più clic al minuto di un essere umano. Ma a differenza dei giocatori umani, è stato in grado di visualizzare l’intera mappa in una sola volta, piuttosto che navigarla manualmente.
I ricercatori di DeepMind hanno detto che questo non ha fornito alcun vantaggio reale in quanto l’agente si concentra solo su una singola parte della mappa in qualsiasi momento. Ma, come hanno dimostrato i giochi, ciò non ha impedito ad AlphaStar di controllare le unità in tre diverse parti contemporaneamente, cosa che i commentatori hanno detto che sarebbe impossibile per gli umani. In particolare, quando MaNa ha battuto AlphaStar nella partita dal vivo, l’IA giocava con una vista telecamera limitata.
Un altro potenziale punto dolente includeva il fatto che i giocatori umani, mentre i professionisti, non erano uno standard campione del mondo. In particolare, TLO ha dovuto giocare con una delle tre gare di Starcraft II che non conosceva.
Una rappresentazione grafica dell’elaborazione di AlphaStar. Il sistema vede l’intera mappa dall’alto verso il basso e predice quale comportamento porterà alla vittoria. Immagine: DeepMind
A parte questa discussione, gli esperti dicono che le partite sono stati un significativo passo avanti. Dave Churchill, un ricercatore di intelligenza artificiale che è stato a lungo coinvolto nella scena IA di Starcraft , ha dichiarato a The Verge : “Penso che la forza dell’agente sia un risultato significativo, e sia arrivato almeno un anno in anticipo rispetto alle supposizioni più ottimistiche che ho ascoltato tra i ricercatori di IA “.
Tuttavia, Churchill ha aggiunto che, poiché DeepMind non aveva ancora pubblicato alcun documento di ricerca sul lavoro, era difficile dire se avesse mostrato o meno un salto tecnologico. “Non ho ancora letto l’articolo del blog o ho avuto accesso a documenti o dettagli tecnici per fare quella chiamata”, ha detto Churchill.
Mark Riedl, un professore associato di IA alla Georgia Tech, ha detto di essere meno sorpreso dai risultati e che questa vittoria è stata solo “una questione di tempo”. Riedl ha aggiunto che non pensava che i giochi mostrassero che Starcraft II era stato battuto definitivamente. “Nell’ultimo gioco dal vivo, la limitazione di AlphaStar alla finestra ha eliminato parte del suo vantaggio artificiale”, ha affermato Riedl. “Ma il problema più grande che abbiamo visto … è che la politica appresa [dall’IA] è fragile, e quando un essere umano può spingere l’IA fuori dalla sua zona di comfort, l’IA cade a pezzi”.
In definitiva, l’obiettivo finale di un lavoro come questo non è quello di battere gli umani nei videogiochi, ma di affinare i metodi di allenamento AI, in particolare per creare sistemi che possano operare in ambienti virtuali complessi come Starcraft .
Per addestrare AlphaStar, i ricercatori di DeepMind hanno utilizzato un metodo noto come apprendimento di rinforzo. Gli agenti svolgono essenzialmente il gioco per tentativi ed errori mentre cercano di raggiungere determinati obiettivi come vincere o semplicemente rimanere in vita. Imparano prima copiando i giocatori umani e poi si giocano a vicenda in una competizione simile a un colosseo. Gli agenti più forti sopravvivono e i più deboli vengono scartati. DeepMind ha stimato che i suoi agenti AlphaStar hanno accumulato circa 200 anni di gioco in questo modo, giocando ad un ritmo accelerato.
DeepMind era chiaro sul suo obiettivo nello svolgimento di questo lavoro. “In primo luogo, la missione di DeepMind è quella di costruire un’intelligenza generale artificiale”, ha detto Oriol Vinyals, co-protagonista del progetto AlphaStar, riferendosi alla ricerca di costruire un agente di intelligenza artificiale in grado di svolgere qualsiasi compito mentale che un essere umano possa fare. “Per fare ciò, è importante fare un benchmark su come i nostri agenti eseguono su una vasta gamma di compiti.”