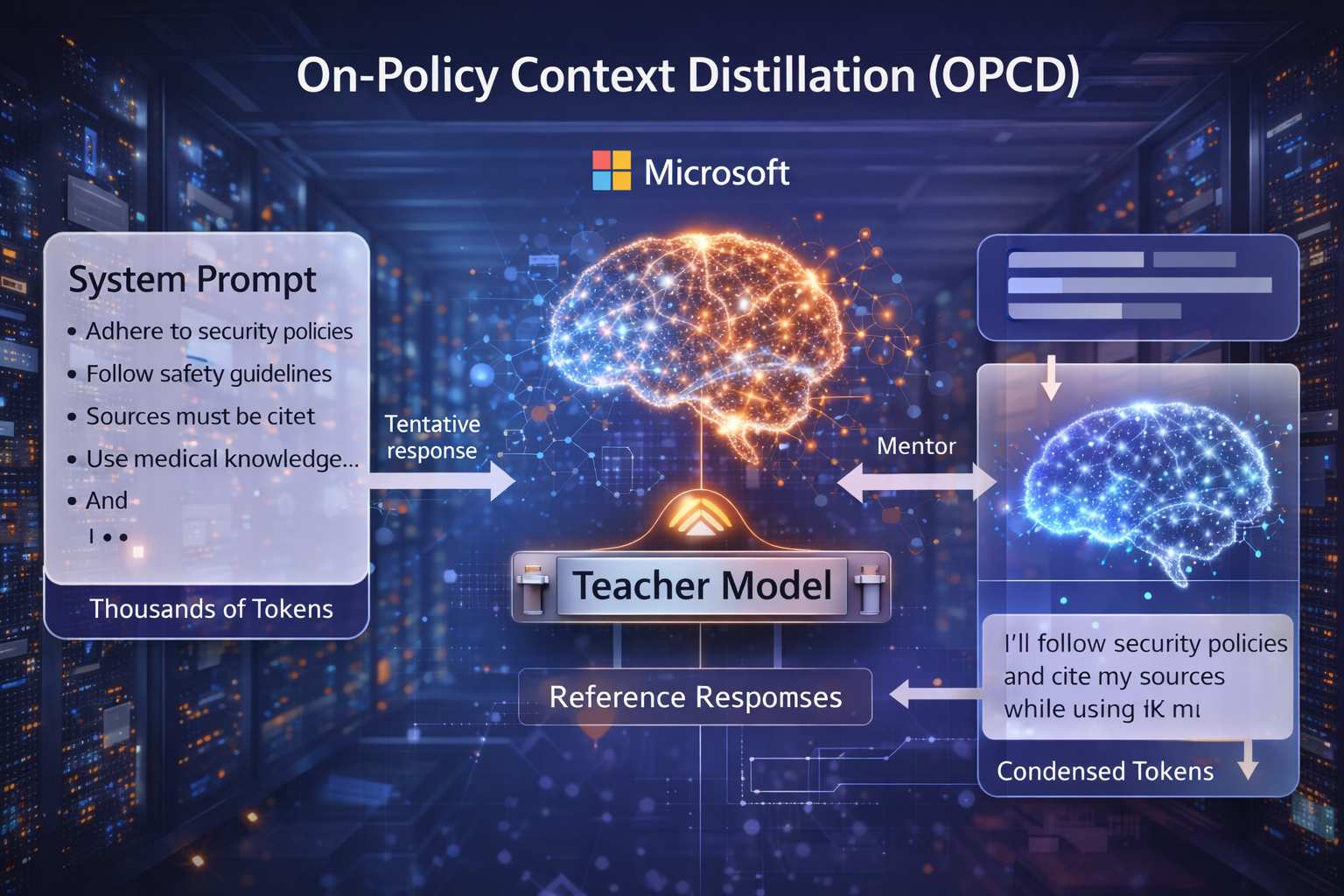
Una delle criticità più rilevanti per le aziende che integrano Large Language Model nei propri servizi riguarda la gestione di prompt di sistema lunghi e articolati. Per garantire che un modello rispetti policy interne, regole di sicurezza, linee guida normative e conoscenze di dominio specifiche, le organizzazioni tendono ad aggiungere migliaia o decine di migliaia di token all’interno del contesto di input. Questo approccio, sebbene efficace nel controllare il comportamento del modello, comporta un aumento significativo della latenza di inferenza e dei costi per singola richiesta, soprattutto in ambienti ad alto volume. Per affrontare questo problema, i ricercatori di Microsoft hanno presentato un nuovo framework di apprendimento denominato On-Policy Context Distillation, abbreviato in OPCD.
L’idea alla base di OPCD è quella di spostare le istruzioni ripetitive e relativamente stabili dal contesto di input ai parametri interni del modello, riducendo la necessità di reinserire continuamente lunghe spiegazioni o policy. In pratica, si tratta di una forma avanzata di distillazione del contesto che consente al modello di “memorizzare” regole e linee guida direttamente nella propria struttura parametrica, preservando al contempo la qualità delle risposte.
Il framework si basa su una struttura insegnante-studente. Il modello insegnante, dotato di accesso a contesti completi e spiegazioni dettagliate, produce risposte di riferimento. Il modello studente, generalmente più piccolo e più efficiente, apprende da queste risposte con l’obiettivo di riprodurre un comportamento equivalente senza dover ricevere nuovamente l’intero prompt esteso. Questo paradigma non è completamente nuovo nel panorama della distillazione, ma OPCD introduce una differenza sostanziale rispetto agli approcci precedenti.
Le tecniche tradizionali di context distillation adottavano un’impostazione off-policy, in cui il modello studente veniva addestrato esclusivamente su dataset statici di risposte generate dall’insegnante. Questo metodo, tuttavia, espone il modello al cosiddetto bias di esposizione: durante l’addestramento lo studente osserva solo risposte corrette già formate, ma in fase di inferenza deve generare autonomamente sequenze che possono deviare progressivamente dal comportamento desiderato. Anche piccoli errori iniziali possono accumularsi, compromettendo la stabilità nelle applicazioni reali.
Un ulteriore limite degli approcci off-policy riguarda l’uso della minimizzazione della divergenza KL in avanti, che spinge lo studente a imitare il più fedelmente possibile la distribuzione dell’insegnante. Poiché il modello studente è tipicamente più compatto e dispone di meno capacità rappresentativa, replicare perfettamente il ragionamento complesso dell’insegnante risulta difficile. Questo può generare fenomeni assimilabili alle allucinazioni, in cui lo studente produce spiegazioni plausibili ma non rigorosamente fondate, soprattutto quando tenta di colmare lacune informative.
OPCD adotta invece un’impostazione on-policy. Il modello studente genera autonomamente le proprie risposte senza il supporto di lunghi prompt. L’insegnante interviene in tempo reale per valutare l’output dello studente, identificando punti di correttezza e carenze. In questo processo viene minimizzata la divergenza KL inversa, che privilegia un comportamento di tipo mode-seeking. Il modello studente tende così a concentrarsi sulle risposte che ritiene più probabili, evitando dispersioni su possibilità meno plausibili. Questo meccanismo riduce la propensione a generare contenuti irrilevanti o eccessivamente speculativi e contribuisce a stabilizzare il comportamento del modello in ambienti di produzione.
I ricercatori hanno validato OPCD in due scenari principali. Il primo riguarda la distillazione dell’esperienza. In questo caso, il modello apprende regole e schemi generali derivati da soluzioni efficaci precedenti, internalizzando know-how operativo senza la necessità di reinserire ogni volta le stesse istruzioni. Nei test su problemi matematici complessi, un modello da 8 miliardi di parametri ha visto l’accuratezza aumentare dal 75,0% all’80,9%. In un ambiente di navigazione come Frozen Lake, un modello più piccolo da 1,7 miliardi di parametri ha incrementato il tasso di successo dal 6,3% al 38,3%, evidenziando un miglioramento sostanziale della capacità decisionale.
Il secondo scenario ha riguardato l’internalizzazione di prompt di sistema lunghi e complessi, in particolare in ambiti di sicurezza e medicina. Un modello da 3 miliardi di parametri, inizialmente con un’accuratezza del 30,7% in compiti di classificazione legati alla sicurezza e ai contenuti pericolosi, ha raggiunto l’83,1% dopo l’addestramento con OPCD. Analogamente, nelle domande e risposte mediche l’accuratezza è passata dal 59,4% al 76,3%. Questi risultati indicano che la compressione strutturata delle istruzioni nei parametri del modello può migliorare non solo l’efficienza, ma anche le prestazioni.
Un aspetto critico analizzato è il rischio di dimenticanza catastrofica, fenomeno comune nel fine-tuning tradizionale in cui l’adattamento a un compito specifico comporta il degrado di competenze precedentemente acquisite. Nei test condotti, i modelli addestrati con OPCD hanno mantenuto prestazioni generali circa quattro punti percentuali superiori rispetto ai metodi off-policy, dimostrando una migliore capacità di bilanciare specializzazione e competenze di base.
È importante sottolineare che OPCD non sostituisce completamente approcci come la Retrieval-Augmented Generation, particolarmente adatti a gestire basi di conoscenza ampie e in continuo aggiornamento. Quando le informazioni cambiano frequentemente o devono essere recuperate dinamicamente da database esterni, la RAG rimane una soluzione più appropriata. Tuttavia, per regole relativamente stabili, policy interne e linee guida comportamentali, l’internalizzazione tramite OPCD può ridurre significativamente il carico contestuale e i costi operativi.
Dal punto di vista implementativo, il framework è compatibile con pipeline di addestramento già basate su apprendimento per rinforzo con ricompense verificabili. Non richiede modifiche radicali all’architettura esistente e può essere replicato con un’infrastruttura relativamente contenuta, come otto GPU A100. In alcuni casi di distillazione empirica, miglioramenti significativi sono stati ottenuti con soli trenta esempi iniziali, suggerendo una buona efficienza in termini di dati.