NVIDIA ha presentato Nemotron-Labs-TwoTower, una nuova architettura per modelli linguistici a diffusione progettata per aumentare la velocità di generazione senza rinunciare alla capacità di mantenere il contesto. Il sistema nasce dal modello open Nemotron-3-Nano-30B-A3B e adotta una struttura a due reti distinte: una conserva il comportamento autoregressivo tradizionale, l’altra si occupa della generazione diffusiva e della rimozione progressiva del rumore dai token.
Nei modelli autoregressivi convenzionali, ogni token viene prodotto dopo il precedente. Questo processo seriale offre un controllo molto accurato della coerenza del testo, ma limita il throughput perché la generazione non può essere completamente parallelizzata. I modelli a diffusione, al contrario, possono elaborare e correggere più token contemporaneamente, ma tendono a perdere precisione quando una sola rete deve interpretare il contesto già definito e, nello stesso tempo, ricostruire i token ancora rumorosi.
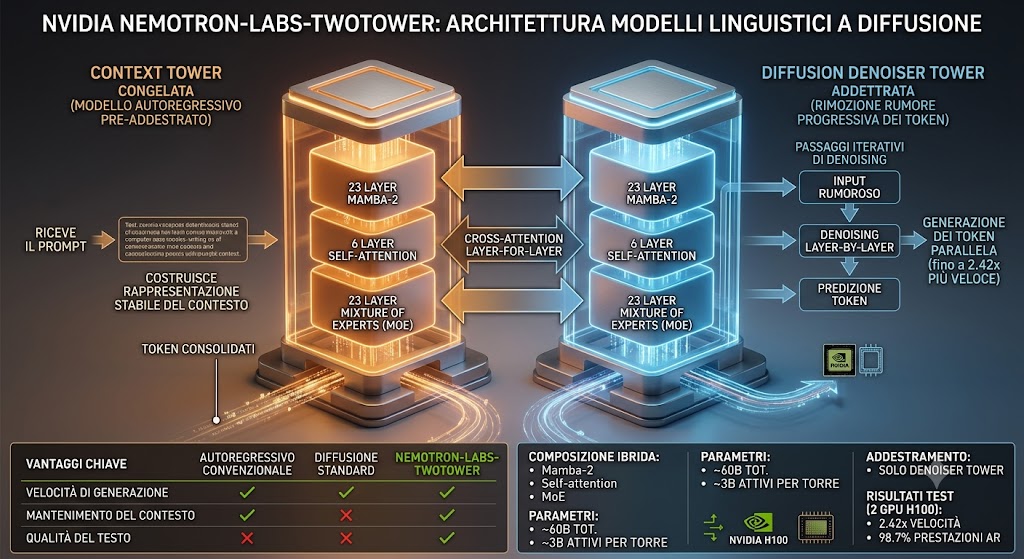
Nemotron-Labs-TwoTower separa questi due compiti. La Context Tower mantiene il modello autoregressivo preaddestrato e viene congelata: riceve il prompt e i token già consolidati, costruendo una rappresentazione stabile del contesto. La Diffusion Denoiser Tower viene invece addestrata per generare i token mancanti attraverso passaggi iterativi di denoising. Durante ogni fase di generazione, il denoiser consulta i livelli corrispondenti della Context Tower tramite cross-attention, invece di basarsi soltanto sull’ultimo stato nascosto disponibile.
La scelta di collegare le due torri layer per layer è il punto tecnico più rilevante dell’architettura. Il denoiser non riceve una sintesi finale del contesto, ma può accedere a rappresentazioni diverse lungo tutta la profondità del modello. Questo consente di combinare le informazioni linguistiche e semantiche già consolidate dal ramo autoregressivo con la generazione parallela tipica della diffusione, riducendo il compromesso tra velocità e qualità.
Il modello utilizza una configurazione ibrida composta da Mamba-2, self-attention Transformer e Mixture of Experts. Ogni torre contiene 52 layer, con 23 layer Mamba-2, 6 layer di self-attention e 23 layer MoE. La struttura completa arriva a circa 60 miliardi di parametri, ma durante l’elaborazione viene attivata soltanto una parte della rete: circa 3 miliardi di parametri per torre. Nel componente MoE sono presenti 128 esperti, dei quali 6 vengono selezionati dinamicamente insieme a 2 esperti condivisi.
NVIDIA non ha riaddestrato da zero l’intero sistema. Entrambe le torri partono dallo stesso checkpoint preaddestrato, ma soltanto la Diffusion Denoiser Tower viene ulteriormente ottimizzata, usando circa 2,1 trilioni di token. La Context Tower resta invariata e funziona come componente stabile per la lettura del prompt e del testo già generato. Questa impostazione riduce il costo di training rispetto alla costruzione di un nuovo modello diffusivo completo e consente di mantenere la compatibilità con il comportamento del modello autoregressivo di origine.
Nei test condotti con due GPU NVIDIA H100, Nemotron-Labs-TwoTower ha mantenuto il 98,7% delle prestazioni del modello autoregressivo di base, aumentando fino a 2,42 volte la velocità effettiva di generazione. La configurazione sperimentale produce 16 token per passaggio e accetta come output finale soltanto quelli che superano una soglia di confidenza pari a 0,8. La soglia può essere abbassata per privilegiare la velocità, aumentando il numero di token generati in parallelo, oppure alzata per mantenere un filtro più selettivo sulla qualità.
Il sistema supporta tre modalità di inferenza. generate_mask_diffusion utilizza il percorso diffusivo, generate_mock_ar riproduce un comportamento simile alla generazione autoregressiva usando l’architettura ibrida, mentre generate_ar esegue il modello autoregressivo tradizionale. La modalità a diffusione richiede due H100 e circa 59 GB di memoria per GPU; la modalità autoregressiva tradizionale può invece funzionare su una singola GPU da 80 GB.
L’architettura è particolarmente adatta ai carichi che richiedono grandi volumi di testo, come produzione di dati sintetici, generazione massiva di contenuti, elaborazione batch e pipeline di inferenza dove il throughput è più importante della latenza del singolo token. NVIDIA ha pubblicato pesi e codice del modello, rendendo disponibile una configurazione che prova a unire la qualità dei modelli autoregressivi con la maggiore parallelizzazione dei modelli linguistici a diffusione.