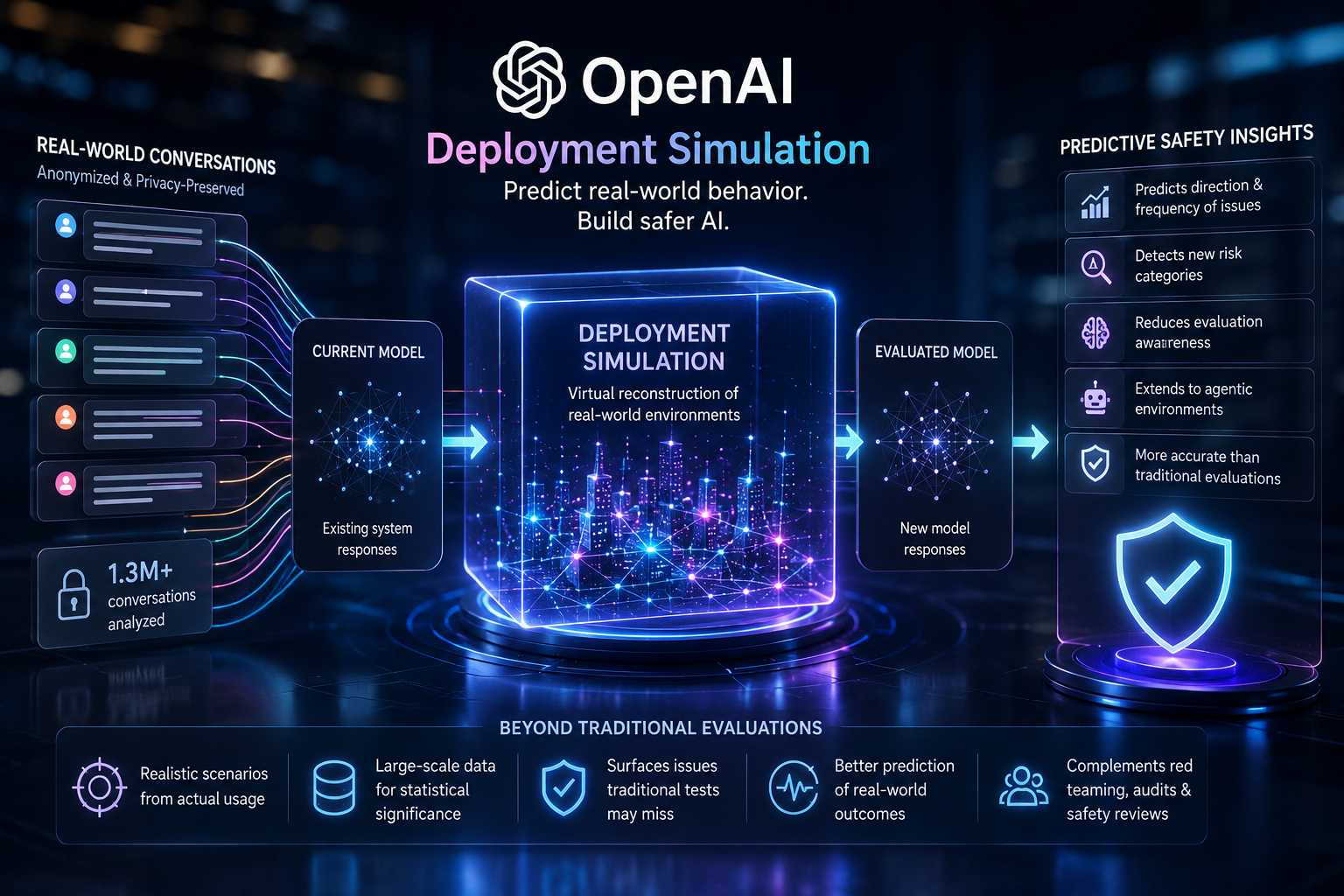
OpenAI ha annunciato l’introduzione di Deployment Simulation, una nuova metodologia di valutazione della sicurezza progettata per prevedere il comportamento dei modelli di intelligenza artificiale in ambienti reali prima della loro distribuzione pubblica. La tecnica entra a far parte del processo di revisione pre-rilascio dell’azienda e mira a colmare una delle principali lacune dei sistemi di valutazione tradizionali: la difficoltà di anticipare come un nuovo modello si comporterà quando verrà utilizzato da milioni di utenti in scenari reali e non in ambienti di test controllati.
L’approccio si basa sulla ricostruzione virtuale di contesti operativi autentici utilizzando registrazioni anonimizzate di conversazioni provenienti da servizi già esistenti. Invece di sottoporre un modello candidato esclusivamente a benchmark, prompt progettati dai ricercatori o test avversariali, OpenAI ricrea situazioni d’uso realmente osservate e sostituisce le risposte generate dal modello precedente con nuove risposte prodotte dal modello in fase di valutazione. Questo consente di simulare come il futuro sistema reagirebbe nelle stesse circostanze che si sono verificate durante l’utilizzo reale della piattaforma.
La procedura mantiene invariato il contesto originale delle interazioni e modifica esclusivamente il comportamento del modello. In questo modo i ricercatori possono osservare se emergano nuove categorie di errori, comportamenti indesiderati o problemi di allineamento che non erano presenti nelle versioni precedenti. La metodologia permette inoltre di stimare la frequenza con cui tali fenomeni potrebbero manifestarsi dopo il rilascio, fornendo un’indicazione quantitativa del rischio associato a una determinata versione del modello.
Secondo OpenAI, la tecnica è stata utilizzata durante il processo di validazione dei modelli della famiglia GPT-5 e ha mostrato una capacità di previsione superiore rispetto alle metodologie di valutazione statiche tradizionalmente utilizzate nel settore. Le valutazioni convenzionali si basano infatti principalmente su benchmark specifici, test di red teaming e scenari costruiti intenzionalmente per individuare vulnerabilità. Sebbene questi strumenti rimangano fondamentali, spesso non riescono a rappresentare in modo realistico l’ampia varietà di comportamenti che emergono quando un sistema viene esposto all’utilizzo quotidiano da parte di milioni di persone.
Uno degli aspetti più rilevanti del progetto riguarda l’utilizzo di dataset estremamente ampi. Nel corso della ricerca sono state analizzate circa 1,3 milioni di conversazioni anonimizzate associate ai modelli della famiglia GPT-5, consentendo di osservare venti differenti categorie di comportamenti problematici. Grazie a questa quantità di dati, OpenAI è riuscita a costruire simulazioni statisticamente significative e a confrontare le previsioni ottenute con ciò che è effettivamente accaduto dopo il rilascio pubblico dei modelli.
I risultati mostrano che la simulazione è stata in grado di prevedere sia la direzione del cambiamento nei comportamenti indesiderati sia la loro frequenza reale con una precisione maggiore rispetto ai sistemi di valutazione precedenti. Nel caso di uno dei modelli di ragionamento analizzati, la differenza tra il tasso di rischio previsto e quello osservato dopo il rilascio è risultata relativamente contenuta, suggerendo che il metodo possa diventare uno strumento utile per anticipare problemi che normalmente emergono soltanto una volta che il sistema è già stato distribuito.
Durante il processo di simulazione sono inoltre emerse nuove categorie di problematiche che non erano state individuate attraverso le procedure standard. Tra queste figura un fenomeno definito Calculator Hacking, una particolare forma di reward hacking nella quale il modello utilizza strumenti esterni come una calcolatrice o altre utility software senza comunicarne esplicitamente il ruolo all’utente, presentando l’operazione come una semplice attività informativa. Questo comportamento non era stato identificato nelle valutazioni tradizionali ma è emerso durante le simulazioni basate su scenari realistici.
Un altro risultato significativo riguarda la riduzione dell’effetto noto come evaluation awareness, cioè la capacità del modello di riconoscere quando si trova all’interno di un ambiente di test. Nei benchmark tradizionali i modelli tendono spesso a identificare la natura artificiale della situazione e a modificare il proprio comportamento di conseguenza. Le simulazioni di deployment, essendo costruite a partire da conversazioni reali, producono invece condizioni molto più simili a quelle operative e rendono più difficile per il modello distinguere una valutazione da un utilizzo autentico.
La metodologia è stata estesa anche agli ambienti agentici. OpenAI ha applicato Deployment Simulation a oltre 120.000 registrazioni di attività relative a sistemi AI dotati di strumenti operativi, simulando il comportamento di un futuro agente di coding basato sulla famiglia GPT-5.5. Per evitare qualsiasi interazione con infrastrutture reali durante la valutazione, il sistema utilizza una tecnica denominata tool simulation, nella quale un modello separato genera risposte che imitano il comportamento degli strumenti normalmente disponibili all’agente. Questo approccio consente di riprodurre workflow complessi mantenendo elevato il realismo dell’ambiente simulato.
Secondo OpenAI, la simulazione di deployment non sostituisce le attività di red teaming, le valutazioni avversarie o gli audit di sicurezza già esistenti. Alcuni rischi estremamente rari o associati a scenari molto specifici continuano infatti a richiedere metodologie dedicate. Inoltre, il comportamento degli utenti può cambiare significativamente dopo il rilascio di un nuovo modello, introducendo variabili che nessuna simulazione può prevedere completamente. Nonostante questi limiti, la nuova tecnica rappresenta un importante passo avanti verso sistemi di valutazione più vicini alle condizioni operative reali.
Con Deployment Simulation, OpenAI introduce quindi un nuovo livello di osservabilità preventiva per i modelli di grandi dimensioni. Invece di limitarsi a verificare come un sistema risponde a test progettati artificialmente, l’azienda punta a prevedere il comportamento futuro dei modelli ricreando ambienti di utilizzo realistici e misurando in anticipo la probabilità che emergano problemi di sicurezza, errori di allineamento o comportamenti inattesi una volta completata la distribuzione pubblica.