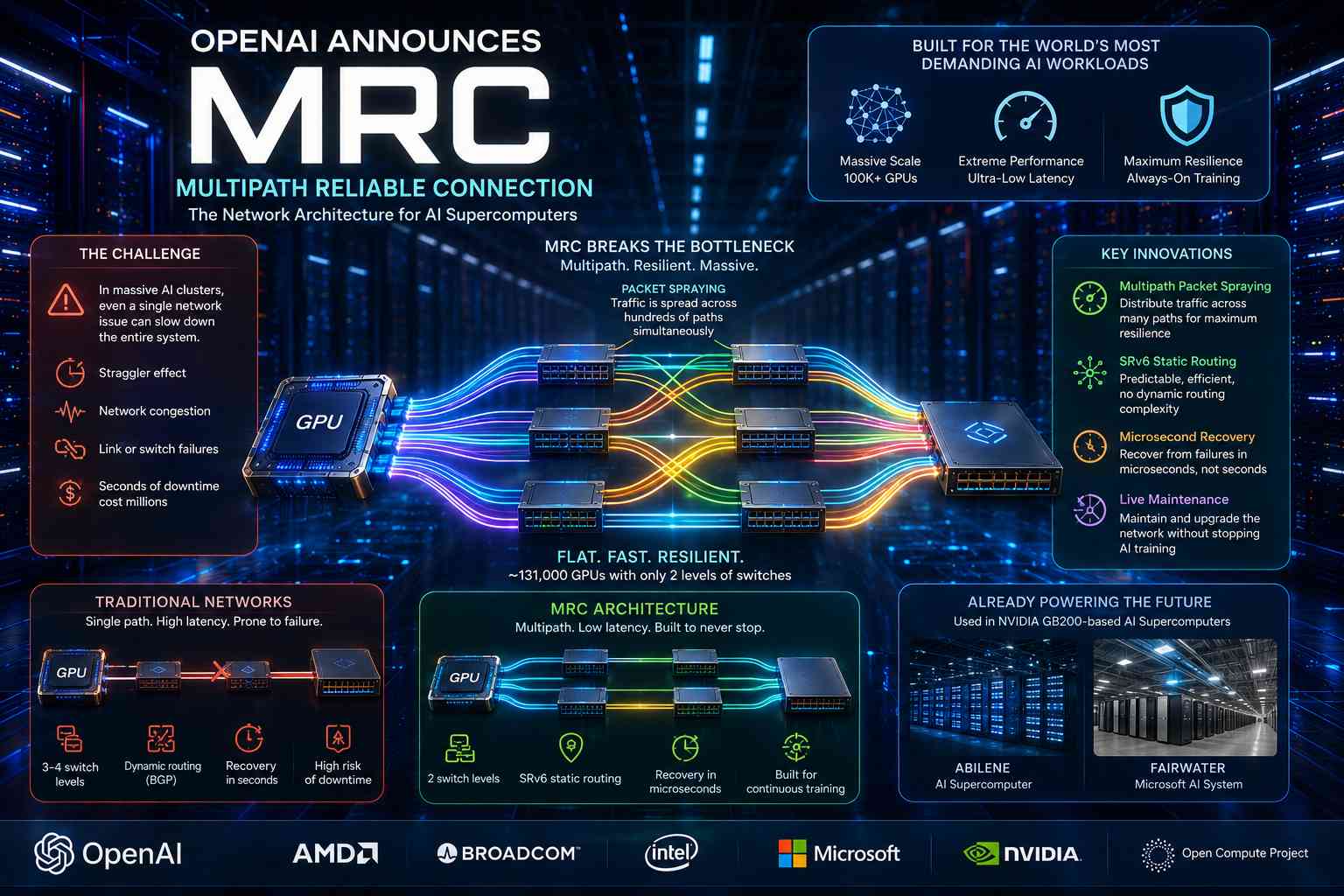
OpenAI ha annunciato il rilascio della specifica MRC, acronimo di Multipath Reliable Connection, una nuova architettura di rete progettata per gestire i carichi estremi dei supercomputer AI di nuova generazione. La tecnologia è stata sviluppata con la collaborazione di AMD, Broadcom, Intel, Microsoft e NVIDIA ed è stata pubblicata tramite l’Open Compute Project, rendendo le specifiche accessibili all’intero settore.
La presentazione di MRC evidenzia come il vero collo di bottiglia dell’intelligenza artificiale frontier non sia più soltanto la disponibilità di GPU, ma la capacità della rete di coordinare enormi volumi di elaborazione distribuita senza introdurre latenze, congestioni o guasti sistemici. Con la crescita dei modelli AI contemporanei, che richiedono cluster composti da centinaia di migliaia di acceleratori operanti simultaneamente, la rete è diventata una componente critica tanto quanto la potenza computazionale stessa.
Secondo OpenAI, MRC è stato progettato specificamente per sostenere il progetto Stargate e le future generazioni di supercomputer AI necessari a supportare infrastrutture come ChatGPT, che ormai supera i 900 milioni di utenti settimanali. In questo contesto, anche minimi ritardi di rete possono produrre effetti devastanti sulle prestazioni complessive dei sistemi distribuiti.
Il problema nasce soprattutto nei sistemi di addestramento sincrono. Durante il pretraining dei large language model, migliaia o decine di migliaia di GPU devono sincronizzare continuamente parametri, gradienti e stati intermedi. Se anche una sola GPU riceve dati in ritardo a causa di congestione o guasti di rete, l’intero cluster deve attendere il nodo più lento. Questo fenomeno viene spesso definito “straggler effect” ed è uno dei principali limiti dell’AI hyperscale contemporanea.
Nei sistemi tradizionali, anche un singolo guasto di collegamento o il riavvio di uno switch potevano rallentare l’addestramento per secondi o decine di secondi, interrompendo pipeline estremamente costose che consumano milioni di dollari di risorse computazionali ogni giorno. In cluster da centinaia di migliaia di GPU, piccoli problemi locali tendono infatti ad amplificarsi rapidamente fino a degradare l’intero sistema.
Per affrontare questo problema, MRC introduce una modifica radicale dell’architettura di rete. Invece di utilizzare singole connessioni monolitiche da 800 gigabit al secondo, la nuova struttura suddivide la banda in molteplici connessioni parallele da 100 Gb/s distribuite su differenti “piani” di rete. Questo approccio consente di creare topologie molto più piatte ed efficienti.
Secondo OpenAI, grazie a questa struttura è stato possibile collegare circa 131.000 GPU utilizzando soltanto due livelli di switch di rete, mentre le architetture tradizionali avrebbero richiesto topologie a tre o quattro livelli. Ridurre il numero di hop di rete è fondamentale nei cluster AI, perché ogni livello aggiuntivo introduce latenza, complessità e maggiori probabilità di failure.
Il cuore tecnologico di MRC è rappresentato dal packet spraying, una tecnica nella quale i pacchetti dati non vengono inviati attraverso un singolo percorso fisso, ma distribuiti simultaneamente su centinaia di percorsi differenti. In pratica, il traffico viene continuamente disperso attraverso la rete, consentendo al sistema di aggirare dinamicamente congestioni o guasti senza dover interrompere l’elaborazione.
Questo approccio è molto diverso dalle architetture di routing tradizionali utilizzate nelle reti Internet convenzionali. Nei sistemi classici, un flusso dati tende a seguire percorsi relativamente stabili definiti da protocolli dinamici come BGP. In MRC, invece, il traffico viene frammentato e distribuito continuamente su molteplici route simultanee, aumentando enormemente resilienza e tolleranza ai guasti.
Uno dei risultati più significativi dichiarati da OpenAI riguarda i tempi di recovery. Nei sistemi precedenti, il recupero da failure di rete poteva richiedere secondi interi, mentre MRC riduce questi tempi a pochi microsecondi. Per i workload AI distribuiti, questa differenza è enorme: significa che la rete riesce a compensare guasti praticamente in tempo reale senza interrompere il training.
Un altro cambiamento strutturale riguarda l’eliminazione dei protocolli di routing dinamico tradizionali come BGP. MRC utilizza invece una struttura di routing statico basata su SRv6, cioè Segment Routing over IPv6. In questo modello, il dispositivo trasmittente definisce direttamente il percorso che il pacchetto deve seguire all’interno della rete.
Dal punto di vista operativo, questo approccio riduce drasticamente la necessità per gli switch di eseguire continui ricalcoli del routing. Le reti hyperscale AI richiedono infatti stabilità estrema e prevedibilità, mentre i protocolli dinamici tradizionali introducono complessità che possono aumentare il rischio di errori e riconvergenze lente. La semplificazione del piano di controllo ottenuta tramite SRv6 riduce significativamente la probabilità di failure sistemiche. La rete diventa quindi non soltanto più veloce, ma anche più stabile e più semplice da gestire operativamente.
La tecnologia è già utilizzata concretamente all’interno dei cluster AI di nuova generazione basati su NVIDIA GB200. Tra questi figurano il supercomputer di Abilene e il sistema Fairwater sviluppato da Microsoft. Secondo quanto dichiarato, MRC sarebbe già stato impiegato per l’addestramento dei più recenti modelli frontier.
Uno degli aspetti più importanti emersi riguarda la manutenzione live dell’infrastruttura. In precedenza, il riavvio di uno switch poteva richiedere coordinamento tra team operativi e persino l’interruzione temporanea del training AI. Con MRC, l’addestramento può proseguire anche durante manutenzioni di rete o failure hardware senza impatti misurabili sulle performance.
Questo punto è fondamentale perché i futuri supercomputer AI saranno sempre più grandi e complessi. In sistemi con centinaia di migliaia o milioni di acceleratori, il verificarsi di guasti hardware diventa statisticamente inevitabile. La vera sfida non consiste più nel prevenire completamente i problemi, ma nel costruire infrastrutture capaci di continuare a operare normalmente nonostante failure continue distribuite.