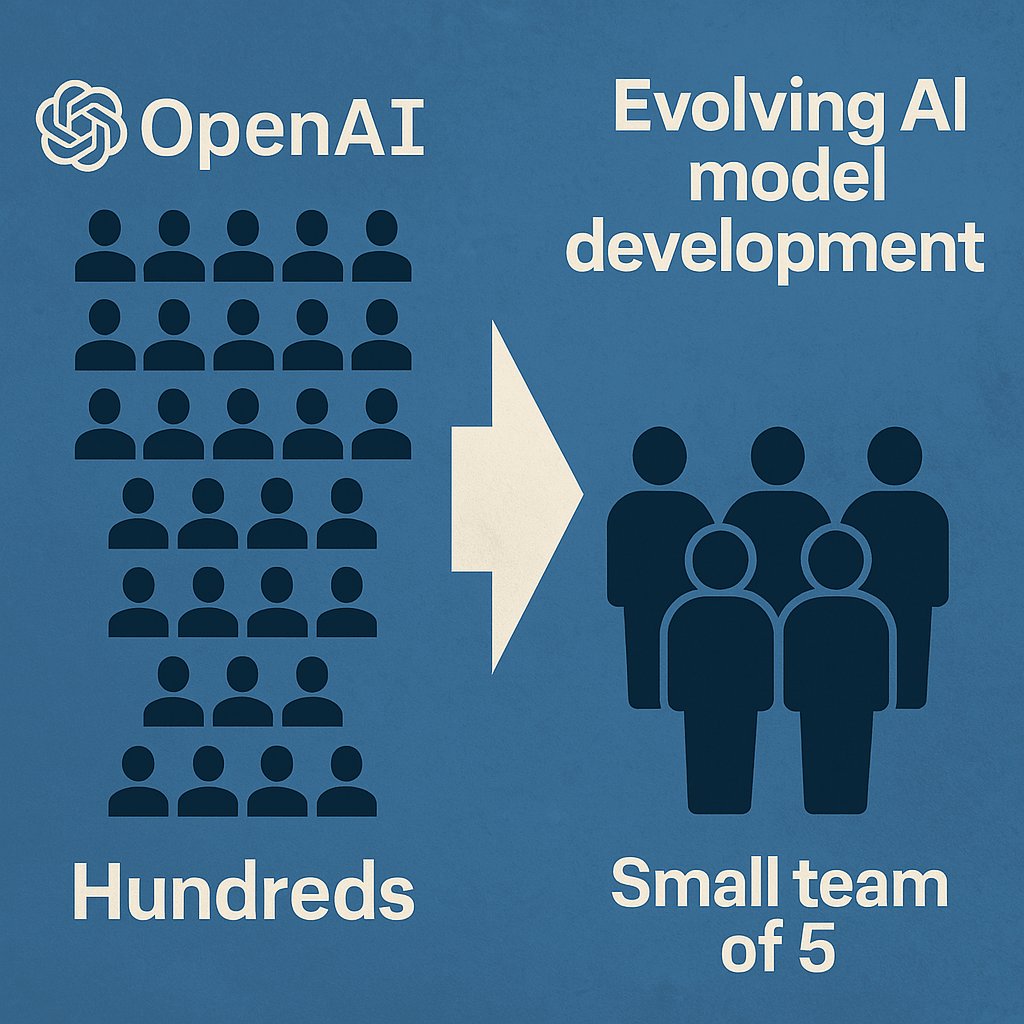
OpenAI ha condiviso un’importante riflessione sul cambiamento radicale che sta vivendo lo sviluppo dei suoi modelli di intelligenza artificiale. Grazie all’esperienza accumulata e alle tecnologie perfezionate durante la realizzazione di GPT-4.5, la fase di pre-addestramento che un tempo richiedeva l’impegno di centinaia di persone può oggi essere gestita da un piccolo team, composto da appena cinque individui.
Lo ha rivelato Sam Altman, CEO di OpenAI, nel corso di un podcast ufficiale andato in onda l’11 aprile, insieme a tre degli ingegneri chiave che hanno lavorato allo sviluppo di GPT-4.5. Altman ha raccontato come, durante la creazione di GPT-4, l’azienda avesse investito quasi tutte le sue risorse disponibili, mobilitando centinaia di persone. Oggi, però, quel tipo di modello non rappresenta più lo stato dell’arte, e può essere replicato con un team molto più snello.
Alex Paino, uno degli ingegneri responsabili della fase di pre-addestramento di GPT-4.5, ha spiegato che, se oggi OpenAI dovesse ripartire da zero con GPT-4, un gruppo di cinque o dieci persone sarebbe sufficiente per portare a termine il compito. Inoltre, ha aggiunto che il team che ha lavorato a GPT-4o – l’attuale modello di punta – era ancora più piccolo, proprio grazie alle conoscenze accumulate con GPT-4.5.
Secondo Daniel Selsom, ricercatore di OpenAI, una volta che si è riusciti a costruire con successo un modello di questo tipo, replicarlo diventa più semplice. Ha paragonato il processo a “una chiave ingannevole”: difficile da forgiare la prima volta, ma molto più facile da copiare dopo.
Tuttavia, il percorso verso GPT-4.5 non è stato lineare. Nonostante fosse stato presentato a febbraio come il modello più grande e potente mai realizzato, durante lo sviluppo OpenAI ha incontrato ostacoli inattesi. Le prestazioni iniziali non erano all’altezza delle aspettative, tanto da costringere il team a rivedere l’intero processo e ricominciare la fase di pre-addestramento da capo.
Questa esperienza ha portato alcuni ricercatori a sollevare una questione importante: forse la cosiddetta “legge del ridimensionamento” dell’intelligenza artificiale – secondo cui bastano più dati e più potenza computazionale per ottenere modelli migliori – sta iniziando a perdere validità. Il miglioramento delle prestazioni non sembra più così direttamente proporzionale all’aumento delle risorse impiegate.
Gli ingegneri coinvolti nello sviluppo di GPT-4.5 avevano inizialmente previsto un modello dieci volte più potente di GPT-4, addestrandolo su una scala mai vista prima. Ma ora la prospettiva è cambiata: secondo Altman, stiamo assistendo a un vero e proprio cambio di paradigma. Se prima l’informatica era vista come una risorsa scarsa e limitante, oggi questo vincolo sembra superato.
Altman ha sottolineato che non è più la disponibilità di infrastrutture computazionali a limitare la costruzione di nuovi modelli, ma piuttosto la fase di inferenza, ovvero il modo in cui l’IA viene utilizzata per fornire risposte. È questo il nuovo centro nevralgico dello sviluppo, e rappresenta una rivoluzione che, secondo lui, il mondo non ha ancora compreso fino in fondo.
Per questo motivo, il CEO di OpenAI ha annunciato che GPT-4.5 sarà l’ultimo modello sviluppato secondo la vecchia logica. Tutti i futuri modelli di punta, ha dichiarato, saranno pensati sin dall’inizio per integrare al meglio le capacità inferenziali, segnando l’inizio di una nuova era per l’intelligenza artificiale.