Negli ultimi mesi, il dibattito sull’intelligenza artificiale nelle aziende si è concentrato sempre più sugli “agenti”, sistemi autonomi capaci di eseguire compiti complessi senza supervisione continua. In questo scenario, molte organizzazioni stanno investendo in architetture multi-agente, cioè sistemi composti da più entità AI che collaborano tra loro. Tuttavia, un’analisi recente mette in discussione questa tendenza e introduce un concetto destinato a far discutere: quello della “swarm tax”, ovvero il costo nascosto dei sistemi AI troppo complessi.
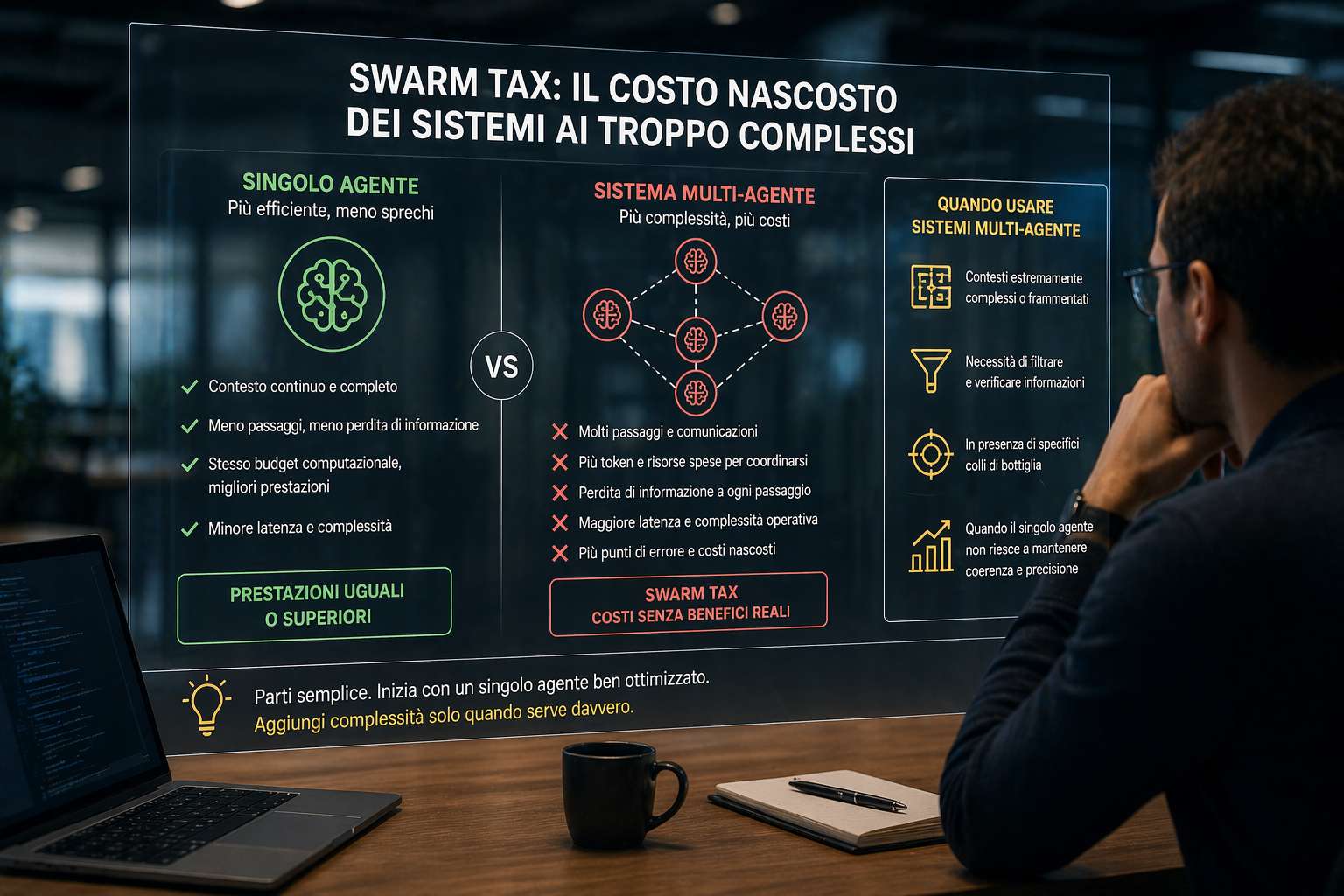
L’idea alla base è semplice ma controintuitiva. Più agenti non significano automaticamente migliori prestazioni. Anzi, in molti casi, la complessità aggiuntiva introduce inefficienze che riducono il vantaggio teorico della collaborazione tra modelli. La ricerca citata, condotta da Stanford, mostra infatti che quando si mettono a confronto sistemi a singolo agente e sistemi multi-agente con lo stesso budget computazionale, i primi riescono spesso a eguagliare o addirittura superare i secondi in compiti di ragionamento complesso.
Il punto chiave riguarda il modo in cui vengono utilizzate le risorse. I sistemi multi-agente, per loro natura, richiedono più passaggi intermedi: ogni agente elabora una parte del problema, comunica con gli altri, riceve input, rielabora. Questo processo genera un numero maggiore di interazioni e, soprattutto, un uso più elevato di token e capacità computazionale. In altre parole, parte della “potenza” del sistema viene spesa per coordinarsi, non per risolvere il problema.
È qui che nasce la cosiddetta “swarm tax”. Le aziende che adottano architetture multi-agente senza un’analisi approfondita rischiano di pagare un costo extra, non sempre giustificato da un reale miglioramento delle prestazioni. Questo costo non è solo economico, ma anche operativo: maggiore latenza, più complessità nel debugging, più punti di errore e una gestione più difficile dell’intero sistema.
Un altro aspetto cruciale riguarda la qualità del ragionamento. Nei sistemi multi-agente, le informazioni vengono continuamente suddivise, sintetizzate e trasferite da un agente all’altro. Questo introduce un problema strutturale: ogni passaggio può comportare una perdita di informazione. I ricercatori spiegano questo fenomeno attraverso il principio della “Data Processing Inequality”, secondo cui ogni trasformazione dei dati rischia di ridurne il contenuto informativo. Al contrario, un singolo agente che opera all’interno di un contesto continuo mantiene una visione più completa del problema, risultando spesso più efficiente.
Questo non significa che i sistemi multi-agente siano inutili. Al contrario, esistono scenari in cui diventano fondamentali. Quando il contesto è estremamente complesso, frammentato o degradato, un singolo agente può faticare a mantenere coerenza e precisione. In questi casi, suddividere il problema tra più agenti può aiutare a filtrare le informazioni, verificare i risultati e gestire meglio l’incertezza. Tuttavia, la loro utilità emerge solo in presenza di specifici colli di bottiglia, non come soluzione universale.
La riflessione più interessante riguarda quindi l’approccio progettuale. Per anni, nello sviluppo software e nei sistemi distribuiti, la complessità è stata spesso vista come una leva per aumentare le prestazioni. Nel caso dell’AI agentica, questa logica sembra non valere sempre. La ricerca suggerisce che il punto di partenza dovrebbe essere un sistema semplice, basato su un singolo agente ben ottimizzato, e che l’introduzione di ulteriori agenti debba essere una scelta mirata, guidata da esigenze precise e misurabili.
Questo cambio di prospettiva ha implicazioni dirette per le aziende. In un contesto in cui l’AI viene integrata nei processi operativi, scegliere l’architettura giusta significa bilanciare prestazioni, costi e affidabilità. Adottare sistemi multi-agente senza una reale necessità può portare a soluzioni più costose e difficili da gestire, senza benefici proporzionati.