Nelle applicazioni aziendali, molte sfide richiedono un pensiero strategico e una risoluzione di problemi complessi. Tradizionalmente, i modelli di linguaggio di grandi dimensioni (LLM) hanno mostrato limitazioni nel gestire compiti che richiedono un ragionamento multi-step e l’uso di strumenti esterni. Tuttavia, un nuovo approccio, noto come Step-Wise Reinforcement Learning (SWiRL), sviluppato da ricercatori di Stanford University e Google DeepMind, promette di superare queste barriere, offrendo un’IA in grado di affrontare compiti complessi con la stessa efficacia dei migliori risolutori di problemi umani.
Le applicazioni aziendali del mondo reale spesso comportano processi articolati che necessitano di più passaggi. Ad esempio, la pianificazione di una campagna di marketing complessa può includere ricerche di mercato, analisi dei dati interni, calcolo del budget e revisione dei ticket di supporto clienti. Questi compiti richiedono l’accesso a motori di ricerca, database interni e l’esecuzione di codice. I metodi tradizionali di apprendimento per rinforzo, come il Reinforcement Learning from Human Feedback (RLHF), si concentrano principalmente su compiti di ragionamento a singolo passaggio e non sono ottimizzati per affrontare sequenze complesse di azioni.
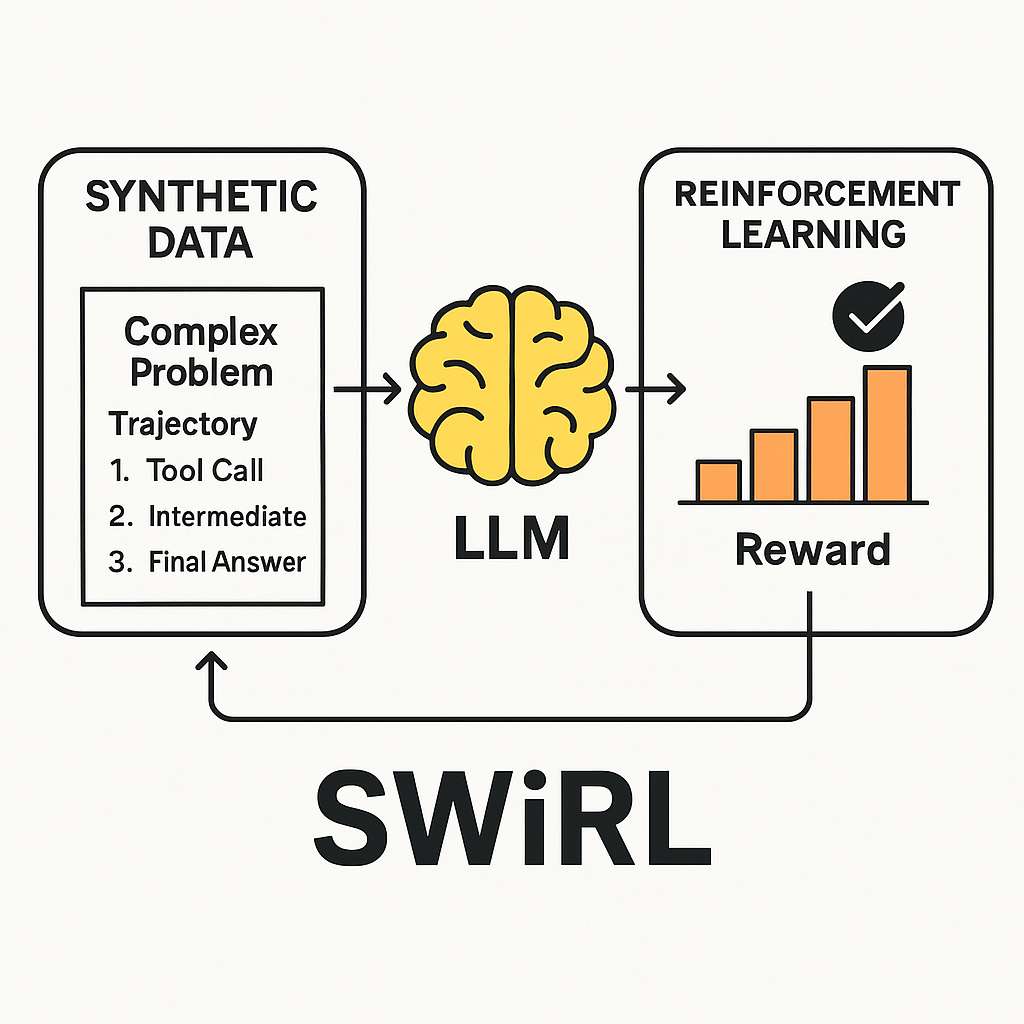
SWiRL è una tecnica che combina la generazione di dati sintetici con un approccio di apprendimento per rinforzo specializzato, addestrando i modelli su intere sequenze di azioni. L’obiettivo è insegnare al modello come scomporre problemi complessi in sotto-compiti più gestibili, quando e come utilizzare gli strumenti, come formulare una chiamata agli strumenti e come sintetizzare efficacemente i risultati. Questo approccio consente di affrontare compiti che richiedono l’integrazione di più strumenti e ragionamento multi-step.
Il primo stadio di SWiRL comporta la creazione di dati sintetici da cui il modello apprende. Un LLM ha accesso a uno strumento pertinente, come un motore di ricerca o una calcolatrice. Il modello viene quindi sollecitato iterativamente a generare una “traiettoria”, una sequenza di passaggi per risolvere un dato problema. Ad ogni passaggio, il modello può generare un ragionamento interno, chiamare uno strumento o produrre la risposta finale. Se il modello chiama uno strumento, la query viene estratta, eseguita (ad esempio, viene effettuata una ricerca) e il risultato viene reinserito nel contesto del modello per il passaggio successivo. Questo processo continua fino a quando il modello fornisce una risposta finale.
Nel secondo stadio, SWiRL utilizza l’apprendimento per rinforzo per addestrare un LLM di base sulle traiettorie sintetiche generate. Ad ogni passaggio all’interno di una traiettoria, il modello viene ottimizzato per prevedere l’azione successiva appropriata (un passaggio di ragionamento intermedio, una chiamata a uno strumento o la risposta finale) in base al contesto precedente. Il modello riceve feedback ad ogni passaggio da un modello di ricompensa generativo separato, che valuta l’azione generata dal modello dato il contesto fino a quel punto. Questo paradigma di affinamento granulare consente al modello di apprendere sia la decisione locale (previsione del passaggio successivo) sia l’ottimizzazione globale della traiettoria (generazione della risposta finale), guidato dal feedback immediato sulla validità di ogni previsione.
Il team di Stanford e Google DeepMind ha valutato SWiRL su diversi compiti complessi di risposta a domande e ragionamento matematico. Rispetto ai modelli di base, SWiRL ha mostrato significativi miglioramenti di accuratezza, con incrementi relativi che vanno dall’11% al 21% su dataset come GSM8K, HotPotQA, MuSiQue e BeerQA. Gli esperimenti hanno confermato che l’addestramento di un modello Gemma 2-27B con SWiRL su dati filtrati per processo ha prodotto i migliori risultati, superando i modelli addestrati su dati filtrati per risultato o utilizzando il tradizionale Supervised Fine-Tuning (SFT). Questo suggerisce che SWiRL apprende il processo di ragionamento sottostante in modo più efficace, piuttosto che limitarsi a memorizzare i percorsi verso risposte corrette, il che aiuta le prestazioni su problemi non visti.
L’approccio SWiRL ha implicazioni significative per le aziende che desiderano integrare modelli di ragionamento nelle loro applicazioni e flussi di lavoro. La capacità di affrontare compiti complessi che richiedono l’uso di più strumenti e ragionamento multi-step può migliorare l’efficienza operativa e la qualità delle decisioni. Inoltre, la generalizzazione osservata in SWiRL suggerisce che un modello di IA aziendale addestrato su un compito principale utilizzando SWiRL potrebbe mostrare significativi miglioramenti delle prestazioni su altri compiti apparentemente non correlati senza un affinamento specifico del compito.