L’annuncio di “Pegasus 1.5” da parte di Twelve Labs introduce un paradigma che ridefinisce il modo in cui i video vengono interpretati, organizzati e utilizzati all’interno dei processi aziendali. Non si tratta di un miglioramento incrementale delle capacità di ricerca o tagging, ma di una trasformazione profonda che porta il video da oggetto passivo di consultazione a sistema attivo di dati interrogabili.
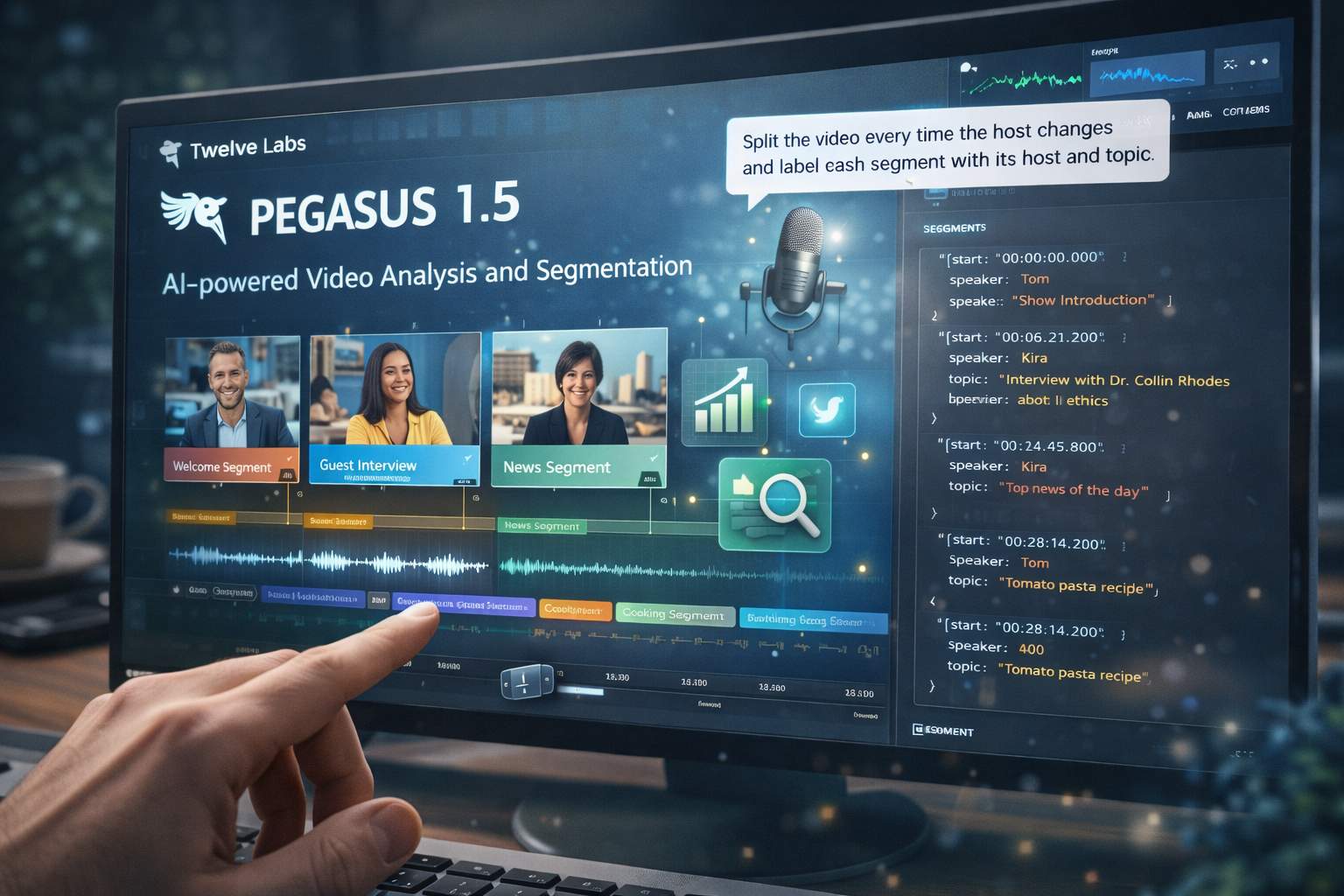
Il cuore dell’innovazione risiede nell’introduzione della tecnologia di estrazione di metadati basata sul tempo, definita TBM, che consente al modello di segmentare automaticamente un video in unità coerenti e semanticamente significative. Questo approccio supera il limite storico degli strumenti di analisi video, che si concentravano sulla rilevazione di elementi isolati o sulla risposta a query specifiche, senza essere in grado di costruire una struttura completa e navigabile del contenuto. Pegasus 1.5, al contrario, opera su un livello superiore, in cui la segmentazione diventa un processo di progettazione strutturale guidato da istruzioni in linguaggio naturale.
Il sistema si basa su un’integrazione multimodale avanzata che combina segnali visivi, audio e contestuali in un unico processo decisionale. I segnali visivi comprendono elementi a basso livello come i cambi di inquadratura, le variazioni di illuminazione e i tagli di montaggio, che permettono di identificare discontinuità nella sequenza delle immagini. A questi si aggiungono segnali di alto livello, legati alla comprensione narrativa, come il passaggio da un argomento all’altro o l’ingresso di nuovi personaggi. Il contributo audio include il riconoscimento dei cambi di interlocutore, le variazioni nella musica di sottofondo e l’analisi degli effetti sonori. La componente più sofisticata emerge nella sintesi di questi segnali, che consente al modello di determinare con precisione i confini dei segmenti attraverso l’interazione tra livelli informativi differenti.
Questa architettura permette a Pegasus 1.5 di raggiungere un livello di accuratezza temporale particolarmente elevato, con margini di errore nell’ordine dei 350 millisecondi. In termini operativi, significa che ogni segmento identificato è accompagnato da codici temporali estremamente precisi, che rendono possibile un utilizzo diretto dei dati per applicazioni downstream. Il risultato finale non è semplicemente una lista di scene o eventi, ma una rappresentazione strutturata del video, spesso in formato JSON, che include informazioni dettagliate su contenuti, protagonisti e contesto.
Il cambiamento più rilevante riguarda però l’interfaccia tra utente e sistema. Mentre le generazioni precedenti, come Pegasus 1.2, richiedevano interazioni iterative basate su query specifiche, il nuovo modello introduce un approccio dichiarativo, in cui l’utente definisce direttamente la struttura desiderata del video. Un’istruzione come “dividi il video ogni volta che cambia il conduttore e associa a ciascun segmento il nome e l’argomento trattato” viene interpretata dal sistema come un obiettivo progettuale, non come una semplice richiesta di ricerca. L’intelligenza artificiale esegue quindi un’analisi completa del contenuto e restituisce un output già organizzato secondo i criteri richiesti.
Il video non viene più esplorato in modo sequenziale o frammentato, ma viene trasformato in una struttura dati coerente che può essere direttamente integrata in sistemi informativi, pipeline di produzione o piattaforme di distribuzione. Le implicazioni sono particolarmente evidenti nei settori che gestiscono grandi volumi di contenuti, come media, intrattenimento e broadcasting, dove l’indicizzazione manuale rappresentava fino a oggi un costo operativo significativo. L’introduzione della ricerca multimodale avanzata rafforza ulteriormente questo paradigma. La possibilità di individuare elementi all’interno di un video utilizzando immagini, oltre al linguaggio naturale, amplia il concetto stesso di query, rendendolo più aderente alla complessità dei contenuti visivi. Questo tipo di interazione riduce la dipendenza da descrizioni testuali e consente di accedere a informazioni difficilmente codificabili con parole, migliorando l’efficienza e l’accuratezza delle operazioni di analisi.
Pegasus 1.5 è progettato per gestire video di lunga durata, fino a due ore, con una singola chiamata API. Questo aspetto non è secondario, poiché indica una capacità di scalabilità che lo rende adatto a contesti enterprise, in cui l’elaborazione batch di grandi archivi video è una necessità operativa. La possibilità di ottenere in un’unica operazione una struttura completa del contenuto rappresenta un vantaggio competitivo significativo in termini di tempo e risorse.
Le prestazioni dichiarate evidenziano un miglioramento tangibile rispetto ai modelli generalisti, con un incremento del 13,1% nella qualità della segmentazione rispetto a Google Gemini 3.1 Pro. Questo dato suggerisce che l’ottimizzazione specifica per il dominio video consente di superare i limiti dei modelli linguistici general-purpose, che pur essendo versatili non sono progettati per gestire la complessità temporale e multimodale dei contenuti audiovisivi.