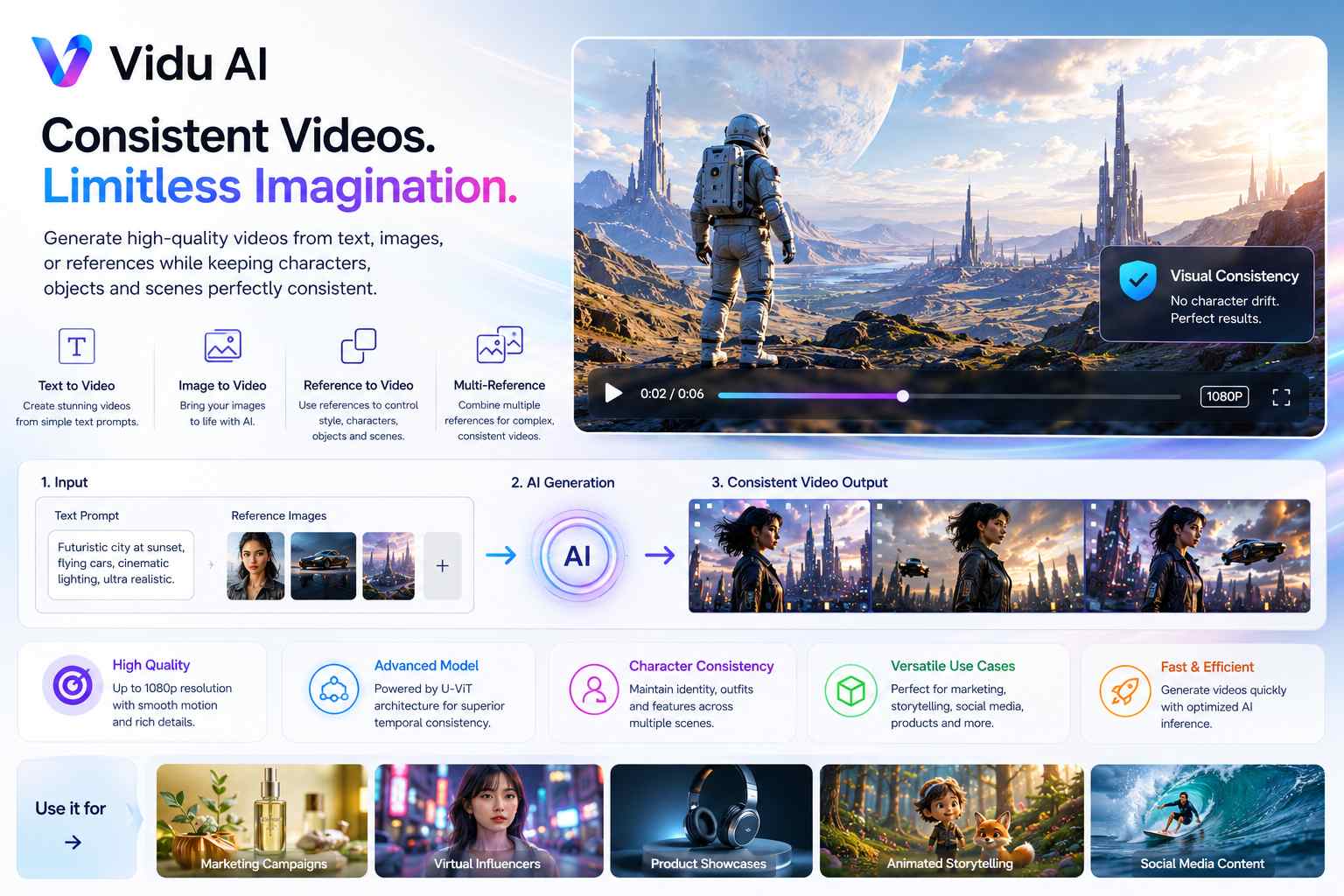
La generazione video basata su intelligenza artificiale ha raggiunto un nuovo livello di maturità grazie all’evoluzione dei modelli in grado di mantenere coerenza visiva tra personaggi, oggetti e ambientazioni. Tra le piattaforme che stanno puntando maggiormente su questo aspetto c’è Vidu AI, un sistema di generazione video sviluppato per creare contenuti partendo da prompt testuali, immagini di riferimento o combinazioni di entrambi.
La piattaforma integra diverse modalità operative che consentono di produrre video a partire da testo, trasformare immagini statiche in sequenze animate oppure utilizzare elementi visivi di riferimento per controllare in modo più preciso il risultato finale. L’obiettivo è ridurre uno dei principali limiti storici dei modelli generativi video: la perdita di coerenza tra fotogrammi e tra clip successive.
Uno degli elementi centrali dell’architettura di Vidu è il sistema Reference to Video, progettato per utilizzare immagini di riferimento come vincolo creativo durante la generazione. Invece di affidarsi esclusivamente all’interpretazione di un prompt testuale, il modello riceve uno o più riferimenti visivi che definiscono l’aspetto di personaggi, oggetti, ambientazioni, stili grafici e persino movimenti di camera. Questo approccio permette di conservare caratteristiche visive specifiche lungo l’intera sequenza video, limitando le variazioni indesiderate che spesso compaiono nei sistemi text-to-video tradizionali.
La piattaforma supporta anche l’utilizzo simultaneo di più immagini di riferimento. Questa funzionalità consente di gestire scene con diversi soggetti mantenendo l’identità visiva di ciascuno durante l’animazione. In ambito creativo ciò permette di costruire brevi narrazioni con più personaggi, mentre nel settore marketing può essere utilizzata per preservare la riconoscibilità di prodotti, loghi e asset aziendali in differenti clip video. Le tecnologie di multi-reference generation rappresentano infatti uno degli sviluppi più rilevanti dell’attuale generazione di modelli video, poiché affrontano il problema della cosiddetta “character drift”, ovvero la tendenza dei personaggi a cambiare aspetto durante la generazione.
Accanto alla modalità Reference to Video è disponibile il sistema Image to Video, destinato all’animazione di immagini singole. In questo scenario l’utente fornisce una fotografia, un’illustrazione o un rendering e il modello genera automaticamente movimenti della scena, della telecamera o dei soggetti presenti nell’immagine. Questa modalità viene utilizzata frequentemente per trasformare concept art, fotografie di prodotto, immagini generate da modelli text-to-image o materiali grafici destinati ai social media in brevi contenuti video dinamici.
Dal punto di vista tecnico, Vidu deriva da una linea di ricerca orientata alla generazione video mediante modelli diffusion e architetture Transformer specializzate per dati visivi. I lavori presentati dal team di sviluppo descrivono l’utilizzo di una struttura basata su Universal Vision Transformer (U-ViT), progettata per gestire sequenze video ad alta risoluzione mantenendo continuità spaziale e temporale tra i fotogrammi. Questo approccio permette di produrre video fino a 1080p e di estendere la durata delle sequenze rispetto alle prime generazioni di modelli text-to-video.
Un altro aspetto interessante riguarda la gestione della continuità narrativa. Nei workflow più avanzati è possibile utilizzare più immagini di riferimento contemporaneamente per definire personaggi, oggetti e scenari che dovranno rimanere coerenti attraverso diverse inquadrature. Il sistema combina tali riferimenti con il prompt testuale, cercando di preservare caratteristiche come abbigliamento, colori, dettagli del volto, texture degli oggetti e composizione generale della scena. Questo consente di costruire contenuti multi-scena più complessi rispetto ai normali video generati da una singola immagine.
Per i creator digitali, i team marketing e le aziende che producono contenuti social, la possibilità di mantenere elementi visivi consistenti rappresenta un vantaggio operativo significativo. Un personaggio virtuale può essere riutilizzato in più video senza dover essere rigenerato ogni volta da zero, mentre un prodotto può mantenere dimensioni, colori e dettagli riconoscibili in campagne composte da numerose clip differenti. Lo stesso principio può essere applicato alla creazione di influencer virtuali, contenuti promozionali, storytelling animato e presentazioni di prodotto.
La piattaforma include inoltre strumenti per la generazione video da prompt testuali tradizionali, nei quali il modello costruisce automaticamente ambientazioni, movimenti e soggetti partendo esclusivamente dalla descrizione fornita dall’utente. In questi casi l’intelligenza artificiale interpreta elementi come illuminazione, stile visivo, tipo di ripresa, azioni e atmosfera della scena, producendo un video coerente con le indicazioni ricevute.
L’evoluzione dei sistemi come Vidu evidenzia una tendenza sempre più evidente nel settore della generazione video: il passaggio da semplici animazioni guidate da testo a piattaforme orientate al controllo preciso della continuità visiva. La capacità di utilizzare riferimenti multipli, mantenere identità costanti e preservare elementi grafici lungo sequenze differenti rappresenta infatti uno dei requisiti fondamentali per portare la produzione video generativa da strumento sperimentale a tecnologia utilizzabile in contesti professionali.