È affascinante immaginare un’intelligenza artificiale che “pensa” come noi, un po’ passo dopo passo, come se stesse riflettendo ad alta voce. Questa immagine è ciò che il prompting di tipo “Chain‑of‑Thought” (CoT) ha saputo evocare in molti. Ma secondo una recentissima ricerca dell’Arizona State University (ASU), pubblicata su archivio open-access, quell’apparente flusso di logica è, in realtà, un miraggio. È un’illusione fragile, dipendente dal fatto che il modello riconosce pattern già incontrati… più che dal fatto che stia realmente ragionando.
Il prompting CoT funziona così: si chiede al modello di eseguire una “riflessione” strutturata, e spesso ottieni risposte che sembrano seguire un ragionamento logico coerente. Tuttavia, secondo i ricercatori della ASU, non è tanto che l’intelligenza artificiale abbia una comprensione profonda, quanto che replica sequenze simili viste durante l’addestramento. Questo significa che di fronte a problemi completamente nuovi, il ragionamento va in frantumi—perché non si basa su idee, ma su memorizzazione e pattern già noti
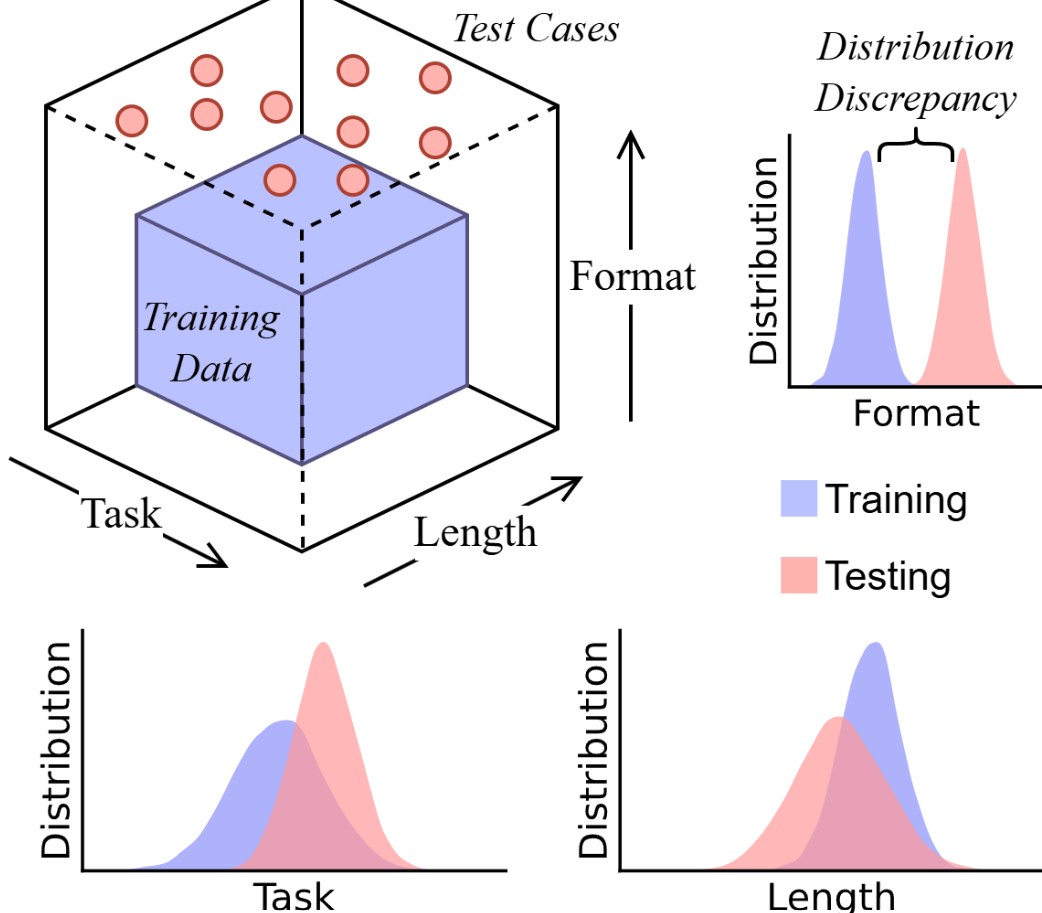
Lo studio si è concentrato su tre criteri chiave per verificare la “robustezza” del CoT:
- Generalizzazione verso problemi sconosciuti. Il modello tende a fallire quando affronta problemi che non rispecchiano direttamente quelli usati durante l’addestramento.
- Gestione della lunghezza logica. Se la sequenza di ragionamento richiesta è più lunga (o più breve) del solito, il modello tende ad adattare artatamente la risposta—anziché ragionare autenticamente.
- Sensibilità alla forma del prompt. Anche modeste variazioni nel prompt (orizzontali o stilistiche) fanno crollare la coerenza: il modello è fragile rispetto a piccoli cambiamenti nel modo in cui viene interrogato
I ricercatori hanno trovato che applicare una fase di fine-tuning supervisionato (SFT) con un piccolo dataset mirato può ripristinare rapidamente le performance. Ma anche in questo caso, si tratta solo di “aggiungere un nuovo pattern alla memoria” del modello—non di dotarlo di una vera abilità di pensiero flessibile.
A prescindere dallo spettacolo che mette in scena, il CoT non può essere considerato un alleato affidabile in contesti che richiedono solidità intellettuale—come finanza, medicina o diritto. Illeggibile ma verosimile, il “ragionare” dei modelli resta un “nonsense fluente”, e per questo è rischioso usarli senza una supervisione umana.
Per contrastare il rischio, gli autori suggeriscono di testare i modelli fuori dalla loro “zona di comfort” (i cosiddetti OOD tests, out-of-distribution), esponendoli a formati, lunghezze e strutture diverse per capire realmente fino a dove arriva l’intelligenza artificiale.
In definitiva, questo studio mette a nudo una verità essenziale: il ragionamento apparente degli LLM attraverso il CoT è più illusorio che reale, e regge solo quando il modello ritrova qualcosa di familiare. Ma in un mondo dove l’imprevisto è la norma, quell’effetto “pensato” può rivelarsi un semplice effetto scenico. Serve prudenza, test severi – e soprattutto, un’accurata supervisione umana per discernere tra ciò che sembra logico e ciò che è realmente ragionato.