La crescente diffusione dei modelli linguistici di grandi dimensioni ha riacceso il dibattito sulla cosiddetta “scatola nera” dell’intelligenza artificiale: sistemi capaci di produrre risposte sofisticate ma difficili da spiegare in termini di processo decisionale interno. In questo contesto, la startup statunitense Guide Labs ha presentato un nuovo modello open source, Steerling-8B, con 8 miliardi di parametri, progettato sin dall’origine per rendere tracciabile e interpretabile la generazione delle risposte. A differenza degli approcci tradizionali, che cercano di analizzare retroattivamente modelli già addestrati, Guide Labs ha costruito l’architettura con un modulo concettuale integrato che consente di osservare e controllare i contributi interni che portano a ciascun token prodotto.
Il principio chiave alla base di Steerling-8B è la possibilità di ricondurre ogni token generato alle componenti concettuali che ne hanno determinato l’emissione. In termini operativi, ciò significa che il modello non si limita a fornire un output finale, ma rende esplicito quanto ciascun concetto latente abbia contribuito alla previsione. Questa trasparenza supera il tradizionale paradigma delle spiegazioni post hoc, che tentano di inferire le motivazioni di un modello a partire dai risultati già calcolati, senza accesso diretto alla dinamica interna del calcolo.
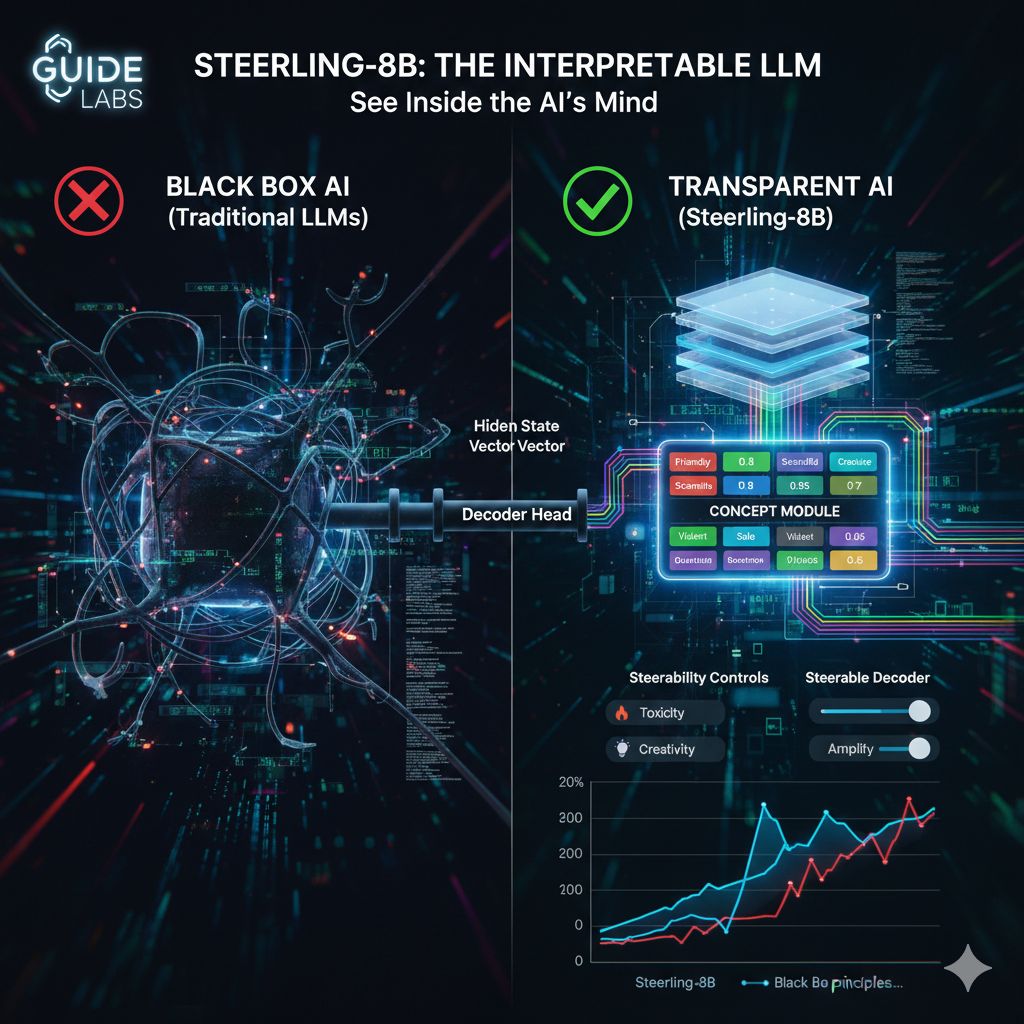
L’elemento architetturale centrale è il cosiddetto Concept Module, uno strato sottile inserito tra la spina dorsale del trasformatore e la testa di output. In un LLM convenzionale, lo stato nascosto finale viene trasmesso direttamente alla testa di decodifica sotto forma di vettore numerico ad alta dimensionalità, contenente migliaia di valori. In Steerling-8B, questo vettore viene prima scomposto in un insieme di “valori concettuali” interpretabili, come ad esempio “Amichevole 0,8” o “Scientifico 0,9”. Successivamente, tali concetti vengono ricombinati e riconvertiti in rappresentazioni numeriche per produrre il token finale. Il modello introduce dunque un collo di bottiglia semantico, in cui le informazioni interne sono mappate su dimensioni leggibili dall’uomo prima di essere tradotte nuovamente in forma computazionale.
Questo meccanismo consente non solo di osservare, ma anche di intervenire sul comportamento del modello. La cosiddetta “steerability”, ovvero la capacità di sterzare il modello verso o lontano da determinati comportamenti, diventa una proprietà intrinseca dell’architettura. Se un utente formula una richiesta potenzialmente pericolosa, come istruzioni per costruire un ordigno, è possibile sopprimere concetti legati alla violenza o alla tossicità direttamente nel modulo concettuale. Il risultato non è un semplice blocco della risposta, ma una deviazione naturale verso contenuti sicuri. Questo approccio consente di rafforzare o attenuare concetti specifici senza dover riaddestrare il modello o applicare filtri esterni complessi.
Uno degli aspetti più significativi riguarda le prestazioni. Storicamente, rendere un modello più interpretabile ha comportato una perdita di capacità predittiva, poiché la semplificazione dei processi interni tende a limitare la complessità rappresentazionale. Guide Labs sostiene invece che Steerling-8B raggiunge circa il 90% delle prestazioni di modelli comparabili della stessa classe dimensionale. Inoltre, il modello segue la legge di scala tipica degli LLM: aumentando dati e risorse computazionali, le prestazioni migliorano progressivamente. Questo suggerisce che l’approccio concettuale possa essere esteso a modelli di dimensioni superiori senza sacrificare competitività rispetto ai sistemi di frontiera.
Un ulteriore vantaggio evidenziato riguarda la scalabilità economica. Nei modelli più piccoli, l’aggiunta di un modulo di analisi introduce un overhead significativo rispetto alla capacità complessiva del sistema. Con una dimensione di 8 miliardi di parametri, l’onere computazionale relativo del Concept Module si riduce, rendendo l’architettura più efficiente in termini di costi. In prospettiva, modelli più grandi potrebbero beneficiare di un impatto proporzionalmente ancora minore dell’overhead interpretativo.
Il progetto è guidato dal cofondatore e CEO Julius Adebayo, noto per il suo lavoro del 2018 sulle mappe di salienza, che dimostrò come molte tecniche di visualizzazione interpretativa fossero in realtà poco affidabili. All’epoca, evidenziare con colori vivaci le aree di un’immagine considerate rilevanti da un modello non implicava una reale comprensione semantica, ma poteva essere il risultato di correlazioni spurie. Questa esperienza ha portato Adebayo alla convinzione che l’interpretabilità non potesse essere aggiunta ex post, ma dovesse essere incorporata nel design architetturale fin dall’inizio.
Un punto critico spesso sollevato riguarda il rischio che vincolare l’output a concetti interpretabili limiti la creatività e la capacità di generalizzazione del modello. Tuttavia, secondo Guide Labs, l’analisi interna di Steerling-8B ha mostrato l’emergere di concetti non esplicitamente presenti nei dati di training. Un esempio citato è l’elaborazione autonoma del concetto di “calcolo quantistico”, che il modello avrebbe costruito collegando conoscenze apprese durante l’addestramento. Questo suggerisce che un’architettura interpretabile non impedisce la formazione di nuove astrazioni, ma può anzi renderle osservabili.
Le implicazioni applicative sono ampie. In settori regolamentati come finanza, diritto e medicina, la capacità di spiegare in modo tracciabile le decisioni di un sistema AI è fondamentale per conformità normativa e responsabilità legale. Anche nella ricerca scientifica, un modello capace di esplicitare i concetti che utilizza potrebbe diventare uno strumento di supporto più affidabile per l’analisi e la generazione di ipotesi.
Dal punto di vista industriale, Guide Labs, ex partecipante a Y Combinator, ha raccolto 9 milioni di dollari in finanziamenti seed nel novembre 2024 e prevede di sviluppare versioni più ampie del modello, offrendo accesso tramite API e integrazione con agenti AI. L’obiettivo dichiarato è dimostrare che un’architettura interpretabile può non solo competere con i modelli più avanzati, ma eguagliarne le prestazioni su larga scala.
Steerling-8B rappresenta dunque un tentativo concreto di ripensare l’ingegneria dei modelli linguistici, spostando l’attenzione dall’analisi retrospettiva alla progettazione trasparente. Se l’approccio si dimostrerà scalabile, potrebbe segnare una transizione verso una nuova generazione di sistemi AI in cui prestazioni e interpretabilità non siano più considerate obiettivi in conflitto, ma proprietà complementari integrate nell’architettura stessa.