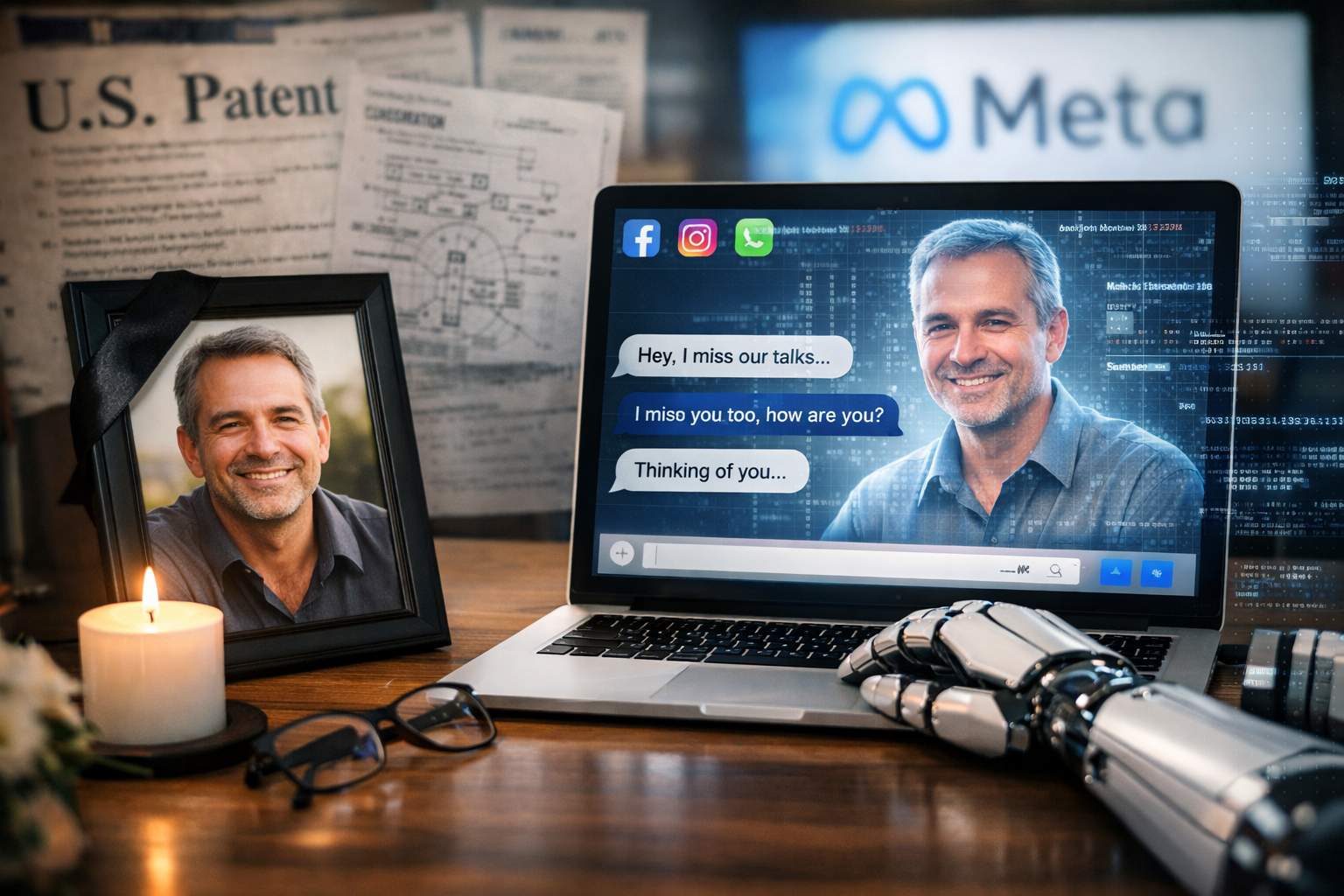
Meta Platforms, la società madre di Facebook, Instagram e WhatsApp, ha ottenuto negli Stati Uniti un brevetto per una tecnologia di intelligenza artificiale che potrebbe, in teoria, continuare a gestire la presenza digitale di una persona anche dopo la sua morte o durante una sua prolungata assenza dalla piattaforma. Il documento, depositato nel 2023 e reso pubblico solo di recente, è firmato dal Chief Technology Officer di Meta, Andrew Bosworth, e descrive un sistema basato su modelli linguistici avanzati — i cosiddetti large language model (LLM) — in grado di ricostruire profili di interazione a partire da dati storici dell’utente stesso, come post, messaggi, commenti, like e reazioni.
La logica tecnica alla base del brevetto è relativamente semplice: un algoritmo di apprendimento automatico analizza enormi quantità di contenuti generati dall’utente nel corso del tempo per apprenderne stile, tono comunicativo e pattern di comportamento. Una volta addestrato, questo modello potrebbe generare testi, risposte, commenti o persino messaggi privati coerenti con quelli che l’utente avrebbe scritto. In prospettiva, il sistema potrebbe persino supportare interazioni multimodali più complesse, inclusi contenuti multimediali, chiamate o video, sebbene un’applicazione del genere rimanga puramente speculativa e non annunciata ufficialmente da Meta.
È importante sottolineare che la concessione di un brevetto non implica automaticamente lo sviluppo o l’implementazione di un prodotto destinato agli utenti. Un portavoce di Meta ha infatti chiarito, in dichiarazioni riportate dalla stampa, che al momento non esistono piani concreti per trasformare questa tecnologia in un servizio reale sulle piattaforme social. In altre parole, il brevetto registra un’idea tecnologica, ma la sua effettiva traduzione in un’applicazione concreta non è né programmata né garantita. Questa pratica di brevettare concetti in fase teorica è comune nell’industria tecnologica per tutelare proprietà intellettuali potenziali senza impegnarsi a un’immediata commercializzazione.
Dal punto di vista ingegneristico, l’idea di un bot specifico per singoli individui (a volte definito nei media come “deathbot” o “griefbot”) rappresenta un caso estremo di personalizzazione dei modelli linguistici. Questi agenti digitali user-specific, come vengono descritti nel brevetto, non si limitano a rispondere a input generici, ma sono pensati per imitare stili di conversazione e comportamenti assai personali. Per realizzarlo servirebbe una raccolta estremamente ampia di dati storici e una serie di filtri di contesto per adattare le risposte in modo rilevante e coerente. Tuttavia, anche i modelli di grande scala attuali, sebbene capaci di generare testi coerenti, non possiedono una comprensione “cosciente” dell’identità dell’utente, bensì operano attraverso pattern statistici appresi dai dati.
Sul versante delle normative e delle implicazioni legali, l’idea solleva questioni complesse. In molti ordinamenti, la gestione dei dati personali dopo la morte è regolata da leggi specifiche: in Italia, ad esempio, il Codice della privacy contempla diritti e limiti relativi alle informazioni di persone decedute, mentre all’interno dell’Unione Europea il Regolamento Generale sulla Protezione dei Dati (GDPR) pone ulteriori paletti sulla liceità del trattamento di dati sensibili, anche post mortem. Tali regolamenti richiederebbero, qualora una tecnologia del genere venisse sviluppata, meccanismi rigorosi di consenso e protezione dei diritti dei soggetti coinvolti o dei loro eredi.
Accanto agli aspetti legali, i tecnici e i filosofi della tecnologia evidenziano come questo tipo di applicazione sfiori temi più ampi di digital legacy e digital immortality, concetti che riguardano la possibilità di preservare o estendere digitalmente la presenza di una persona oltre la sua esistenza fisica. In teoria, immaginari digitali potrebbero diventare persistenti non solo sui social, ma anche in ambienti virtuali o archivi di memoria digitale, continuando a generare contenuti autonomamente. Questa prospettiva è stata ampiamente discussa in letteratura teorica sul concetto di immortality digitale, che esplora le implicazioni di creare copie digitali di personalità umane.
Una delle criticità centrali nella realizzazione tecnica di tali sistemi riguarda la qualità e la naturalezza delle interazioni generate. Anche i modelli linguistici più avanzati possono produrre risposte plausibili ma non sempre affidabili, rischiando di generare contenuti inappropriati, fuori contesto o addirittura offensivi se non adeguatamente filtrati. Inoltre, un sistema che simula conversazioni private potrebbe violare aspettative di riservatezza e fiducia tra gli utenti, esponendo informazioni intime a un trattamento automatizzato non voluto dal soggetto originale.
Infine, benché Meta non abbia annunciato un prodotto basato su questo brevetto, la semplice esistenza di una tecnologia di questo tipo alimenta il dibattito pubblico su come le piattaforme digitali gestiranno in futuro le identità, le memorie e il lutto nell’era dell’intelligenza artificiale. I tecnologi, i filosofi e i giuristi concordano sul fatto che l’integrazione di sistemi così avanzati nei contesti quotidiani richiederebbe una riflessione approfondita sulle norme etiche, sulla protezione dei dati e sulla distinzione tra simulazioni digitali e relazioni umane autentiche.