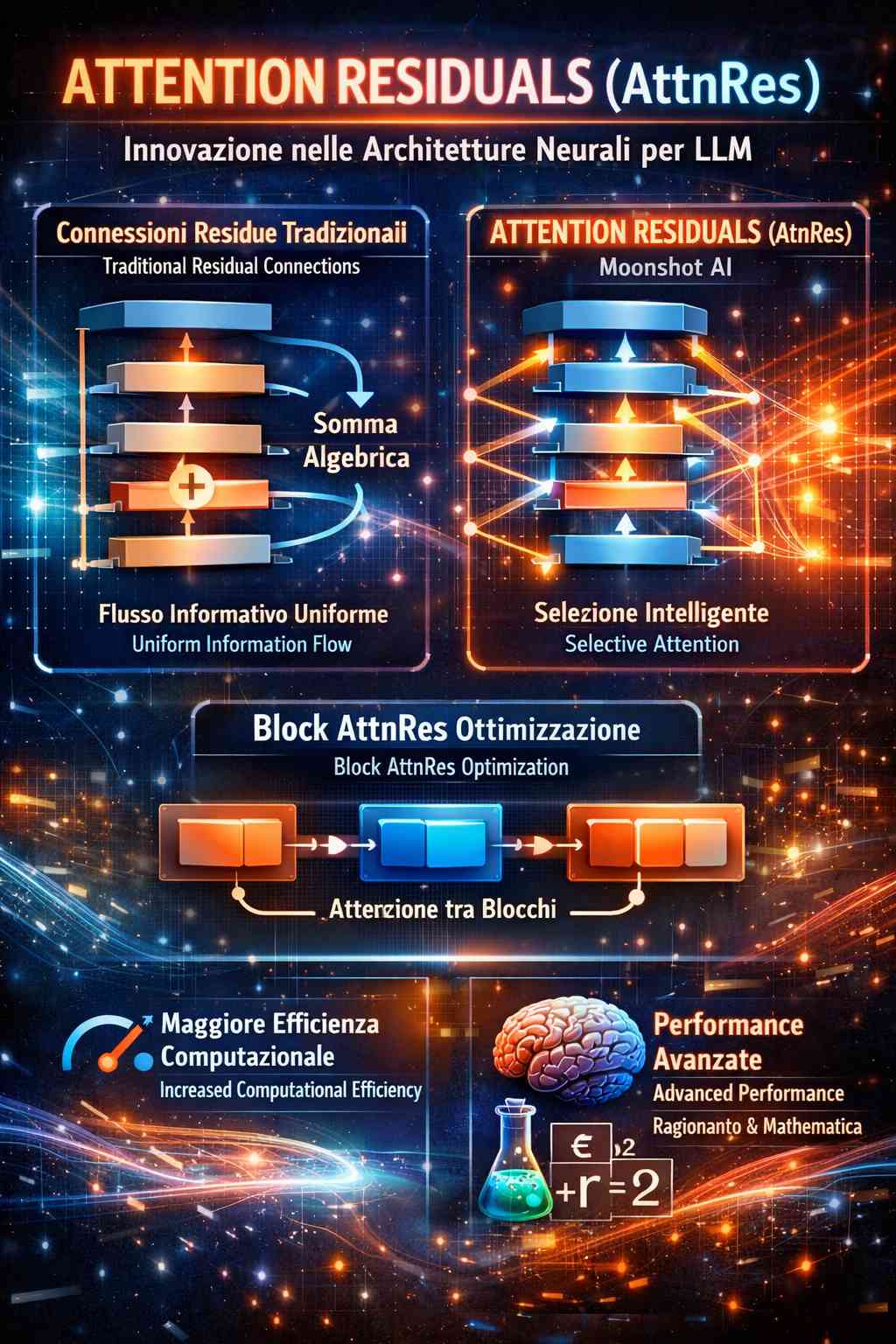
Una delle innovazioni più significative nell’ambito delle architetture neurali per LLM è rappresentata dal metodo Attention Residuals (AttnRes), sviluppato dai ricercatori di Moonshot AI per sostituire le convenzionali connessioni residue. Questa tecnologia interviene su uno dei componenti fondamentali che permettono l’addestramento di reti profonde, proponendo un sistema di gestione del flusso informativo non più basato sulla semplice somma algebrica, ma su una selezione intelligente dei dati attraverso la profondità della rete.
Le connessioni residue tradizionali sono state introdotte originariamente per risolvere il problema del “gradiente svanito”, permettendo ai segnali di apprendimento di viaggiare attraverso decine di strati senza perdere efficacia. Tecnicamente, queste connessioni creano una scorciatoia che somma l’input di uno strato direttamente al suo output, passando il risultato alla fase successiva. Tuttavia, questa struttura accumulativa presenta un’inefficienza intrinseca: poiché le informazioni di tutti gli strati precedenti vengono combinate con lo stesso peso, l’importanza di segnali specifici tende a diluirsi man mano che il modello diventa più profondo. Questo fenomeno costringe gli strati finali a produrre output di ampiezza sempre maggiore per riuscire a influenzare il risultato, portando a una saturazione del segnale e a una gestione inefficiente dello stato nascosto.
Il metodo Attention Residuals rivoluziona questo concetto applicando il meccanismo di attenzione non solo all’interno dei dati di input, ma lungo l’asse della profondità della rete stessa. Invece di limitarsi a sommare i contributi passati in modo uniforme, ogni strato della rete neurale agisce ora come un’unità decisionale capace di recuperare selettivamente solo le informazioni rilevanti dagli strati precedenti. Attraverso l’assegnazione di pesi dinamici, il sistema è in grado di amplificare le caratteristiche fondamentali generate nelle fasi iniziali dell’elaborazione e di sopprimere i dati ridondanti o il rumore. Questo approccio garantisce un controllo granulare su come la conoscenza viene preservata o scartata durante il passaggio attraverso l’architettura gerarchica.
L’implementazione di un sistema di attenzione totale su tutti i livelli precedenti comporterebbe un incremento esponenziale del carico computazionale e del consumo di memoria, rendendo il modello impraticabile per l’uso su larga scala. Per mitigare questo problema, il team di ricerca ha introdotto la variante Block AttnRes. Questa architettura suddivide gli strati della rete in blocchi distinti, all’interno dei quali le informazioni vengono compresse in un singolo valore rappresentativo. L’operazione di attenzione viene quindi eseguita esclusivamente tra questi blocchi, riducendo drasticamente i costi di comunicazione tra i nodi di calcolo e l’utilizzo di memoria VRAM. Grazie a questa ottimizzazione, l’impatto sulla latenza di inferenza rimane inferiore al 2%, rendendo la tecnologia compatibile con i moderni ambienti di calcolo parallelo.
L’efficacia di questa riprogettazione strutturale è stata confermata su Kimi Linear, un modello basato sull’architettura Mixed of Experts (MoE) con 48 miliardi di parametri totali. L’adozione di Attention Residuals ha permesso di incrementare l’efficienza computazionale di 1,25 volte, mantenendo quasi invariata la velocità di risposta. I risultati ottenuti nei benchmark tecnici evidenziano progressi marcati soprattutto nelle aree che richiedono una logica rigorosa e passaggi sequenziali complessi. Ad esempio, nei test di ragionamento scientifico avanzato e matematica, il modello ha mostrato una capacità superiore di mantenere la coerenza del ragionamento, suggerendo che AttnRes rappresenti una soluzione ideale per i modelli di prossima generazione in cui la profondità della rete deve tradursi in una reale capacità di analisi multilivello.