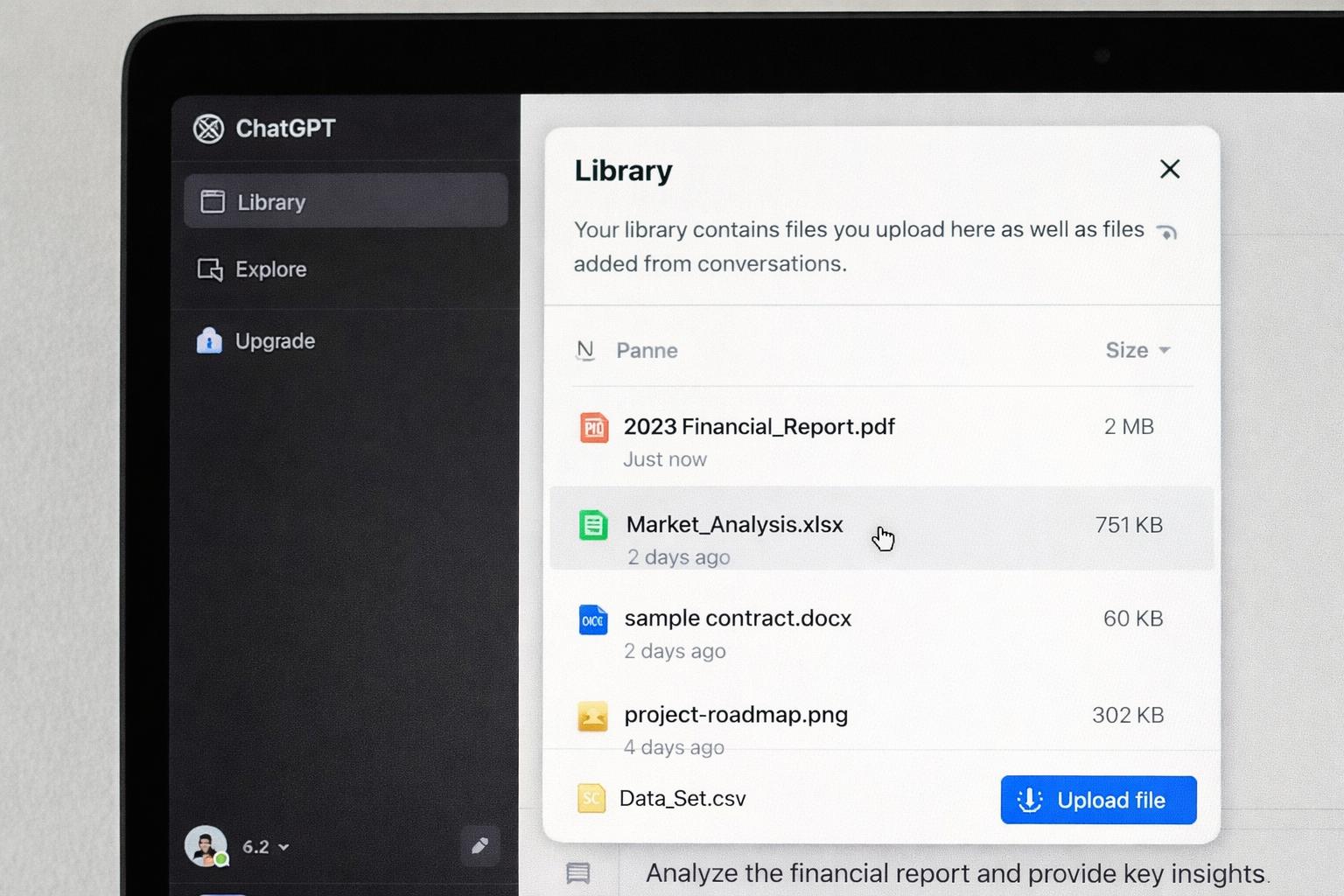
La nuova funzione “Library” introdotta in ChatGPT mira a semplificare l’accesso ai file caricati e a consentirne il riutilizzo in contesti differenti. Il cambiamento non riguarda solo l’interfaccia, ma il modello operativo complessivo dell’interazione con i documenti, che passa da un uso episodico e legato alla singola conversazione a una gestione persistente e organizzata nel tempo.
Secondo quanto riportato da Analytics India Magazine, la nuova Library è progettata per aiutare gli utenti a gestire, recuperare e riutilizzare i file caricati in ChatGPT in modo più efficiente, superando la frammentazione tipica delle sessioni isolate. Questa funzionalità consente di archiviare documenti, immagini e altri contenuti in uno spazio centralizzato, accessibile attraverso conversazioni diverse, riducendo la necessità di caricare nuovamente gli stessi file e migliorando la continuità del lavoro.
Dal punto di vista tecnico, la Library introduce un livello di persistenza dei contenuti che modifica l’architettura dell’interazione con il modello. In precedenza, i file caricati erano strettamente associati a una singola chat e il loro riutilizzo richiedeva operazioni manuali. Con la Library, i documenti diventano risorse condivise, consultabili e riutilizzabili in più contesti. Questo approccio avvicina ChatGPT a un sistema di knowledge management, in cui i contenuti caricati vengono trattati come asset informativi permanenti, piuttosto che input temporanei.
La funzione assume particolare rilevanza per flussi di lavoro complessi. In ambito professionale, l’analisi documentale spesso richiede iterazioni successive su report, contratti o dataset. La possibilità di mantenere questi file in una Library consente di costruire un contesto progressivo, in cui l’AI può fare riferimento a materiali già caricati senza doverli reinserire. Questo riduce il tempo operativo e rende più efficiente la collaborazione tra utenti e modello, soprattutto quando si lavora su progetti multi-fase o su documentazione estesa.
L’introduzione della Library ha anche implicazioni per la produttività. Il riutilizzo dei documenti consente di creare flussi iterativi, come aggiornamenti periodici di report, revisione di documenti legali o analisi ripetute su dataset. In questi scenari, l’AI non parte più da zero a ogni interazione, ma può costruire sulle informazioni già disponibili. Questo approccio riduce la ridondanza e migliora la coerenza tra output generati in momenti diversi.