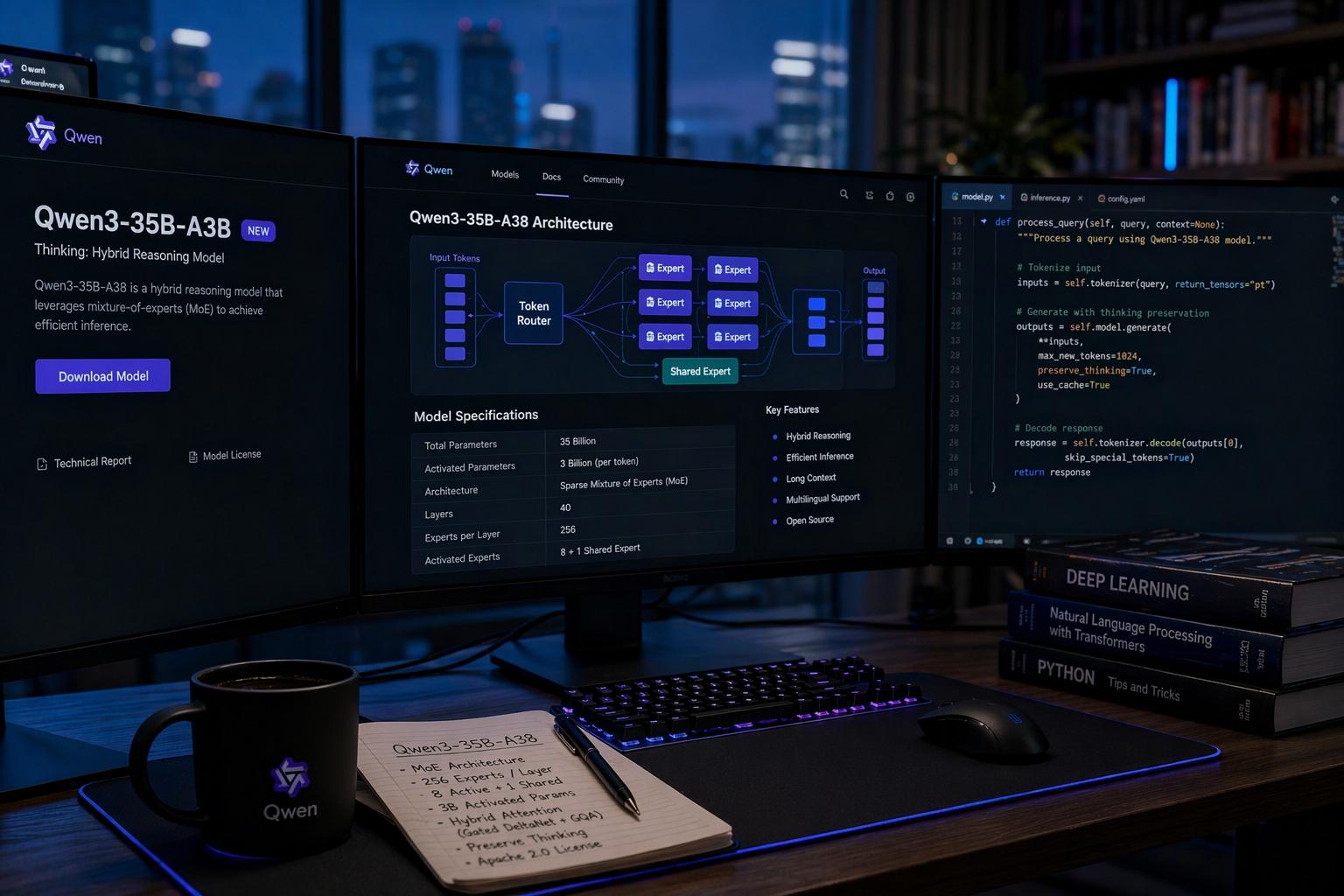
L’evoluzione dei modelli linguistici sta attraversando una fase di profonda ottimizzazione, in cui il parametro del successo non è più la semplice dimensione del modello, ma l’efficienza con cui ogni calcolo viene eseguito. Alibaba ha consolidato questa tendenza con il rilascio di Qwen 3.6-35B-A3B, un modello open-source che sfrutta un’architettura Sparse Mixture of Experts (MoE) per ridefinire il rapporto tra prestazioni e costi operativi. Nonostante una struttura complessiva da 35 miliardi di parametri, il sistema ne attiva soltanto circa 3 miliardi per ogni singola operazione di inferenza. Questo approccio permette di mantenere una densità informativa elevata pur operando con requisiti computazionali tipici di modelli molto più piccoli, rendendo l’intelligenza artificiale di alto livello accessibile anche su infrastrutture non faraoniche.
Il modello implementa una configurazione avanzata composta da 40 strati, dove la gestione dei token avviene attraverso un sistema di 256 esperti per ogni layer MoE. Il meccanismo di routing è estremamente raffinato: per ogni token vengono attivati 8 esperti specializzati più un esperto condiviso (Shared Expert), garantendo che la conoscenza comune sia sempre disponibile mentre la specializzazione viene delegata ai rami più competenti della rete. Questa struttura è supportata da un sistema di attenzione ibrida che combina il Gated DeltaNet (un meccanismo di attenzione lineare) con la Grouped Query Attention (GQA), ottimizzando drasticamente l’uso della memoria video e la velocità di elaborazione, specialmente su sequenze lunghe.
Una delle innovazioni tecniche più significative introdotte in questa release è la funzionalità preserve_thinking. Nelle versioni precedenti, il processo di ragionamento (“Chain of Thought”) veniva spesso rigenerato da zero a ogni turno di conversazione, con un notevole spreco di token e risorse. Con Qwen 3.6-35B-A3B, il modello è in grado di preservare le tracce di ragionamento dei turni precedenti, riutilizzando il contesto logico già elaborato per risolvere compiti a più fasi. Questa capacità è fondamentale per la codifica agentica, dove il sistema non si limita a generare snippet isolati, ma opera come un partner di sviluppo autonomo capace di gestire flussi di lavoro complessi, modificare intere repository e mantenere la coerenza logica attraverso decine di chiamate a strumenti esterni (tool calls).
Sul fronte delle capacità multimodali, il modello si posiziona ai vertici della categoria, superando in alcuni benchmark di visione artificiale modelli proprietari come Claude Sonnet 4.5. L’integrazione nativa tra visione e linguaggio permette a Qwen 3.6-35B-A3B di eccellere nel ragionamento spaziale e nella comprensione visiva precisa, ottenendo punteggi elevatissimi in test come RefCOCO e ODInW13. Questa sensibilità visiva, unita alla logica di programmazione, lo rende ideale per compiti di sviluppo frontend automatizzato, dove l’IA deve interpretare un design visivo e tradurlo in codice funzionale mantenendo una spazialità coerente degli elementi.
L’accessibilità rimane un pilastro della strategia di Alibaba, che ha rilasciato i pesi del modello sotto licenza Apache 2.0, permettendone il download tramite piattaforme come HuggingFace e l’auto-hosting su server privati. Grazie alla compatibilità con le specifiche API di OpenAI e Anthropic, l’integrazione di Qwen 3.6-35B-A3B nei flussi di lavoro esistenti risulta immediata. In definitiva, questo modello rappresenta la prova tangibile che l’architettura MoE, se correttamente bilanciata tra esperti attivi e parametri totali, può superare in termini di ragionamento e precisione anche modelli densi molto più grandi, portando le capacità di un’IA di classe “flagship” direttamente nelle mani degli sviluppatori indipendenti e delle imprese.