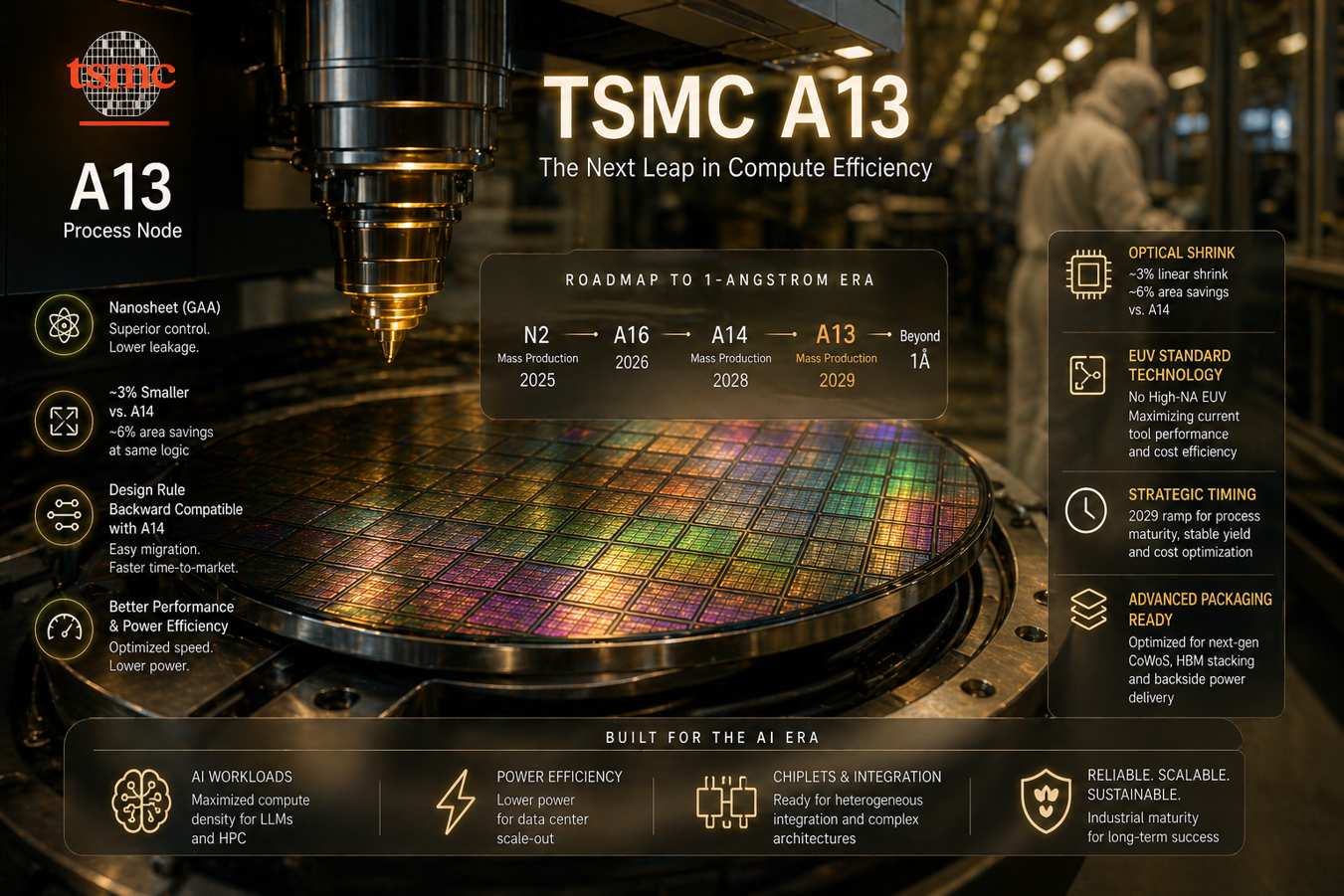
L’annuncio del nuovo nodo di processo A13 da parte di TSMC, avvenuto durante il recente North America Technology Symposium, delinea la traiettoria della fonderia taiwanese verso l’era dell’angstrom, consolidando una roadmap che punta tutto sull’efficienza del calcolo per l’intelligenza artificiale. Nonostante la presentazione immediata delle specifiche tecniche, la decisione di fissare l’inizio della produzione di massa nel 2029 risponde a una precisa strategia di ottimizzazione industriale e di gestione del ciclo di vita dei transistor nanosheet, piuttosto che a un ritardo tecnologico, garantendo una transizione sostenibile verso densità di calcolo sempre più elevate.
Il nodo A13 si posiziona come un’evoluzione diretta e raffinata del precedente processo A14, rappresentando quello che in termini di ingegneria dei semiconduttori viene definito un “optical shrink”. Questa metodologia permette a TSMC di ridurre le dimensioni lineari di circa il 3% rispetto all’A14, traducendosi in un risparmio di area del chip del 6% a parità di logica contenuta. L’aspetto tecnicamente più rilevante per i progettisti di hardware AI è la totale compatibilità retroattiva delle regole di design tra i nodi A14 e A13. Questa continuità permette ai partner strategici di TSMC di migrare le proprie architetture esistenti verso il nuovo nodo con uno sforzo di ri-progettazione minimo, accelerando la distribuzione di processori più efficienti senza dover riscrivere interamente i layout dei circuiti.
L’architettura alla base dell’A13 continua a sfruttare la tecnologia dei transistor nanosheet, nota anche come Gate-all-around (GAA), che ha sostituito la struttura FinFET per garantire un controllo superiore del canale e una drastica riduzione delle correnti di dispersione su scala atomica. L’incremento prestazionale dell’A13 non deriva solo dalla riduzione fisica, ma anche da un processo di ottimizzazione congiunta tra design e tecnologia. Questo approccio permette di estrarre maggiore velocità di commutazione agendo sulla disposizione fisica dei transistor, ottimizzando il rapporto tra potenza dissipata e capacità di calcolo, un fattore critico per i processori destinati ai data center che devono gestire carichi di lavoro massivi legati ai Large Language Models.
La scelta di avviare la produzione nel 2029, a circa un anno di distanza dal debutto dell’A14 previsto per il 2028, è motivata da una complessa gestione della catena di fornitura e dei costi di capitale. TSMC ha confermato che non intende adottare le nuove macchine per litografia EUV ad alta apertura numerica (High-NA EUV) per i nodi immediati, inclusi l’A14 e l’A13. Questa decisione è dettata dalla volontà di massimizzare il rendimento delle attuali tecnologie EUV standard attraverso tecniche avanzate di esposizione multipla, evitando i costi proibitivi dei nuovi strumenti ASML che graverebbero sul prezzo finale dei wafer. Slittando la produzione al 2029, TSMC garantisce una maturazione dei processi produttivi che permette ai clienti di ammortizzare gli investimenti fatti sulle architetture a 2 nanometri e sulle loro varianti.
Inoltre, il posizionamento temporale dell’A13 consente di allineare il rilascio del silicio con l’avanzamento delle tecnologie di packaging avanzato. Entro il 2029, le soluzioni di integrazione su sistema, come il CoWoS di nuova generazione, saranno in grado di ospitare un numero significativamente maggiore di chiplet e stack di memoria HBM su un singolo interposer. L’A13 si integra perfettamente in questo ecosistema, offrendo una densità logica ottimizzata che lavora in sinergia con altre innovazioni, come l’alimentazione dal retro del wafer (backside power delivery), per risolvere i problemi di caduta di tensione tipici dei chip ad altissime prestazioni. In definitiva, il nodo A13 rappresenta il culmine di una strategia di raffinamento iterativo, dove la stabilità operativa e la compatibilità del design prevalgono sulla corsa forzata a nuove macchine litografiche.