Kakao ha presentato una panoramica delle prestazioni e dello sviluppo del suo modello linguistico multimodale integrato, denominato “Kanana-o”, e del modello linguistico audio “Kanana-a”, attraverso il suo blog tecnologico ufficiale. Questi modelli rappresentano un passo significativo nell’evoluzione dell’intelligenza artificiale, mirando a una comunicazione più naturale e umana.
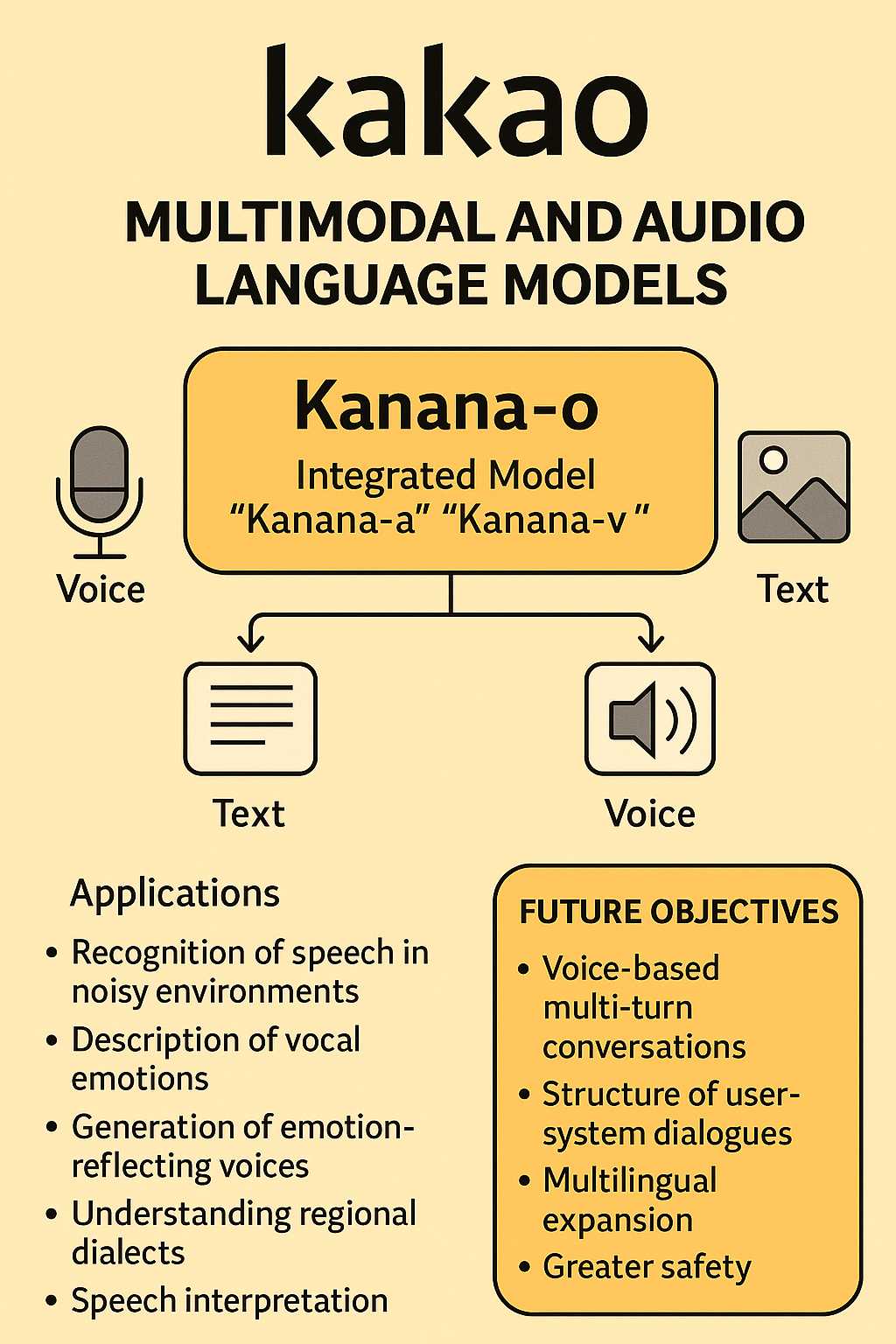
Kanana-o è progettato per ricevere input sotto forma di voce, immagini e testo, rispondendo in modo appropriato con testo o voce, a seconda della situazione. Questa capacità consente una serie di applicazioni avanzate, tra cui:
- Riconoscimento vocale in ambienti rumorosi.
- Descrizione delle emozioni vocali.
- Generazione di voci che riflettono le emozioni.
- Comprensione dei dialetti regionali.
- Interpretazione vocale.
- Comprensione delle immagini e risposta vocale.
Questo modello è il risultato dell’integrazione dei modelli multimodali “Kanana-v” e “Kanana-a”, pubblicati nel dicembre dello scorso anno. L’unione di questi modelli specializzati in attività diverse in uno solo ha il vantaggio di ridurre i tempi di formazione, rendendo il sistema più efficiente.
Kanana-v è stato addestrato utilizzando dati di coppie immagine-testo, sottoposti a un processo di raffinamento. Sulla base di questo set di dati, le voci corrispondenti ai testi di input e di risposta sono state generate utilizzando un modello TTS (Text-to-Speech) e utilizzate per l’apprendimento del Kanana-o. A differenza dei modelli linguistici esistenti che apprendono set di dati a due modalità, come immagine-testo o audio-testo, Kanana-o è caratterizzato dall’apprendimento della connettività e dell’interazione attraverso tre modalità: immagine-audio-testo.
Per valutare le prestazioni, è stato creato un set di valutazione trimodale, convertendo i comandi di testo dai benchmark esistenti in parlato e inserendoli insieme alle immagini, per poi valutare le risposte di testo di Kanana-o. Inoltre, attraverso un confronto con un set di dati di valutazione coreano personalizzato, è emerso che Kanana-o comprendeva le emozioni sottili contenute nel parlato coreano meglio di modelli come ‘GPT-4o’ e ‘Gemini-1.5’.
Kakao ha dichiarato che i suoi obiettivi futuri includono la risoluzione di problematiche quali l’elaborazione delle conversazioni multi-turn basate sulla voce, la struttura delle conversazioni bidirezionali tra utenti e sistema, l’espansione multilingue e una maggiore sicurezza. Kim Byeong-hak, responsabile delle prestazioni di Kanana, ha affermato: “Il modello Kanana evolverà dall’attuale intelligenza artificiale incentrata sul testo a un’intelligenza artificiale che vede, ascolta, parla ed empatizza come un essere umano, elaborando in modo completo forme complesse di informazioni”. Ha aggiunto: “Rafforzando la nostra competitività tecnologica basata sulla nostra tecnologia multimodale, intendiamo contribuire allo sviluppo dell’ecosistema nazionale dell’intelligenza artificiale attraverso la condivisione continua dei risultati della ricerca”.