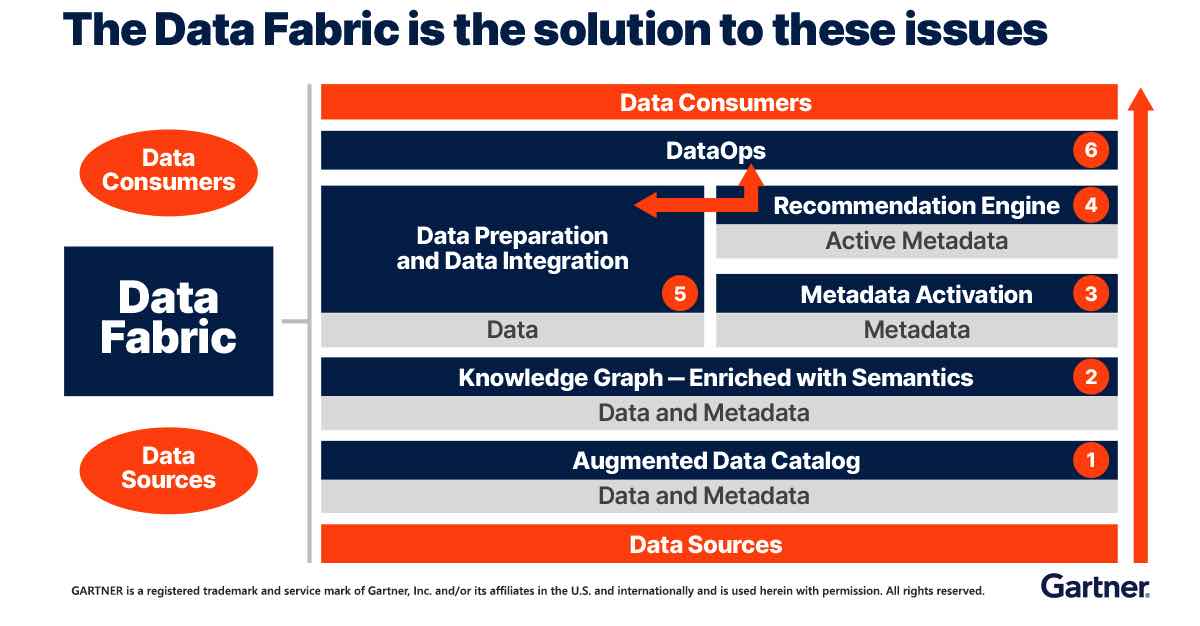
Che cos’è un data fabric? Come aiuta a organizzare dati complessi e disparati
Sommario
Quali sono alcuni tratti distintivi di un data fabric?
In che modo i principali attori si stanno avvicinando ai data fabric?
In che modo le startup e gli sfidanti stanno costruendo data fabric?
C’è qualcosa che un data fabric non può fare?
I dipartimenti IT aziendali ei data scientist al loro interno utilizzano una varietà di metafore per descrivere il modo in cui raccolgono e analizzano le informazioni, dal data warehouse al data lake e talvolta anche a un oceano di dati . Tutte le metafore catturano alcuni aspetti di come i dati vengono raccolti, archiviati ed elaborati prima di essere analizzati e presentati.
L’idea di un data fabric sottolinea come i bit possano prendere percorsi diversi che alla fine formano un insieme utile. Per estendere la metafora, seguono, collegano e uniscono fili diversi che sono intrecciati o intrecciati insieme in qualcosa che cattura ciò che sta accadendo durante l’impresa. Costruiscono un quadro più ampio.
Come riprogettare piattaforme globali per la nostra realtà multi-cloud_
La metafora è spesso usata in contrasto con altre idee come una pipeline di dati o un silo di dati. Un buon data fabric non è un singolo percorso, né è isolato. Le informazioni dovrebbero provenire da molte fonti in una rete complessa.
L’ampiezza e la complessità della rete possono essere grandi. I dati provengono da diverse fonti, forse sparse in tutto il mondo, prima di essere archiviati e analizzati da diversi computer locali. Spesso ci sono molte macchine di raccolta dati come terminali di punti vendita o sensori incorporati in una catena di montaggio. I computer locali aggregano i dati e poi trasmettono le informazioni ad altri computer che continuano l’analisi. Alla fine, i risultati vengono trasmessi come report o schermate sui dashboard utilizzati da tutti nell’azienda.
L’obiettivo della metafora è sottolineare come un prodotto completo e utile sia costruito a partire da molte fonti. Gli scienziati potrebbero finire per usare altre metafore se memorizzano le informazioni in un data lake o in un sistema di big data. Tuttavia, questa metafora di un data fabric ha lo scopo di esprimere quanto possa essere complesso e integrato il processo di raccolta dei dati.
Quali sono alcuni tratti distintivi di un data fabric?
I data scientist usano una serie di altri termini insieme al data fabric che enfatizzano anche alcune delle caratteristiche più importanti. Alcuni dei più comunemente trovati sono i seguenti:
Olistico : il data fabric aiuta un’azienda a vedere il quadro più ampio e a integrare i dettagli locali in qualcosa che aiuta l’organizzazione a capire cosa sta succedendo, non solo a livello locale ma globale.
Incentrato sui dati : i buoni leader vogliono che le loro decisioni siano guidate dai dati e un buon data fabric supporta l’utilizzo di informazioni solide per supportare il pensiero strategico e tattico.
Edge : si dice che molti dei sensori e dei punti di raccolta dati si trovino ai margini della rete, sparsi in tutta l’azienda e nel mondo in cui le informazioni vengono raccolte per la prima volta. Questo enfatizza fino a che punto arriverà il tessuto per raccogliere informazioni utili. L’edge computing stesso rappresenta uno sviluppo più ampio della tecnologia aziendale, grazie alla quale è possibile conservare e almeno inizialmente elaborare più dati in località relativamente remote in cui vengono raccolti i dati.
Metadati : gran parte del valore di una struttura integrata deriva dai metadati o dai dati sui dati. I metadati possono fornire il collante che collega le informazioni e le inferenze che possono essere fatte su identità, eventi, processi o cose individuali. La privacy e le relative preoccupazioni possono derivare dalla concentrazione di tali dati, in particolare se vengono aggregate e conservate più informazioni di quelle necessarie per scopi legittimi.
Integrazione – Gran parte del lavoro di creazione di un data fabric comporta solitamente il collegamento di diversi sistemi informatici, spesso di diversi produttori o architetti, in modo che possano scambiare e aggregare dati. Creare i percorsi di comunicazione e negoziare i diversi protocolli è una sfida per i team che lavorano sul data fabric. Molti formati e protocolli standard lo rendono possibile, ma spesso ci sono molti piccoli dettagli da negoziare per garantire che i risultati siano il più puliti e coerenti possibile.
Multicloud : i data fabric sono applicazioni naturali per il cloud computing perché spesso coinvolgono sistemi di diverse aree di un’azienda e diverse aree del globo. Non è raro che i sistemi integrino anche informazioni provenienti da diverse aziende o fonti pubbliche.
Democratizzazione : quando i dati vengono raccolti da molte fonti, diventano più ricchi poiché riflettono più sfaccettature e punti di vista. Questa prospettiva più ampia può migliorare il processo decisionale. Spesso, l’idea di democratizzazione enfatizza anche il modo in cui i report ei dashboard aggregati sono condivisi più ampiamente nell’azienda in modo che tutti i livelli dell’organizzazione possano utilizzare i dati per prendere decisioni.
Automazione : le strutture di dati in genere sostituiscono l’analisi manuale che richiederebbe agli esseri umani di raccogliere le informazioni e di eseguire gran parte dell’analisi e dell’elaborazione manualmente. L’automazione consente di lavorare con le informazioni più recenti e il più aggiornate possibile, migliorando così il processo decisionale.
Quali sono alcune sfide per la creazione di un data fabric? Molti dei maggiori problemi per gli architetti delle informazioni e dei dati riguardano l’integrazione di basso livello. Le aziende sono invase da diversi sistemi informatici creati in tempi diversi utilizzando linguaggi e standard diversi. Per questo motivo, gran parte del lavoro consiste nel trovare un modo per creare connessioni, raccogliere dati e quindi trasformarli in un formato coerente.
Una sfida concettuale è la distribuzione del carico di lavoro nella rete. I progetti possono trarre vantaggio quando parte dell’analisi viene eseguita localmente prima di essere segnalata e trasmessa. L’uso tempestivo dell’analisi e dell’aggregazione può far risparmiare tempo e costi per la larghezza di banda della rete.
Gli architetti devono anche anticipare e progettare in merito a eventuali problemi causati da guasti alle macchine e ritardi della rete. Molte strutture di dati possono includere centinaia, migliaia o addirittura milioni di parti diverse e l’intero sistema può spegnersi in attesa dei risultati di una di esse. I migliori data fabric possono rilevare gli errori, risolverli e generare comunque report e dashboard utili dai nodi di lavoro.
Tuttavia, non tutte le sfide sono tecniche. La semplice organizzazione delle varie sezioni può essere politicamente impegnativa. I manager di diverse parti dell’azienda potrebbero voler controllare i dati che producono e potrebbero non volerli condividere. Persuaderli a farlo potrebbe richiedere negoziati.
ANNUNCIO
Inoltre, quando le diverse parti del data fabric sono controllate da società diverse, potrebbe essere necessario il coinvolgimento di team legali per la negoziazione. Occasionalmente, queste diverse sezioni si trovano anche in paesi diversi con quadri normativi e regole di conformità contrastanti. Tutti questi problemi possono rendere frustrante costruire un data fabric che colleghi un’impresa globale.
Alcuni sviluppatori di data fabric creano livelli speciali di controllo o governance che stabiliscono e applicano regole sul flusso dei dati. Alcuni report e dashboard sono disponibili solo per coloro che dispongono della giusta autorizzazione. Questa infrastruttura di controllo può essere particolarmente utile quando un data fabric si estende su più aziende o organizzazioni.
Una particolare area di interesse è la privacy delle informazioni. Le organizzazioni spesso vogliono proteggere le informazioni personali dei propri membri e dipendenti. Una buona architettura di data fabric include protezione della sicurezza e della privacy per combattere la divulgazione involontaria o gli attori malintenzionati. Ultimamente, i governi hanno anche imposto norme rigorose sulle informazioni di identificazione personale (PII) e le strutture di dati devono essere in grado di gestire la conformità per tutte le regioni.
In che modo i principali attori si stanno avvicinando ai data fabric?
Le grandi società cloud sono ottimizzate per la creazione di data warehouse e laghi dalle informazioni raccolte in tutto il mondo. Sebbene non utilizzino sempre il termine “data fabric” per descrivere i propri strumenti, il loro modello di business è ideale per le aziende che desiderano creare il proprio data fabric da un’ampia raccolta dei propri strumenti. Alcuni potrebbero anche voler creare raccolte multicloud quando ha senso utilizzare il cloud per alcune parti di un sistema. Altre volte, potrebbero voler utilizzare un altro cloud per una parte diversa o, forse anche una raccolta di macchine in sede per un altro componente del sistema.
IBM offre una serie di pacchetti software per la raccolta e l’analisi dei dati che possono essere utilizzati per creare una struttura di dati di grandi dimensioni. Sono specializzati nelle grandi imprese che necessitano dell’analisi che può aiutare a gestire gruppi spesso disparati. I loro strumenti si estendono su più cloud e includono una serie di opzioni sviluppate per applicazioni più particolari. Ad esempio, alcuni data fabric includono data science da Cloud Pak for Data di IBM o modelli di intelligenza artificiale (AI) sviluppati con Watson di IBM.
Amazon Web Services (AWS) offre una serie di strumenti di raccolta e analisi dei dati che possono essere utilizzati per unire un data fabric. Offrono molti database e soluzioni di archiviazione dati in grado di supportare un data warehouse o un data lake. Offrono anche alcuni strumenti grezzi per lo studio dei dati, come Quicksight o DataBrew . Alcuni dei loro database, incluso Redshift , sono anche ottimizzati per produrre molte informazioni di base. AWS ospita anche altre società come Databricks sui propri server, offrendo molte opzioni per creare un data fabric a partire dagli strumenti di molti commercianti.
Google’s Cloud offre anche un’ampia gamma di servizi di archiviazione e analisi dei dati che possono essere integrati per creare un data warehouse o un fabric. I loro strumenti vanno da strumenti di base come Dataflow per l’organizzazione del movimento dei dati a Dataproc per l’esecuzione di strumenti open source come Apache Spark su larga scala. Google offre anche una raccolta di strumenti di intelligenza artificiale per creare e perfezionare modelli dai dati.
Il cloud Azure di Microsoft offre anche una raccolta simile di strumenti di archiviazione e analisi dei dati. I loro strumenti di intelligenza artificiale come Servizi cognitivi di Azure e Azure Machine Learning possono aiutare ad aggiungere l’intelligenza artificiale al mix. Alcuni dei loro strumenti come Azure Purview sono progettati anche per aiutare con attività pratiche di governance come il monitoraggio della provenienza o l’integrazione di più cloud oltre i confini politici e aziendali.
Oracle offre strumenti in grado di creare una struttura di dati o ciò che a volte chiamano griglia di dati. Uno di questi è Coherence , un prodotto che considerano middleware. Questo è uno strumento interrogabile che collega più database insieme, suddividendo le richieste di dati e quindi raccogliendo e aggregando i risultati.
In che modo le startup e gli sfidanti stanno costruendo data fabric?
Un certo numero di startup e aziende più piccole stanno costruendo software che possono aiutare a orchestrare il flusso di dati attraverso le imprese. Potrebbero non creare tutti i pacchetti di archiviazione e trasmissione dati, ma possono funzionare con altri prodotti che parlano standard comuni. Ad esempio, molti prodotti si basano su database SQL e gli architetti di data fabric possono scegliere tra diverse buone opzioni che possono essere ospitate in molti cloud o localmente.
Talend , ad esempio, fornisce un meccanismo per l’integrazione delle origini dati in tutta l’azienda. Il software è in grado di rilevare automaticamente le origini dati e quindi di trasferire le loro informazioni nel tessuto di reporting quando parlano le lingue standard per lo scambio di dati. Il sistema offre anche il Talend Trust Score, che tiene traccia della qualità e dell’integrità dei dati controllando eventuali lacune o anomalie che potrebbero alterare il reporting.
Astronomer offre versioni gestite di Apache Airflow open source che semplificano molti processi. L’astronomo chiama le fondamenta del loro sistema “condutture di dati come codice” perché gli architetti creano il loro tessuto specificando un numero qualsiasi di condutture di dati che collegano insieme sistemi di scienza dei dati, strumenti di analisi e filtraggio in un tessuto unificato.
Nexla suddivide il lavoro di costruzione di un data fabric in uno di collegamento dei loro Nextset, strumenti che gestiscono i compiti grezzi di organizzazione, convalida, analisi, formattazione, filtraggio ecc. Una volta che i flussi di dati sono stati specificati collegandoli insieme, il prodotto principale di Nexla controlla i flussi di dati in modo che tutti abbiano accesso ai dati di cui hanno bisogno ma non ai dati che non sono autorizzati a vedere.
Scikiq offre un prodotto che offre un livello olistico con un’interfaccia utente senza codice e trascina e rilascia per l’integrazione della raccolta dei dati. Gli strumenti di analisi includono una grande quantità di intelligenza artificiale per preparare e classificare i dati che fluiscono da più cloud.
C’è qualcosa che un data fabric non può fare?
I livelli di software che creano un data fabric si basano fortemente su strumenti di archiviazione e analisi che sono spesso considerati entità separate. Quando i sistemi di archiviazione dati parlano protocolli standard, come fanno molti di essi, i sistemi possono funzionare bene. Tuttavia, se i dati vengono archiviati in formati insoliti o i sistemi di archiviazione non sono disponibili, il data fabric non può fare molto.
Molti dei problemi fondamentali con il data fabric possono essere ricondotti a problemi con la raccolta dei dati. Se i dati sono rumorosi, intermittenti o interrotti, i report e i dashboard prodotti dal data fabric potrebbero essere vuoti o semplicemente errati. Una buona struttura di dati può rilevare alcuni problemi, filtrarli e includere avvisi con i loro rapporti, ma non possono rilevare tutti i problemi.
I data fabric si basano anche su altre librerie e strumenti per l’analisi dei dati. Anche se questi sono forniti di dati accurati, l’analisi non è sempre magica. Le routine statistiche e gli algoritmi dell’IA possono commettere errori o non generare le informazioni che speriamo di ricevere.
In generale, i pacchetti di data fabric hanno il compito di raccogliere i dati e spostarli nei diversi pacchetti software che possono analizzarli. Se i dati non sono disponibili o l’analisi non è corretta, il data fabric non è responsabile.