Nel mondo di oggi, è facile perdersi nella semantica e soprattutto per chi è nuovo nel campo dell’analisi dei dati, sembra di essere bombardato da una storia infinita di gerghi. Tra questi gerghi, i più comunemente usati e spesso confusi sono Data Science, Machine Learning e AI Deep Learning.
Secondo gli esperti
Isaac Newton ha detto “Se ho visto oltre è stando sulle spalle di Giants “. Prima di elaborare le differenze ovvie e sfumate tra questi tre campi nella sezione successiva , consentitemi di fornirvi alcuni estratti e citazioni di autori che hanno scritto libri, articoli e svolto ricerche in questi campi.
Scienza dei dati
Secondo Tom Fawcett, nel suo libro “Data Science for Business”, afferma che “la Data Science coinvolge principi, processi e tecniche per comprendere i fenomeni tramite l’analisi (automatizzata) dei dati”.
Aggiunge inoltre che “l’ingegneria e l’elaborazione dei dati sono fondamentali” e “per comprendere la scienza dei dati e il business basato sui dati è importante comprendere le differenze”.
Quindi spiega come le tecnologie di ingegneria dei dati aiutano e assistono il campo della scienza dei dati ma non devono essere confuse con le “tecnologie della scienza dei dati”.
Prende l’esempio delle tecnologie Big Data come Hadoop e MongoDB e chiarisce che si tratta di mere tecnologie di elaborazione dati per dati che sono enormi in quantità e non devono essere confusi con Data Science.
La sovrapposizione tra Data Science e ML è menzionata da Chikio Hayashi in “What is Data Science? Concetti fondamentali e un esempio euristico “in cui ha citato la Data Science come ” concetto per unificare statistiche, analisi dei dati, apprendimento automatico e metodi correlati “.
Apprendimento automatico
Ora, con un’idea di cosa sia la Data Science, capiamo cosa significa ML per gli esperti.
Il machine learning in parole molto semplici, come affermato da Aurélien Géron in “Hands-On Machine Learning with Scikit-Learn and TensorFlow” è semplicemente “la scienza (e l’arte) della programmazione dei computer in modo che possano imparare dai dati”
Potrebbe piacerti leggere in dettaglio: Cos’è l’apprendimento automatico?
In “Introduzione all’apprendimento automatico con Python”, Andreas C. Müller afferma che “[Data Science] è un campo di ricerca all’incrocio tra statistica, intelligenza artificiale e informatica ed è noto anche come analisi predittiva o apprendimento statistico”.
Una spiegazione più ingegneristica è fornita da Tom Mitchell nel suo libro ‘Machine Learning’ dove si dice che “Si dice che un programma per computer impari dall’esperienza E rispetto ad alcune classi di compiti T e misura delle prestazioni P, se le sue prestazioni a i compiti in T, misurati da P, migliorano con l’esperienza E ”.
Intelligenza artificiale (AI Deep Learning)
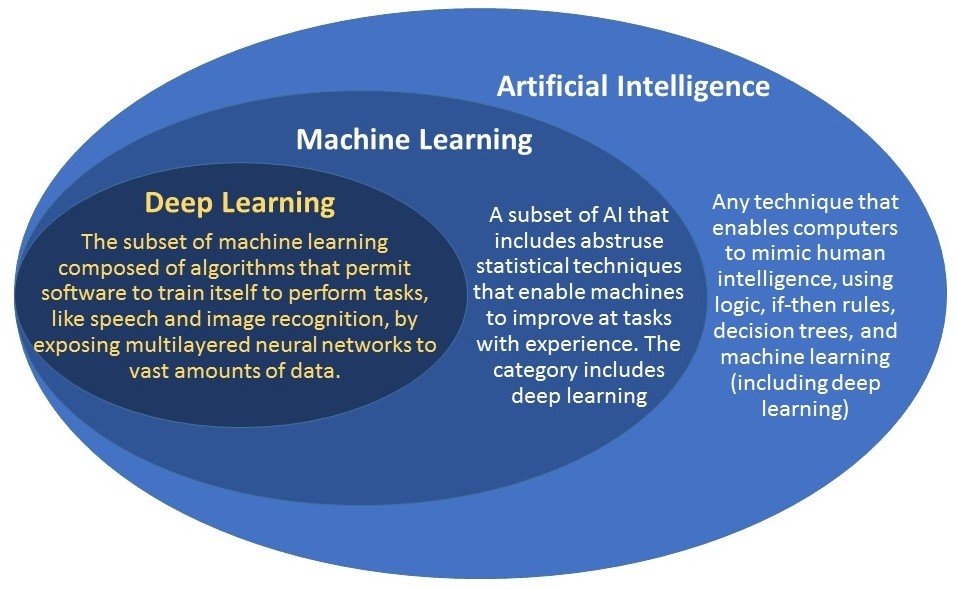
Con questo, ci ritroviamo con l’AI Deep Learning. Secondo François Chollet in “Deep Learning with Python”, si dice che l’Intelligenza Artificiale sia un “campo generale che comprende l’apprendimento automatico e l’apprendimento profondo”.
Il Deep Learning, in particolare, è indicato come un “sottocampo specifico del machine learning”. Gli estratti sopra ci hanno dato un’idea di cosa sia il ML, ma ciò che è diverso tra ML e Deep Learning è stato chiarito da lui quando spiega il significato di “Deep” in Deep Learning e spiega che il termine “Deep” in Deep Learning non lo è. una “comprensione più profonda raggiunta dall’approccio” ma si riferisce piuttosto ai “livelli successivi di rappresentazioni”.
Suggerisce sinonimi per Deep Learning come “apprendimento di rappresentazioni stratificate e apprendimento di rappresentazioni gerarchiche”. Quindi il ML è lo stesso del Deep Learning senza l’aspetto della profondità e la maggior parte degli approcci al ML hanno solo uno o due livelli di rappresentazioni e quindi sono talvolta chiamati “apprendimento superficiale”.
Nel suo libro “Deep Learning”, Goodfellow spiega la necessità di AI Deep Learning in termini di rappresentazione delle caratteristiche. Cerchiamo prima di capire cosa intendono per caratteristica. Prendono un esempio di un modello di regressione logistica che raccomanda se il paziente debba optare per un parto cesareo o meno.
Poiché i pazienti non vengono esaminati direttamente dal modello, il modello viene alimentato con informazioni importanti (esempio può essere della pressione sanguigna, se si soffre di febbre, ecc.) E “ogni informazione inclusa nella rappresentazione del paziente è nota come caratteristica “. Tuttavia, Goodfellow identifica quindi i limiti di un tale modello ML sottolineando che anche se un tale modello è in grado di correlare i vari input (caratteristiche) con i loro risultati corrispondenti, non riesce a definire correttamente queste caratteristiche.
Prende l’esempio di una scansione MRI e sottolinea che per un semplice modello ML come la Regressione logistica, una funzione come la scansione MRI non sarà di alcuna utilità in quanto “I singoli pixel in una scansione MRI hanno una correlazione trascurabile con eventuali complicazioni che potrebbero verificarsi durante il parto ”.
Quindi molti input possono essere tradotti in caratteristiche che possono essere comprese da un modello ML, ma ci sono momenti in cui gli input non possono essere tradotti ed estratti con successo ed è qui che entra in gioco il Deep Learning in quanto “risolve questo problema centrale nell’apprendimento delle rappresentazioni introducendo rappresentazioni che sono espresse in termini di altre rappresentazioni più semplici ”.
Un giorno nella vita di Data Scientist
Consideriamo che lavori per SuperAnalytica (un’azienda immaginaria di Data Science). In un progetto ti viene assegnato il compito di analizzare il funzionamento dei centri di assistenza clienti di un cliente sparsi in tutto il mondo.
Ora permettimi di accompagnarti attraverso tre giorni del tuo lavoro su questo progetto in cui il primo giorno assumi il ruolo di un esperto di ML, il secondo di un esperto di deep learning di AI e il terzo giorno vesti i panni di un data scienziato.
Primo giorno: esperto di machine learning
Inizi con l’acquisizione di dati e, una volta che i dati sono pronti, usi le tue conoscenze matematiche e statistiche per esplorare i dati e sei in grado di fornire alcune informazioni utili.
Vari modelli statistici e matematici sono in grado di fornire conoscenze come se l’età degli agenti nei centri di assistenza dipendesse dal tempo impiegato da loro per risolvere il problema o meno, ecc.
Codifichi anche molta programmazione usando le condizioni “if” e “else” e usi alcuni cicli e pensi a quante più possibilità puoi per darti intuizioni, ma ci sono ancora limitazioni a ciò che puoi immaginare e programmare.
Ad esempio, scopri che il centro ha ricevuto recensioni negative quando l’età media degli agenti era superiore a 30, i minuti impiegati per risolvere il problema di un denunciante erano più di 10 minuti e il tempo medio di attesa per il denunciante era superiore a 15 minuti.
Ora puoi codificare un programma con queste regole, ma l’afflusso di dati è perpetuo e queste condizioni possono cambiare alla luce dei dati appena aggiornati.
Inoltre, può esserci una quantità quasi infinita di parametri che è necessario considerare prima di creare queste regole, rendendo così l’analisi estremamente complicata e difficile insieme al fatto che i dati sono enormi. Qui è dove prendi l’aiuto di ML.
Ora entrano in gioco linguaggi di programmazione come Python e R ei concetti di ML come l’apprendimento supervisionato e non supervisionato diventano l’ambiente di lavoro.
Apprendimento automatico vs approccio classico
La metodologia del tuo lavoro passerà attraverso un cambio di paradigma poiché ora invece di aspettarti risposte applicando un insieme di regole (programma) ai tuoi dati, inserirai le risposte insieme ai dati in un algoritmo ML che produrrà quindi l’insieme di regole che verranno poi utilizzate per trovare le risposte. Questo è un caso tipico quando si lavora con algoritmi che funzionano nella configurazione di apprendimento supervisionato.
Tu, nel tuo progetto, avrai bisogno di dati storici ben etichettati (comunemente noti come set di dati di formazione) che avranno tutti i parametri (variabili / caratteristiche) di cui disponi attualmente.
Le etichette saranno il punteggio di soddisfazione fornito dai denuncianti. Pertanto, forniamo agli algoritmi di apprendimento supervisionato l’input disponibile e l’output corretto per tutti i punti dati e l’algoritmo ML crea una funzione di mappatura e correlazione degli input con gli output e questa funzione viene quindi utilizzata sui dati forniti per questo progetto.
In questo modo il sistema è fatto per ‘apprendere’ piuttosto che per programmare e l’attività è automatizzata e, come quando arrivano nuovi dati ben etichettati, l’algoritmo viene fatto rieseguire per aggiornare e apprendere una nuova funzione determinando la nuova struttura statistica di il set di dati di addestramento.
Un altro ambiente comune in cui funzionano gli algoritmi ML è nella configurazione di apprendimento senza supervisione in cui non sono disponibili dati di formazione.
Qui è possibile eseguire attività come identificare i diversi gruppi di centri di assistenza membri, ciascuno con un diverso insieme di caratteristiche. Un esercizio simile può essere eseguito per i vari agenti che lavorano in questi centri.
Secondo giorno: esperto di intelligenza artificiale nel deep learning
Il problema più grande di un tipico algoritmo ML è la sua mancanza di rappresentazione delle caratteristiche.
Ti vengono forniti alcuni dati extra per il tuo progetto, tuttavia, questa volta i dati non sono nel formato tipico di righe e colonne ma sono trascrizioni basate sui file audio che contengono la conversazione tra il reclamante e l’agente.
Ti vengono anche semplicemente forniti file audio senza trascrizioni e spetta a te determinare se i file audio contengono una conversazione positiva o negativa e su quale argomento.
Sulla base di queste conversazioni devi scoprire se il denunciante è stato soddisfatto o meno della risposta dell’agente, quali sono i problemi comuni affrontati dagli agenti che devono risolvere, ecc.
Qui è dove ti immergi nell’intelligenza artificiale ed entri il regno del Deep Learning.
Si utilizza il deep learning per eseguire l’elaborazione del linguaggio naturale e in particolare per l’analisi del sentiment e la segmentazione degli argomenti.
Per i file audio, è necessario creare un algoritmo di sintesi vocale. Per eseguire tutte queste attività, impari tutte queste funzionalità utilizzando modelli noti come reti neurali.
Qui usi le reti neurali artificiali e usi il set di dati di addestramento per apprendere una funzione. Tecnicamente, la configurazione in cui lavori è l’apprendimento per rinforzo in cui l’algoritmo viene “premiato” e “punito” continuamente per ridurre gli errori.
È importante ricordare che in questi due giorni si eseguono molte altre attività come la riduzione delle funzionalità tramite estrazione e selezione, la costruzione delle funzionalità tramite binning e codifica, data mining e pulizia tramite valore mancante e trattamento dei valori anomali ecc. (Tutto questo rientra nel valore complessivo dominio di Data Science!).
Terzo giorno: Data Scientist
Infine, il culmine di tutti i modelli di Data Mining, Feature Engineering, Results of Statistical, Mathematical, Machine Learning e Deep Learning ti fornisce gli ingredienti necessari per andare avanti e lavorare come Data Scientist.
È molto importante notare che per comodità non ho creato distinzioni tra il ruolo di un Data Scientist e di un Data Analyst poiché è tutto un altro dibattito con molti dei loro compiti che si sovrappongono l’un l’altro e ho incluso i compiti eseguiti da un dato analista solo sotto data scientist.
Ancora per darti un’idea, l’analista dei dati è responsabile della raccolta, elaborazione, organizzazione e estrazione dei dati, rispondendo alle domande sollevate dall’azienda ottenendo alcuni approfondimenti utilizzando strumenti statistici e di ML e infine presentandoli sotto forma di report e altri mezzi visivi.
D’altra parte, Data Scientist gestisce dati molto voluminosi ed è molto più esperto con gli algoritmi e li modifica come richiesto. Non solo risolvono le domande poste, ma escogitano approfondimenti impensati e tengono conto del business come parte del loro lavoro.
Mi piace pensare che la differenza sia quella tra un poliziotto e un detective, entrambi parte delle forze dell’ordine con alcune differenze nei loro obiettivi e nell’implementazione degli strumenti.
Tornando ora al progetto, i risultati di vari modelli forniscono le risposte come i centri responsabili delle revisioni positive e negative, i fattori maggiormente responsabili, i fattori che si influenzano a vicenda, il numero di cluster (gruppi) trovati tra i centri di assistenza, agenti ecc.
Come detto in precedenza, questi sono semplici ingredienti e li usi per approfondire il campo della Data Science.
Ora inizi veramente ad analizzare i tuoi risultati e fornire intuizioni risolvendo domande come ciò che sta accadendo nei centri di assistenza e il motivo, fai un ulteriore passo avanti e fornisci informazioni su ciò che accadrà se le cose tendono a muoversi come stanno in questo momento.
Pertanto, esegui un’analisi predittiva come l’analisi del tasso di abbandono ecc. Non solo trovi le ragioni dei problemi, ma suggerisci anche soluzioni, ad esempio, fornisci approfondimenti su quale tipo di agenti dovrebbero essere assunti, ad esempio su quali gruppi di età, qualifica accademica eccetera.
Pertanto, la Data Science non richiede solo di fornire semplici numeri e risultati utilizzando sistemi di intelligenza artificiale, ma anche di analizzare questi numeri per ottenere un quadro significativo per l’azienda: orario di lavoro medio, età media degli agenti, numero di recensioni negative per ciascuno il centro servizi non sarà di grande utilità.
Anche qui è richiesta la conoscenza del dominio, poiché a volte entrerai nella terra dell’analisi aziendale poiché, ad esempio, quando trovi diversi cluster di centri di assistenza membri, ti potrebbe essere richiesto di consigliare le possibili soluzioni per questo dove un centro ha reclami bassi e tempo medio impiegato per risolvere un reclamo dovrebbero essere consigliati di essere ricompensati e le cose fatte bene dovrebbero essere implementate nel gruppo di centri in cui i reclami e la durata del tempo per risolvere un reclamo sono alti.
Inoltre, devono essere tenuti presenti anche i bisogni, gli obiettivi e i requisiti dell’azienda, poiché forse l’azienda desidera una strategia efficace per eseguire un licenziamento e deve lasciare andare specificamente quegli agenti che sono dannosi per le prestazioni dei centri. Oltre a questi, potrebbe essere necessario fornire linee guida per il proprio team delle risorse umane su quali basi dovrebbero essere assunti gli agenti. Questi aspetti sono qualcosa di più correlato alla Data Science nel suo insieme che in particolare al Machine o al Deep Learning.
In Data Science ci si aspetta anche di avere buone capacità di generazione di report e quindi è necessario il comando di visualizzazione, riepilogo e creazione di report e strumenti come Tableau, uso di Python / R con plotly / ggplot, MS Excel, Powerpoint e un buon comando su è richiesta una lingua.
Pertanto, Data Science richiede di fornire le informazioni sul passato (cosa e perché qualcosa stava accadendo), presente (cosa e perché qualcosa sta accadendo oggi) e futuro (cosa succederà se le cose non vengono cambiate e come le cose possono essere migliorate cambiando cosa).
Richiede anche l’analisi dei dati per arrivare a domande significative, approfondimenti, risposte e suggerimenti e tutte le attività svolte al fine di raggiungere questi obiettivi nella loro totalità lo rendono una parte della Data Science in cui trovare una soluzione che richiede una combinazione di Conoscenza della ricerca tradizionale, conoscenza di matematica e statistica unita a conoscenze di software come Machine e Deep Learning ecc.
Sommario
Se in poche parole si deve spiegare la differenza tra Data Science, Machine e AI Deep Learning allora ML è dove non programmiamo in quanto tali ma forniamo al sistema l’input e la soluzione che a sua volta ci fornisce una funzione (programma) che poi può essere utilizzato per trovare nuove soluzioni. Viene generalmente utilizzato quando i problemi in questione sono molto complessi e non è possibile creare manualmente un insieme sufficiente di condizioni (regole). Quando i dati sono troppo grandi e non è possibile utilizzare modelli statistici, anche il ML è utile in quanto può gestire una grande quantità di dati senza troppi problemi. Inoltre, quando i dati / lo scenario sono dinamici e ci viene richiesto di aggiornare la nostra programmazione (condizioni / regole), anche il ML è utile in quanto automatizza la maggior parte delle attività.
Il Deep Learning si avvicina di un passo al cuore dell’intelligenza artificiale ed è ancora meno statistico e matematico rispetto al ML e viene utilizzato quando manca la rappresentazione delle caratteristiche o il problema è troppo complesso per gli algoritmi di Machine Learning. Qui ci sono più livelli nell’algoritmo con spesso ogni livello alla fine specializzato nella risoluzione di un particolare tipo di compito. È spesso una tecnica di alto livello e le attività menzionate in precedenza come Speech to Text sono per lo più svolte da un gruppo di esperti di Deep Learning ben addestrati ed esperti.
La data science è il luogo in cui otteniamo informazioni significative utilizzando i dati. Ora come Data Scientist ti potrebbe essere richiesto di utilizzare vari strumenti per raggiungere la destinazione e Machine and Deep Learning è uno di questi. L’attenzione si concentra ora sulla ricerca di problemi e sul raggiungimento di soluzioni. Un Data Scientist può persino chiedere a un esperto di ML e a un esperto di Deep Learning di fornire determinati risultati, tuttavia, sarà compito del Data Scientist utilizzare quei risultati in modo significativo, sebbene ci si aspetti che un Data Scientist sappia come farlo utilizzare in buona misura algoritmi di Machine e Deep Learning.
Data Science, Machine Learning e Deep Learning AI sono senza dubbio i temi caldi di oggi, ma è importante capire la differenza fondamentale tra loro poiché conoscere la differenza ti permetterà di scegliere il tuo percorso di carriera e gli obiettivi futuri.
La suddetta differenza graffia appena la superficie, tuttavia, sono sufficienti per darti un senso di differenziazione tra loro e un po ‘di chiarezza. Ciò ti consentirà di andare avanti in modo efficace se desideri imparare l’AI applicata e l’apprendimento automatico .