Come far sì che un sistema basato su modelli di linguaggio mantenga la rotta quando un compito si estende su molti passaggi? Le prestazioni tendono a degradare man mano che la sequenza di azioni si allunga, con errori cumulativi, deviazioni e “allucinazioni” pianificatorie che compromettono il risultato. È proprio in questo contesto che emerge EAGLET, un’architettura accademica pensata per migliorare l’efficacia degli agenti IA su compiti a lungo orizzonte—senza ricorrere a enormi dataset etichettati a mano, né a un ripensamento radicale dei modelli esecutori.
Il nucleo dell’idea è elegante: separare la pianificazione strategica dall’esecuzione concreta. Molti agenti basati su LLM (modelli di linguaggio di grandi dimensioni) operano in modo reattivo, generando il passo successivo “al buio” e correggendosi strada facendo. Questo approccio porta spesso a inefficienze, rimbalzi e errori che si accumulano. EAGLET invece introduce un “planner globale” che, prima che l’agente inizi a muoversi, delinea una mappa guida ad alto livello del percorso da seguire. In altre parole, il planner agisce come un navigatore esterno: suggerisce la rotta, ma non interviene durante l’esecuzione. Questo aiuto iniziale permette all’agente esecutore di contenere gli scostamenti e rimanere coerente con l’obiettivo originario.
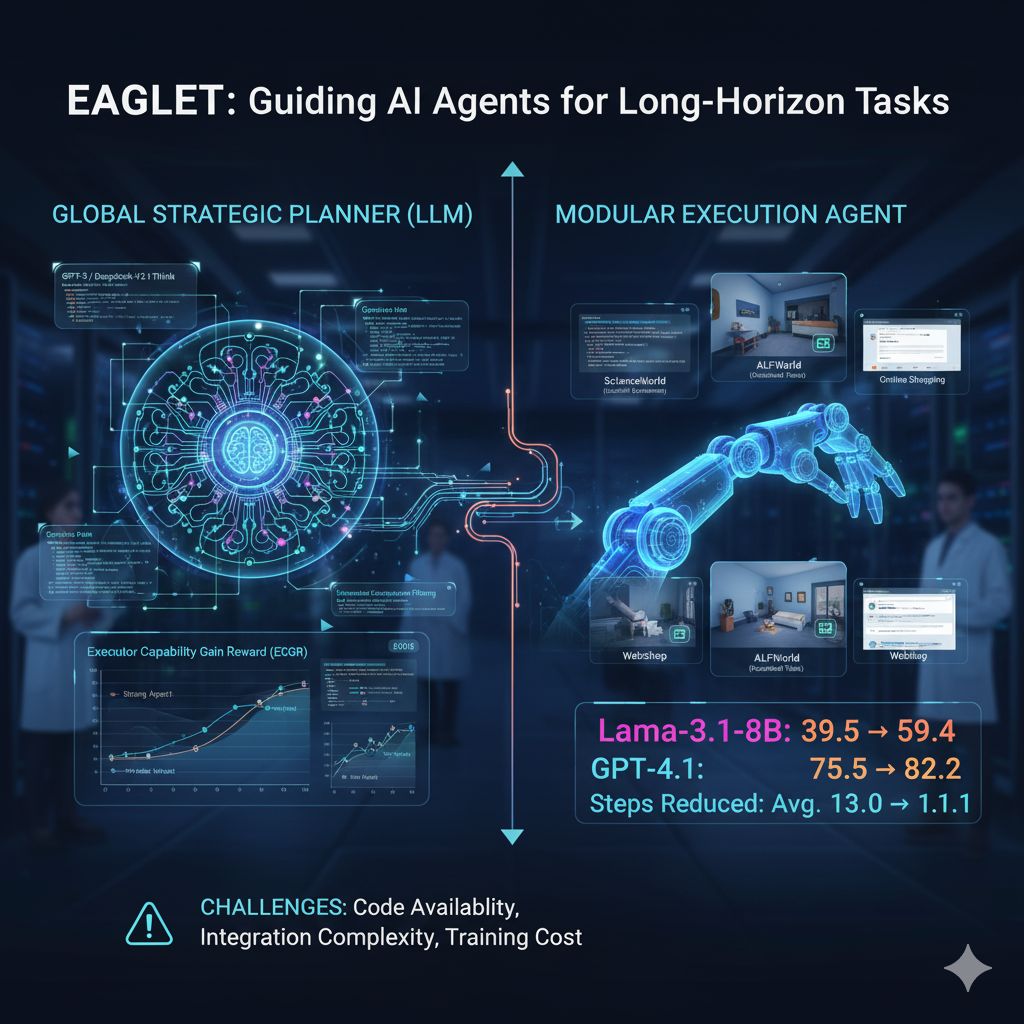
Dietro questa soluzione sta un processo di addestramento a due stadi che evita la dipendenza da annotazioni manuali. Nella prima fase si generano piani sintetici usando modelli molto potenti (come GPT-5 o DeepSeek-V3.1-Think), piani che vengono poi filtrati tramite un metodo chiamato homologous consensus filtering. Tale metodo conserva solo i piani che mostrano di migliorare le prestazioni sia per agenti esperti sia per agenti meno capaci, scartando quelli che funzionano soltanto in contesti ideali. In un secondo momento, un meccanismo basato su regole simile al reinforcement learning raffina ulteriormente il planner, usando una funzione di ricompensa progettata ad hoc. In particolare, l’innovazione principale è il concetto di Executor Capability Gain Reward (ECGR): si misura quanto un piano generato aiuti sia agenti forte che agenti debole a completare il compito con meno errori e in meno passi. Tale ricompensa ha anche un termine decrescente che penalizza traiettorie troppo lunghe, garantendo che il planner non produca itinerari tediosi.
Il bello di EAGLET è la sua natura modulare: può essere integrato in pipeline esistenti, senza bisogno di riaddestrare l’agente esecutore. I test mostrano miglioramenti su modelli come GPT-4.1, GPT-5, Llama-3.1 e Qwen2.5, in combinazione con vari stili di prompting (ReAct, Reflexion e altri). Le prove sperimentali sono state condotte su benchmark noti per i compiti a lungo orizzonte: ScienceWorld, che simula esperimenti scientifici testuali; ALFWorld, con attività domestiche descritte in linguaggio naturale in ambienti simulati; e WebShop, incentrato su comportamenti guidati da obiettivi all’interno di interfacce di shopping online. In tutti questi scenari, gli agenti assistiti da EAGLET hanno superato le prestazioni degli agenti “puri” e anche altri approcci basati su pianificazione (come MPO o KnowAgent). Per esempio, usando Llama-3.1-8B-Instruct, la performance media è salita da 39,5 a 59,4, un netto salto. In ALFWorld, per scenari già noti il miglioramento è stato addirittura più che doppio, da 22,9 a 54,3. E persino su modelli già molto forti, il guadagno è apprezzabile: GPT-4.1 ha fatto un salto da 75,5 a 82,2, mentre GPT-5 è passato da 84,5 a 88,1.
Un vantaggio secondario, ma non meno importante, è che gli agenti con EAGLET finiscono i compiti in meno passi. Con GPT-4.1, il conteggio medio delle mosse è sceso da 13,0 a 11,1; con GPT-5, da 11,4 a 9,4. Questo significa non solo risultati migliori, ma anche risparmio di calcolo, di latenza e di costi in ambienti di produzione. Paragonato a metodi RL intensivi come GiGPO (che possono richiedere centinaia di iterazioni), EAGLET ottiene risultati comparabili o superiori con circa un ottavo dello sforzo di addestramento.
Tuttavia, non tutto è ancora definito. Al momento della pubblicazione dello studio su arXiv, il codice di EAGLET non è reso pubblico, e non è chiaro se e quando lo sarà, né con che licenza o con quale supporto. Questa assenza può rallentare l’adozione nelle aziende. Resta anche da vedere quanto sia facile integrarlo in framework popolari come LangChain o AutoGen: se l’interfaccia è troppo rigida o richiede componenti custom, molte squadre potrebbero esser riluttanti. In più, il training stesso richiede più agenti “esecutori” per valutare i piani generati — una condizione che non tutte le aziende possono soddisfare, specie se dispongono di risorse limitate o modelli costosi. Un’altra incognita riguarda la scala minima: si potrà applicare EAGLET con modelli sotto i 10 miliardi di parametri in scenari sensibili alla latenza? E quale sarà il modo più efficace di usarlo nella pratica: generare i piani offline per task noti, o far sì che il planner lavori in loop in tempo reale durante l’esecuzione? Ogni scelta comporta compromessi in termini di costo, latenze e complessità operativa.
Per i team tecnici in medio-grandi organizzazioni, EAGLET rappresenta un interessante prototipo: un possibile modello da adottare quando si desidera migliorare l’affidabilità e l’efficienza degli agenti, specialmente in ambiti in cui il ragionamento a più passi è inevitabile — pensiamo all’automazione IT, al supporto clienti complesso o alle interazioni web basate su obiettivi. Il fatto che possa guidare sia modelli open sia modelli closed source e che il training sia parzialmente autonomo lo rende un punto di partenza appetibile per chi vuole potenziare i propri agenti con un investimento relativamente misurato. Ma fino a quando non saranno messi a disposizione strumenti, librerie e linee guida pronte all’uso, molte aziende dovranno decidere se “costruire da sé” o “aspettare la maturità del framework”.