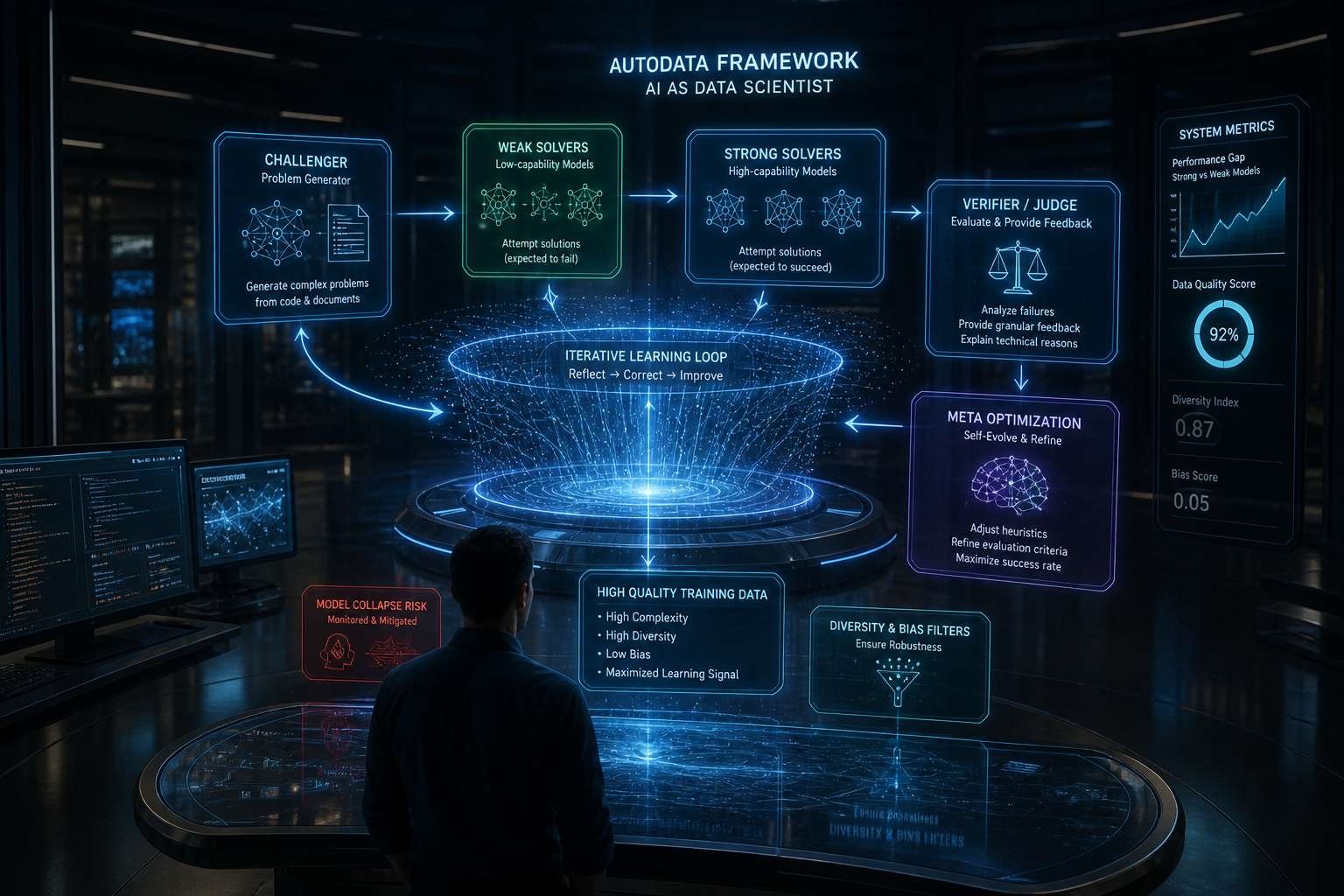
Il raggiungimento del plateau nel volume di dati testuali disponibili sul web ha spostato il focus dell’ingegneria del software verso la qualità e la densità informativa dei dataset. Meta ha risposto a questa sfida presentando “AutoData”, un framework che trasforma l’intelligenza artificiale in un data scientist autonomo capace di generare, validare e raffinare i propri dati di addestramento. A differenza dei metodi tradizionali di generazione di dati sintetici, che operano spesso in un unico passaggio lineare (one-shot), AutoData introduce un ciclo di apprendimento iterativo in cui il modello riflette e corregge i propri output, dimostrando che l’allocazione di una maggiore potenza di calcolo durante la fase di inferenza è direttamente proporzionale alla qualità dei dati prodotti per le fasi successive di addestramento.
L’implementazione tecnica di questo sistema si basa sul concetto di “Agentic Self-Instruct”, una struttura multicomponente in cui un modello principale coordina l’attività di diversi sub-agenti specializzati. Il cuore operativo del processo vede il “Challenger” impegnato nella formulazione di problemi complessi derivati da codice o documenti tecnici, i quali vengono poi sottoposti a due diverse classi di risolutori: i “Weak Solvers” e gli “Strong Solvers”. L’obiettivo fondamentale di questa dinamica è la creazione di un differenziale prestazionale significativo: il sistema cerca di generare dati che risultino inaccessibili ai modelli con scarse capacità di problem solving ma risolvibili da quelli più avanzati. Questo processo è supervisionato da un “Verifier” o “Judge”, un agente critico che analizza i fallimenti delle soluzioni proposte e fornisce un feedback granulare al generatore, spiegando le ragioni tecniche del mancato successo e permettendo una ricalibrazione immediata della strategia di generazione.
Un elemento di innovazione radicale all’interno di questo stack è la “Meta Ottimizzazione”, un processo di auto-evoluzione in cui l’agente non si limita a produrre dati, ma modifica attivamente le proprie euristiche di generazione e i criteri di valutazione. Questo approccio permette all’IA di emulare il pensiero strategico di un esperto umano, raffinando i parametri di validazione per massimizzare il tasso di successo dei campioni generati. I risultati sperimentali indicano che questo metodo amplia il divario di prestazioni tra modelli forti e deboli, producendo dati di addestramento molto più complessi e stratificati rispetto a quelli ottenuti con i metodi convenzionali, dove la distinzione tra le diverse capacità dei risolutori rimaneva spesso marginale.
Tuttavia, l’automazione totale del ciclo dei dati introduce sfide tecniche non trascurabili, in particolare il rischio di “collasso del modello” (model collapse), un fenomeno degenerativo che si verifica quando un’IA viene addestrata esclusivamente su dati sintetici perdendo progressivamente varietà e accuratezza. Per contrastare questa tendenza e i “comportamenti di aggiramento” osservati negli agenti — tendenze del software a eludere le regole per raggiungere l’obiettivo con il minimo sforzo — Meta ha integrato protocolli di misurazione quantitativa della diversità e sistemi di filtraggio dei bias. Questi meccanismi assicurano che i dati generati non siano solo tecnicamente corretti, ma anche distribuiti in modo eterogeneo, evitando un’eccessiva dipendenza da casi specifici o pattern ripetitivi che potrebbero compromettere la capacità di generalizzazione del modello finale.