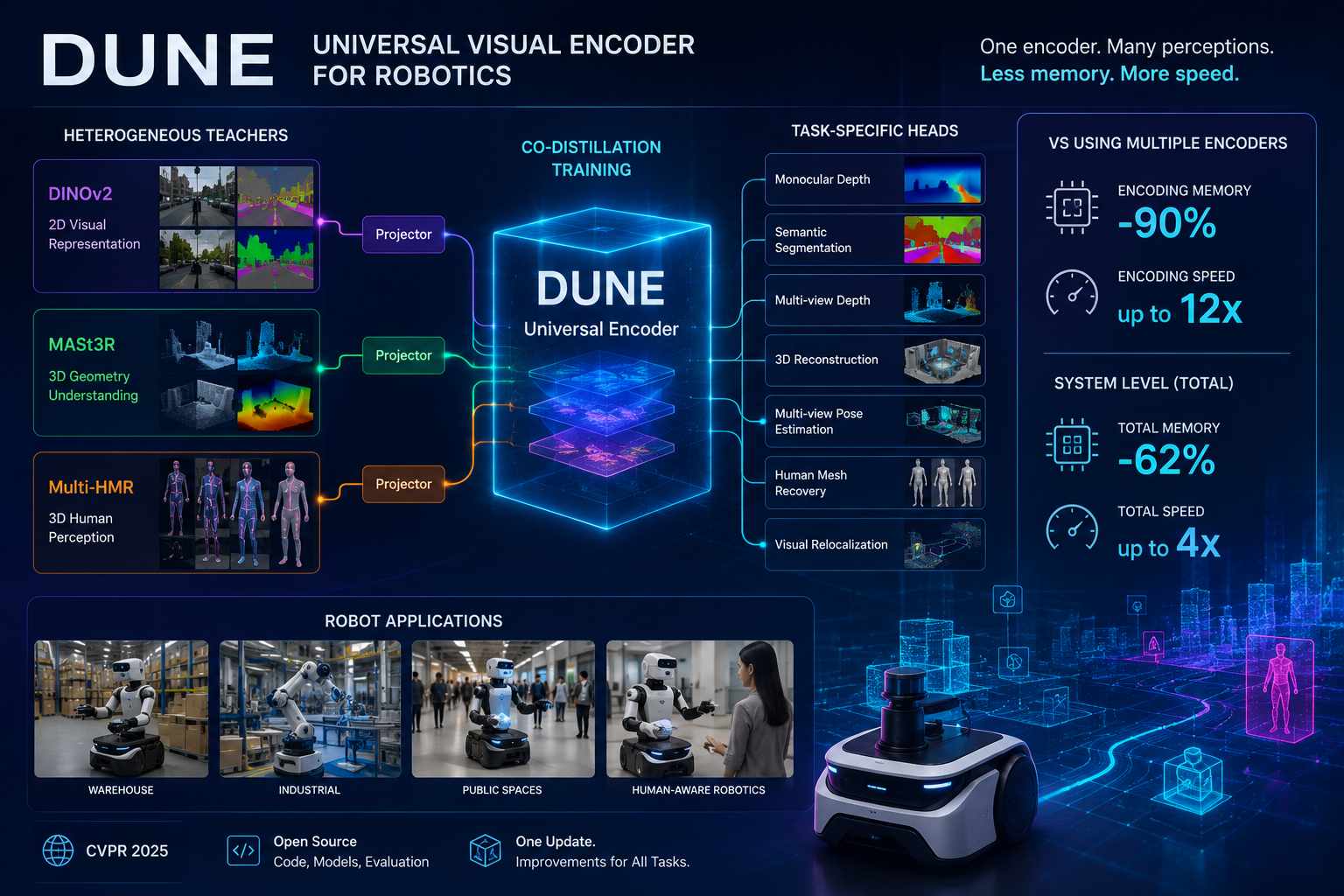
Naver Labs Europe ha presentato DUNE, acronimo di Distilling a Universal Encoder from Heterogeneous 2D and 3D Teachers, un encoder visivo universale progettato per sostituire più modelli di percezione usati contemporaneamente dai robot autonomi. Il sistema concentra in una singola rete le rappresentazioni necessarie per attività di visione 2D, comprensione tridimensionale e percezione delle persone, riducendo la duplicazione di elaborazioni che normalmente grava su memoria e capacità di calcolo a bordo macchina.
Nei robot mobili e nei sistemi autonomi, le immagini raccolte da telecamere e altri sensori vengono spesso inviate a più encoder distinti. Un modello può essere dedicato alla segmentazione semantica della scena, uno alla stima della profondità, uno alla ricostruzione 3D, uno alla localizzazione del robot e un altro al rilevamento o alla ricostruzione del corpo umano. Poiché questi modelli ricevono in molti casi gli stessi frame o dati visivi iniziali, una parte rilevante delle operazioni viene ripetuta più volte, con consumo di memoria, bandwidth e tempo di inferenza.
DUNE affronta questo problema usando una strategia di multi-teacher distillation. In fase di addestramento, un solo modello studente viene supervisionato da tre modelli insegnanti con competenze diverse: DINOv2 per la rappresentazione visiva generalista e le attività 2D, MASt3R per la comprensione geometrica e la ricostruzione 3D, Multi-HMR per la percezione tridimensionale delle persone. L’encoder finale non replica semplicemente gli output di un unico modello più grande, ma apprende a produrre rappresentazioni compatibili con domini e compiti che normalmente richiederebbero architetture separate.
La difficoltà tecnica risiede proprio nell’eterogeneità degli insegnanti. DINOv2, MASt3R e Multi-HMR sono stati progettati per obiettivi differenti e addestrati su distribuzioni di dati diverse. Naver Labs Europe definisce questo approccio heterogeneous teacher distillation o co-distillation: l’encoder studente deve mantenere informazioni utili sia per la percezione semantica dell’immagine sia per relazioni geometriche tra viste, profondità, pose e ricostruzione della figura umana. Per farlo, il processo usa proiettori specifici per ciascun teacher e dataset appartenenti ai diversi domini visivi, invece di un singolo set di immagini generiche.
DUNE può quindi essere collegato a teste specializzate per compiti downstream senza dover eseguire più backbone completi in parallelo. Le applicazioni valutate includono profondità monoculare, segmentazione semantica, stima della profondità multi-view, ricostruzione 3D, regressione della posa da più immagini, recupero della mesh umana e visual relocalization senza mappa preesistente. In quest’ultimo caso, Naver Labs Europe riporta che MASt3R dotato dell’encoder DUNE supera il modello MASt3R originale pur utilizzando un encoder più compatto.
Nei test riportati per l’uso robotico, la sostituzione di più encoder con DUNE ha ridotto fino al 90% la memoria dedicata alla fase di encoding e ha incrementato fino a dodici volte la velocità di questa elaborazione. Considerando il sistema complessivo, inclusi gli altri componenti necessari alle pipeline di percezione, il consumo totale di memoria del robot è diminuito di circa il 62%, mentre la velocità di elaborazione è aumentata fino a quattro volte.
Il vantaggio non riguarda soltanto il risparmio di risorse hardware. Quando un robot deve riconoscere ambienti, persone e ostacoli, stimare geometrie, localizzarsi e reagire in tempo reale, ridurre il numero di modelli eseguiti sullo stesso input può diminuire la latenza tra acquisizione del frame e decisione. Questo è particolarmente rilevante nei contesti condivisi con persone, come edifici, magazzini, spazi pubblici e impianti industriali, dove la percezione deve essere aggiornata rapidamente senza dipendere da server remoti o da GPU di grandi dimensioni.
DUNE è stato pubblicato da Naver Labs Europe al CVPR 2025 e il codice, i modelli preaddestrati e le istruzioni di valutazione sono disponibili pubblicamente. L’uso previsto è quello di un encoder riutilizzabile, sul quale sviluppatori e ricercatori possono collegare decoder o head specifici per il proprio compito, mantenendo congelata la rappresentazione visiva di base. In questo modo un aggiornamento dell’encoder universale può propagare miglioramenti a più funzioni robotiche senza richiedere la sostituzione indipendente di ogni modello di percezione.