Nell’universo dell’intelligenza artificiale, un’idea che comincia a guadagnare spazio è quella di far evolvere i grandi modelli linguistici (LLM, Large Language Models) da strumenti passivi di dialogo a agenti autonomi di ricerca — entità in grado non solo di conversare ma di formulare strategie, navigare risorse web, correggersi da sole e orchestrare flussi complessi di ragionamento. Ma una barriera concreta in questo cammino è il costo: affidarsi a API esterne (di motori di ricerca, knowledge base o servizi proprietari) per arricchire il modello è oneroso, e spesso strutturalmente vincolante.
Proprio qui entra in gioco il contributo più rilevante del lavoro di Alibaba: una metodologia che consente di generare dati “interni” per l’addestramento — senza collegate chiamate API — tramite tecniche di sintesi dati offline. L’idea non è solo elegante: è potenzialmente rivoluzionaria per le aziende che vogliono costruire i propri agenti intelligenti mantenendo controllo, privacy e costi contenuti.
Il punto di partenza del ragionamento è la constatazione che, evolvendo da chatbot a agenti autonomi, serve un cambio di paradigma: non basta che l’IA sappia rispondere bene a una richiesta. Deve anche imparare a pianificare, a decidere quando usare uno strumento, e soprattutto ad adattarsi quando qualcosa non va come previsto.
Gli autori del progetto parlano di agentic alignment: non più solo “allineamento” delle risposte a preferenze umane, ma coerenza del comportamento dell’agente nel tempo, in scenari complessi. In ambienti dinamici (es. pagine web che cambiano, dati che si aggiornano, errori di rete), l’agente deve essere resiliente: saper cambiare percorso, verificare fonti alternative, essere prudente quando i segnali sono deboli. Deep research agent è dunque l’agente capace di fare ricerca web, eseguire codice, navigare, incrociare fonti — non come attività puntuale, ma come flusso complessivo.
Finora, gli approcci comuni (supervised fine-tuning, reinforcement learning) si sono dimostrati parzialmente efficaci, ma limitati: spesso insegnano il modello a “ripetere comportamenti noti”, piuttosto che ad “apprendere la strategia del ragionamento”, soprattutto se il modello di base non è predisposto ad agire in ambienti complessi.
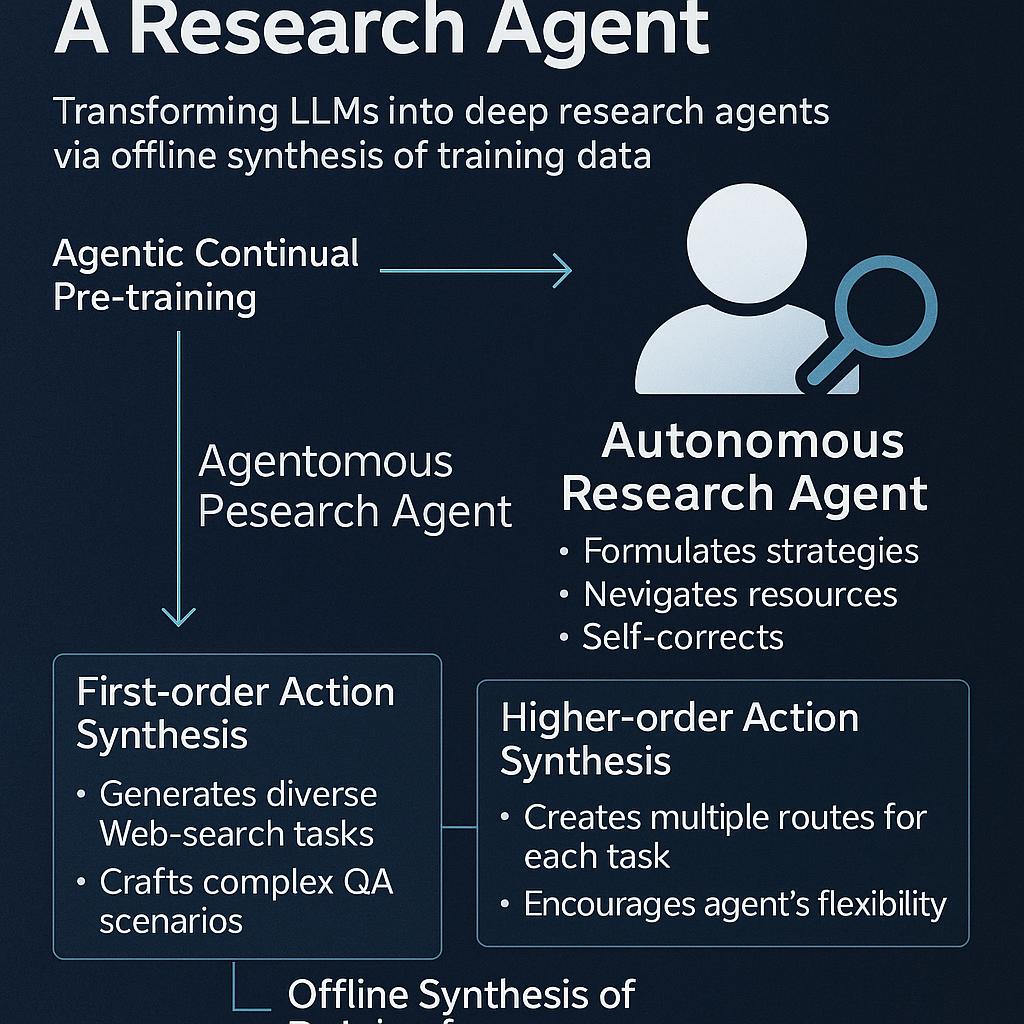
Per evitare che la fase di “messa a punto” debba trasmettere interamente da zero la capacità agentica, il team di Alibaba propone Agentic Continual Pre-training (Agentic CPT) come un livello intermedio: un modello già “pre-allineato” con comportamenti agentici prima ancora che entri la fase di fine-tuning specifico.
Due principi guidano questo approccio:
- Ampiezza dei dati: la sorgente dei dati non deve essere limitata a un singolo dominio, ma coprire molti tipi di compiti — navigazione, ragionamento, recupero, trasformazione delle informazioni.
- Varietà comportamentale: non insegnare una singola “strada giusta”, ma stimolare il modello a esplorare alternative, a non rigidificarsi in comportamenti statici.
In pratica, Agentic CPT inserisce una fase addizionale intermedia (tra il pretraining “base” e il fine-tuning applicativo) in due stadi: prima, il modello elabora una grande mole di dati agentici (circa 200 miliardi di token) con una finestra di contesto estesa; poi, in un secondo stadio, si raffina con altri 100 miliardi di token e contesto ancora più ampio, enfatizzando la capacità di pianificazione a lungo termine e di gestione di spazi di azione complessi.
Il pezzo forte della proposta è la tecnica di sintesi dati offline, cioè generare i dati di addestramento necessari senza dover attingere a system calls esterne o servizi di terze parti. Questo viene implementato attraverso due meccanismi principali:
- First-order Action Synthesis (FAS): prende dati grezzi da fonti varie, li ristruttura in una “memoria open-world” e genera scenari complessi di domanda-risposta che coinvolgono operazioni multiple (recupero, ragionamento, trasformazione).
- Higher-order Action Synthesis (HAS): invece di limitarsi a fornire un’unica traiettoria “corretta”, questa tecnica genera molteplici percorsi alternativi per un dato compito. In questo modo, il modello impara una strategia flessibile, non semplicemente a imitare.
Entrambe le fasi avvengono offline, cioè senza nessun costo legato alle API esterne — un elemento cruciale per renderle scalabili e accessibili anche a organizzazioni con risorse limitate.
Il risultato della sperimentazione è AgentFounder, basato su Qwen3-30B come modello di partenza. Dopo il percorso di Agentic CPT e la successiva personalizzazione, si è dimostrato superiore (secondo i benchmark scelti) a molti agenti open-source esistenti, con prestazioni avvicinabili a modelli chiusi e proprietari.
In alcuni benchmark generali (come BrowseComp), AgentFounder-30B batte di 10 punti percentuali il precedente modello open-source top, raccorciando il divario con le soluzioni chiuse. In benchmark accademici e specialistici (Humanity’s Last Exam, Academic Browse), mostra solidità e capacità superiori ai concorrenti open, diventando una valida “spina dorsale” per applicazioni di ricerca avanzata.
Per un’impresa, queste prestazioni si traducono in benefici concreti: più stabilità, accuratezza e azionabilità su compiti “a lungo orizzonte” (es. analisi di mercato, monitoraggio competitivo, aggregazione multi-fonte). Pur così, il team suggerisce che in contesti ad alto rischio si mantenga sempre un “humain-in-the-loop” per validazione nei punti critici.
Uno degli aspetti più interessanti è che l’intero percorso — da modello generico a agente di ricerca specializzato — può avvenire on-premise, con dati interni all’azienda e controllo totale. Le imprese possono costruire agenti su misura (finanza, chimica, sanità, etc.) a costi ragionevoli e tempi contenuti, grazie a un modello “pre-allineato” come base, su cui effettuare un adattamento leggero sui propri dati.
L’approccio di Alibaba è promettente, ma non privo di sfide. La qualità della sintesi dati offline ha un ruolo cruciale: se i dati “inventati” non catturano la varietà reale dei casi d’uso, il modello può restare parziale o predisposto a errori. Più ancora, la generazione off-line richiede algoritmi sofisticati per garantire coerenza, varietà, non contraddittorietà e capacità di ragionamento genuino.
Inoltre, l’equilibrio tra esplorazione (ossia permettere all’agente di “tentare strade nuove”) e affidabilità è delicato: troppa esplorazione può generare comportamenti erratici, troppo rigore può rendere l’agente troppo conservativo. Il “self-correction”, le strategie di fallback, la capacità di riconoscere l’incertezza sono elementi centrali e complessi da modellare in modo robusto.
Alibaba non propone soltanto un modello nuovo, ma forse una visione: agenti di ricerca che non “usano” il mondo come fonte esterna, ma imparano autonomamente a immaginarlo, ragionarlo e maneggiarlo internamente — avvicinando l’autonomia dell’IA alla fattibilità pratica per le imprese.